IKEA is a renowned furniture design company specializing in flat-packed furniture, kitchen appliances, and home accessories. The company's name, IKEA, is derived from the initials of its founder, Ingvar Kamprad, and the places that influenced his upbringing. IKEA's vision is to enhance everyday life for many people through its products. Their commitment extends beyond home furnishing to positively impact communities and promote sustainability for customers' lives at home. In this blog we will help to analyze IKEA products and predict prices with linear regression.
IKEA continuously challenges themselves and others to achieve more with less, all while maintaining a high quality of Ikea products. They strive to uncover and eliminate unnecessary costs daily, as low prices are only possible through efficient cost management. According to IKEA's financial reports from 2017 to 2022, there has been a fluctuation in customer website visits for Ikea products. The e-commerce data collection services analyzed that the numbers experienced a rise in 2020, reaching a peak in 2021. However, in 2022, the number of customer website visits declined, nearly decreasing by half a million.
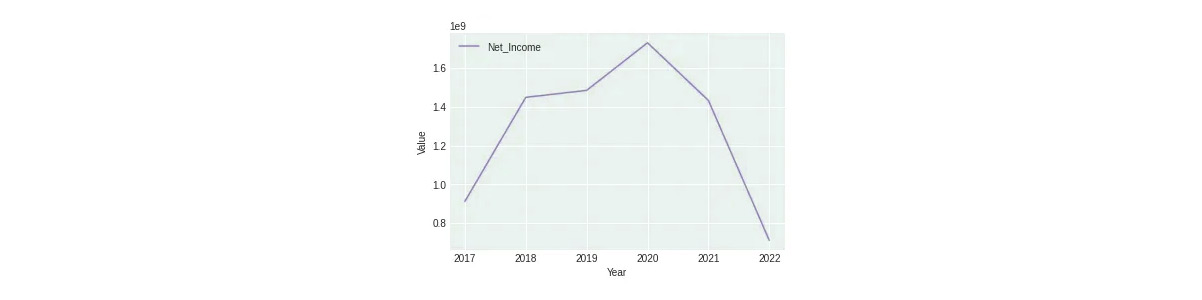
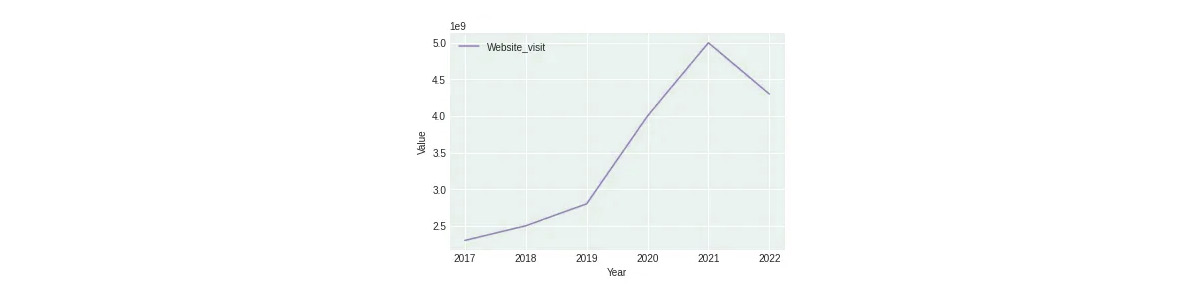
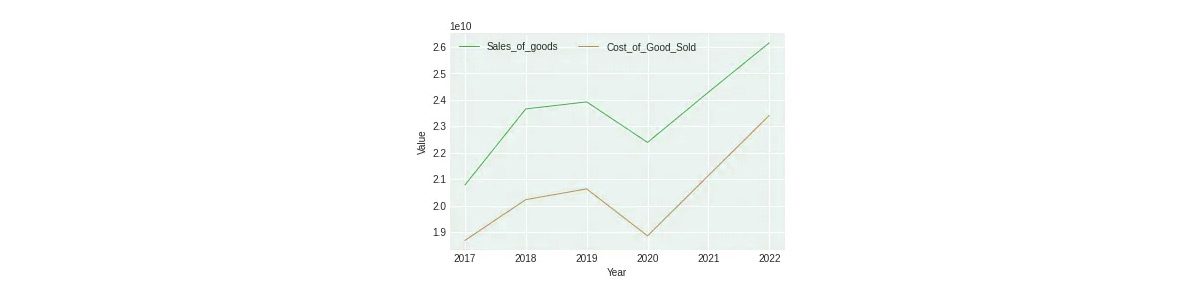
Despite experiencing the peak number of customer website visits in 2021, IKEA's net income was lower compared to 2020. As per IKEA product data scraping services it could be attributed to a shift in customer preferences as some countries recovered from COVID-19, leading to a preference for offline shopping. It is evident in the third Figure, which shows an increase in Sales of Goods in 2021.
The trend for Sales of Goods from 2017 to 2022 showed that of the Cost of Goods Sold. Over the years, the gap between the two lines has narrowed, indicating a consistent increase in the Cost of Goods Sold annually.
In 2022, IKEA's operational costs peaked due to the expansion of its business, including the opening of new offline stores. However, the decline in IKEA's net income impacts by the consequences of the war in Ukraine. As a result, IKEA decided to scale down its stores in Russia and Belarus, incurring one-time costs related to writing down assets and provisioning costs. This situation highlights the importance of analyzing IKEA products and predicting prices with linear regression to make informed business decisions and mitigate financial risks.
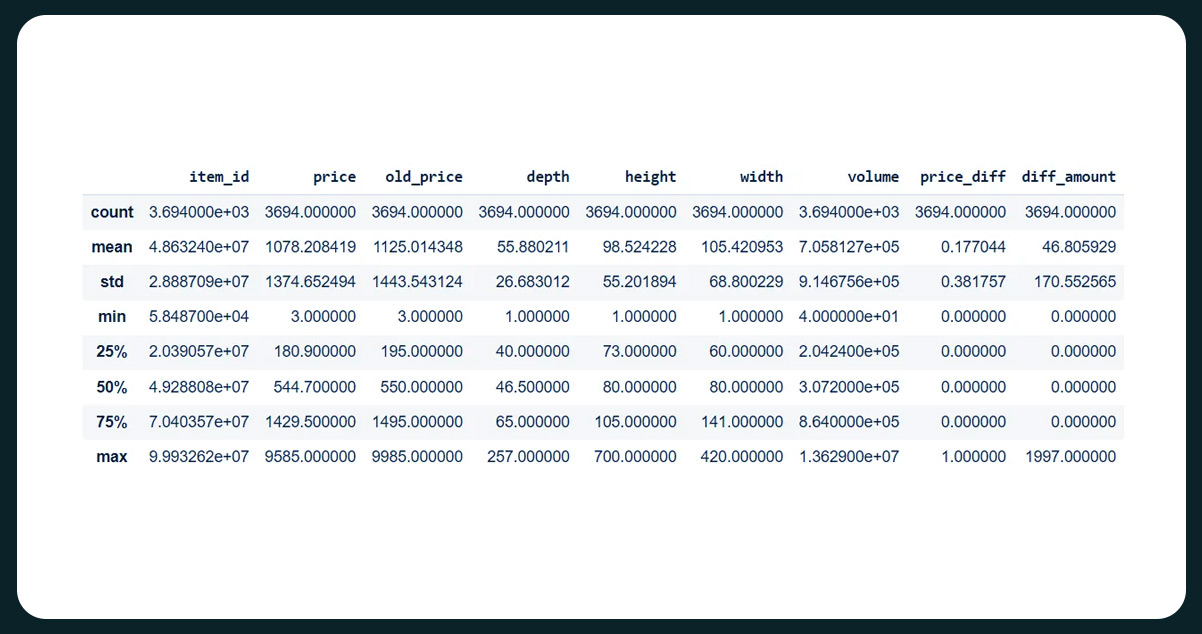
The dataset comprises 14 columns and 3694 rows of data:
Import Libraries
To scrape IKEA products and predict prices i nstall and import the necessary libraries for the project:
![Product-Analysis-[Exploratory-Data-Analysis]-and-Product-Price-Prediction-using-Linear-Regression](img\blog\analyze-ikea-products-and-predict-prices\Product-Analysis-[Exploratory-Data-Analysis]-and-Product-Price-Prediction-using-Linear-Regression.jpg)
Dataset Loading

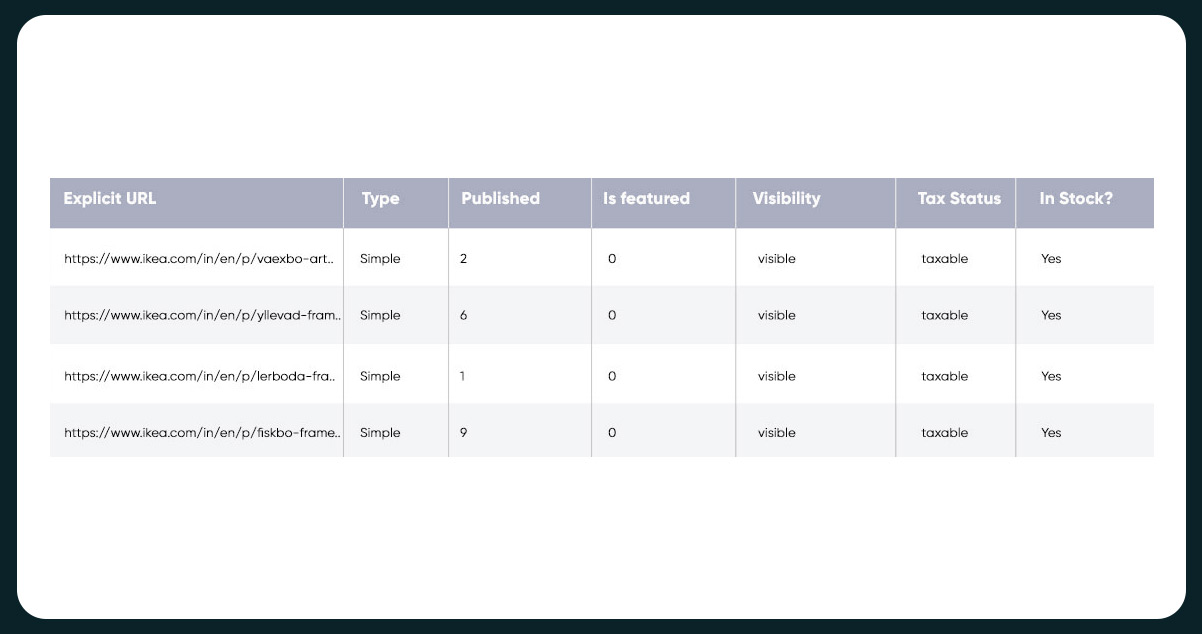

Data Cleaning and Manipulation
One column named "Unnamed: 0" does not hold any meaningful information and seems redundant with the index. We can drop this column. Additionally, we need to check for any null and duplicated values in the dataset.
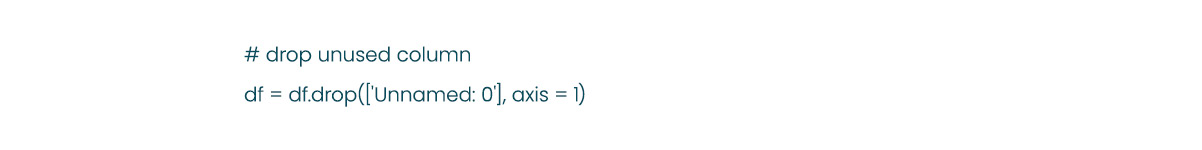


Upon inspection, there are no duplicated values in our dataset. However, we have observed null values in the dimension columns, with varying amounts of missing data. We can fill the null values with the average or median values for each dimension from products within the same category to address this. This approach will help ensure the missing data is imputed appropriately and maintain consistency within each product category.



Now that we have filled the null values in our dimension columns, we can drop the "Median" column from our data frame.


The "old_price" column currently has the wrong datatype, represented as an object or string. We will convert it from a string to a float datatype to facilitate further analysis, aligning it with the "price" column.

In the "old_price" column, there are two types of values: "No old price" and prices displayed as "SR 0,000." For rows where the value is "No old price," we can fill it with the corresponding "price" value, assuming that the product is newly released and does not have an old price.



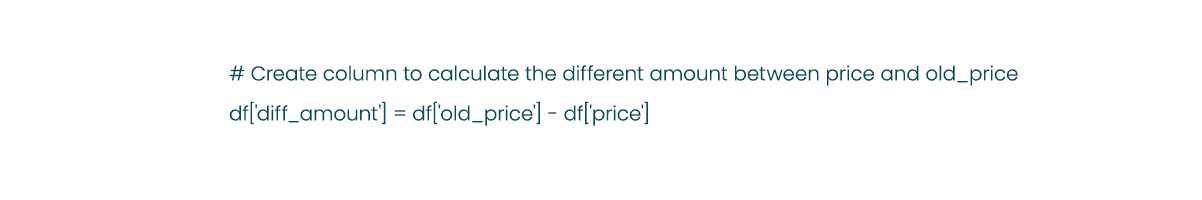


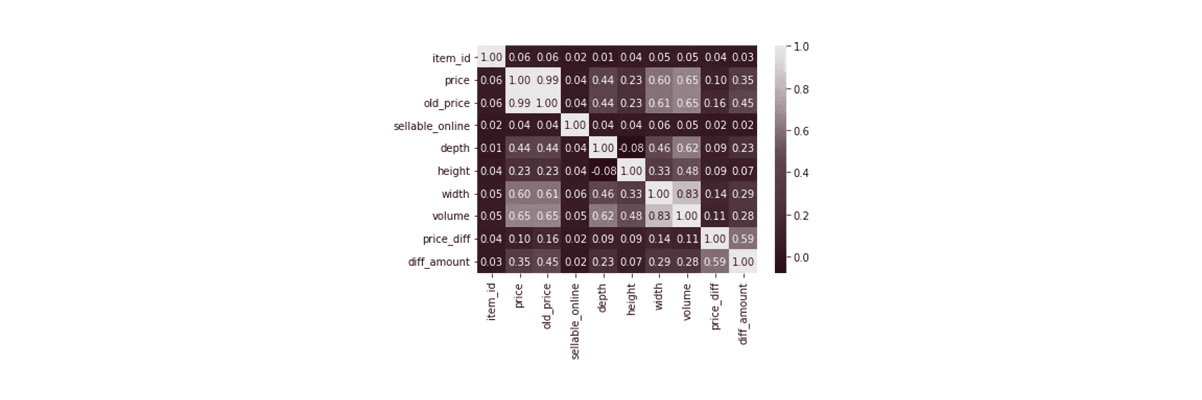
The "width" dimension unit exhibits a higher correlation with both "price" and "old_price" compared to the other two dimension units, "depth" and "height." Additionally, "price" and "old_price" show a strong correlation with each other and are also significantly correlated with the "price_diff" variable.
Among the three types of product dimensions, "volume" has the highest correlation with "width," followed by "depth," and then "height." Furthermore, "volume" also shows correlations with both "price" and "old_price."
We will drop some columns from our dataset to avoid multicollinearity in our modeling process.

Exploratory Data Analysis (EDA)
.jpg)
-2.jpg)
All distribution plots for product dimensions and price [fig. 7–11] exhibit a right-skewed pattern, indicating that the mean value is greater than the median value for each feature. Products with lower prices and smaller sizes predominantly dominate the plots. This skewness in the data distribution suggests that most products have relatively lower prices and dimensions.
Top Product Category by Production Volume

"Product Category Production Analysis: Tables and Desks Dominate with Over 600 Different Products, Followed by Bookcases and Shelving Units, and Chairs. Room Dividers Have the Least Production, Likely Due to Lower Customer Demand Compared to the Top 3 Categories."
Comparing Products: Price, Colors, and Online Availability
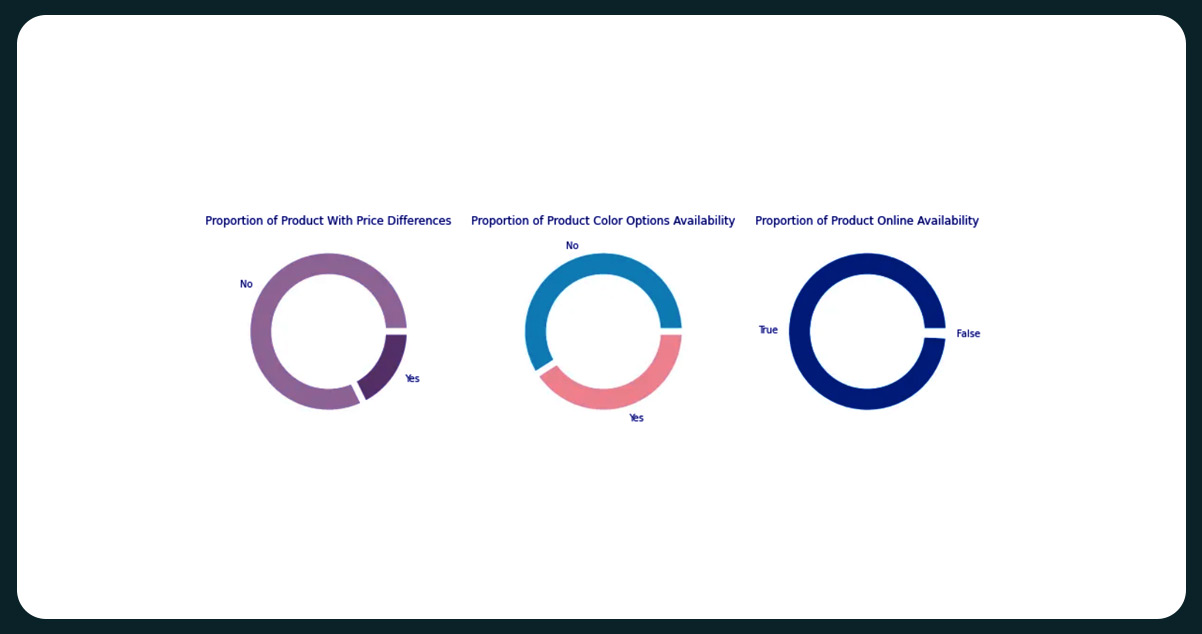
Product Price Comparison: Majority Have No Price Difference or No Old Price, Indicating Frequent New Product Launches to Attract Customers. Color Options and Online Availability are Nearly Equally Distributed, with Most Products Available Online.
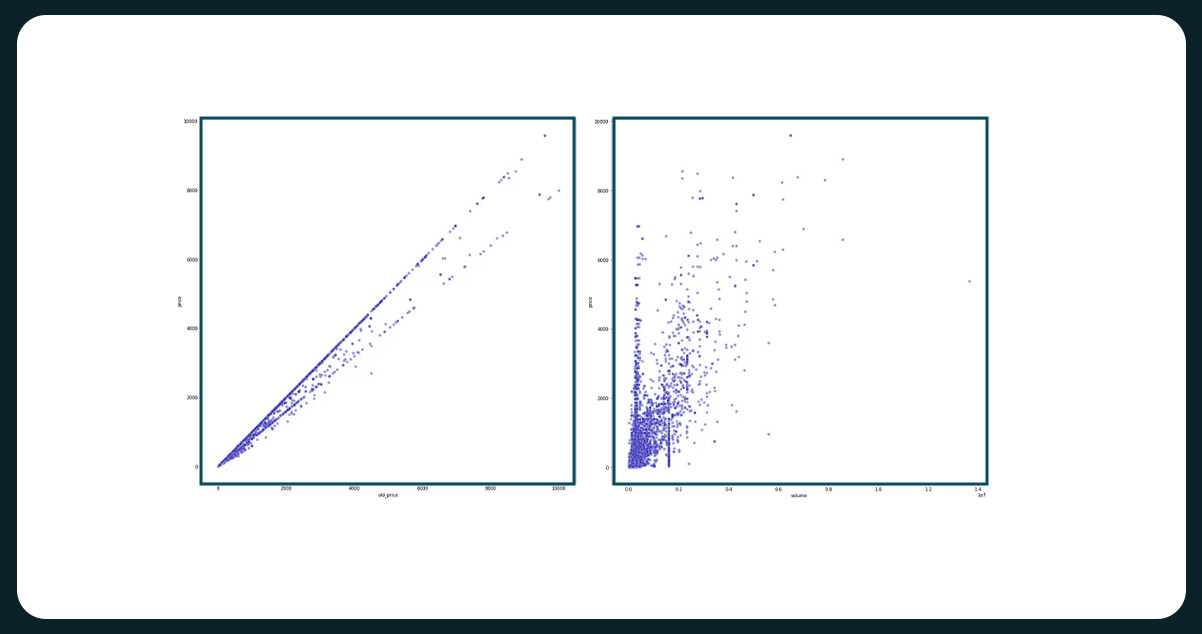
A clear linear relationship exists between the price and old_price, where higher prices correspond to higher old_price values. Additionally, product volume or dimension significantly influences the price. More oversized products, such as wardrobes, sofas, beds, tables, and desks, generally command higher prices due to their increased size and complexity.
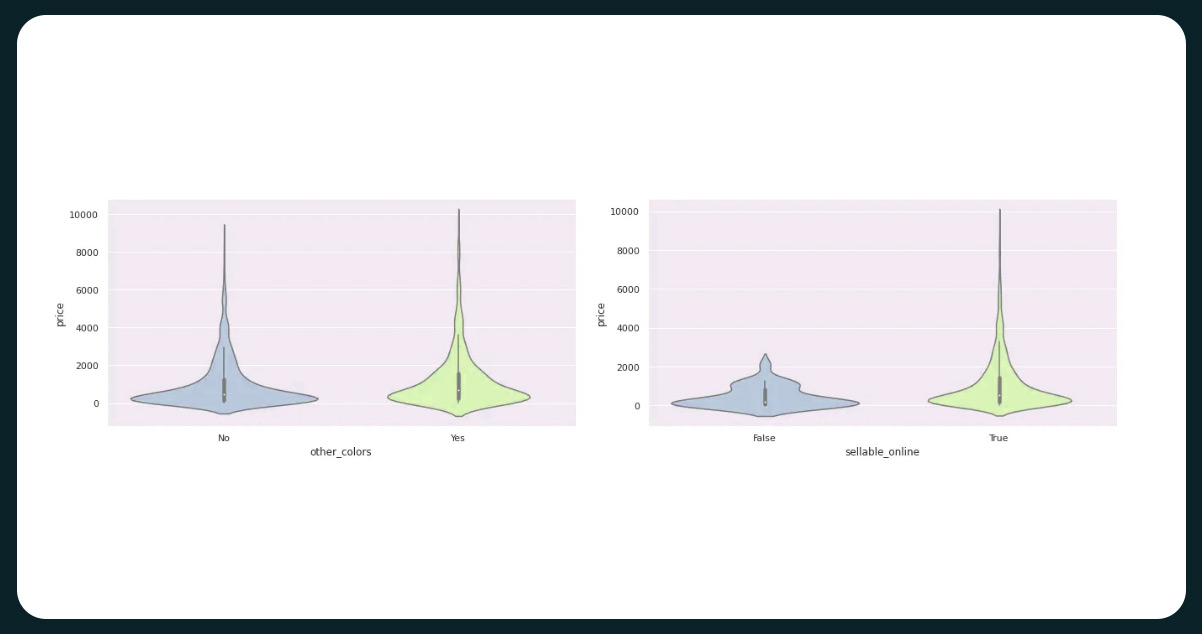
The Impact of Color Options and Online Availability on Product Prices: Online Availability More Influential, While Multiple Color Options Slightly Affect Price Probability
The availability of other_colors moderately affects product prices, with those having multiple color options having a slightly higher probability of higher prices. Conversely, products that are sellable_online or available online demonstrate a higher probability of commanding higher prices than those not online.
While almost all products in IKEA are available online, other colors for each product are less extensive. It is attributable to IKEA's focus on offering functional home products at the lowest prices, leading them to prioritize creating a wide range of product types rather than offering multiple color variations for each product.
About Linear Regressions

Linear Regression is a popular model for machine learning that helps establish a linear relationship between dependent and independent variables (Y) and (X). The model evaluates observations by comparing actual target (Y) values to predicted values, measuring the differences as residuals. The objective of Linear Regression is to minimize the sum of squared residuals.
Model Evaluation:
Data Pre-Processing:
We will prepare our dataset by encoding categorical features or columns to make them suitable for analysis.


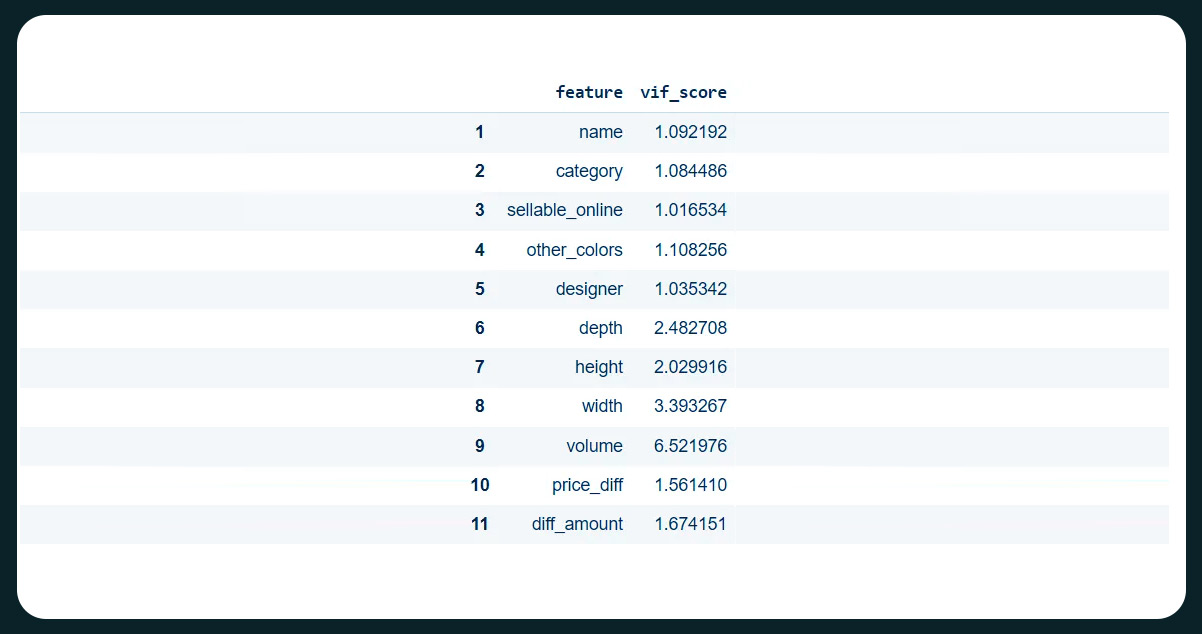
Before commencing the modeling process, we must assess whether multicollinearity exists with our target feature, "price." To achieve this, we will calculate the VIF Score (Variance Inflation Factor) for the features or columns, which aids in identifying potential multicollinearity.
The Variance Inflation Factor (VIF) is a well-known tool for detecting the multicollinearity degree in a several regression model. Multiple regression is employed when investigating the effects of multiple variables on a specific outcome, where the dependent variable represents the outcome influenced by the independent variables—inputs into the model.
Multicollinearity arises when a linear relationship or correlation is present among one or more independent variables or inputs. This phenomenon poses challenges in the multiple regression model as the inputs mutually influence each other, which can lead to inaccurate model results.
First, we will drop some unused features, namely "item_id" and "old_price.

Next, let's split the dataset into training and testing sets with a ratio of 20/80.



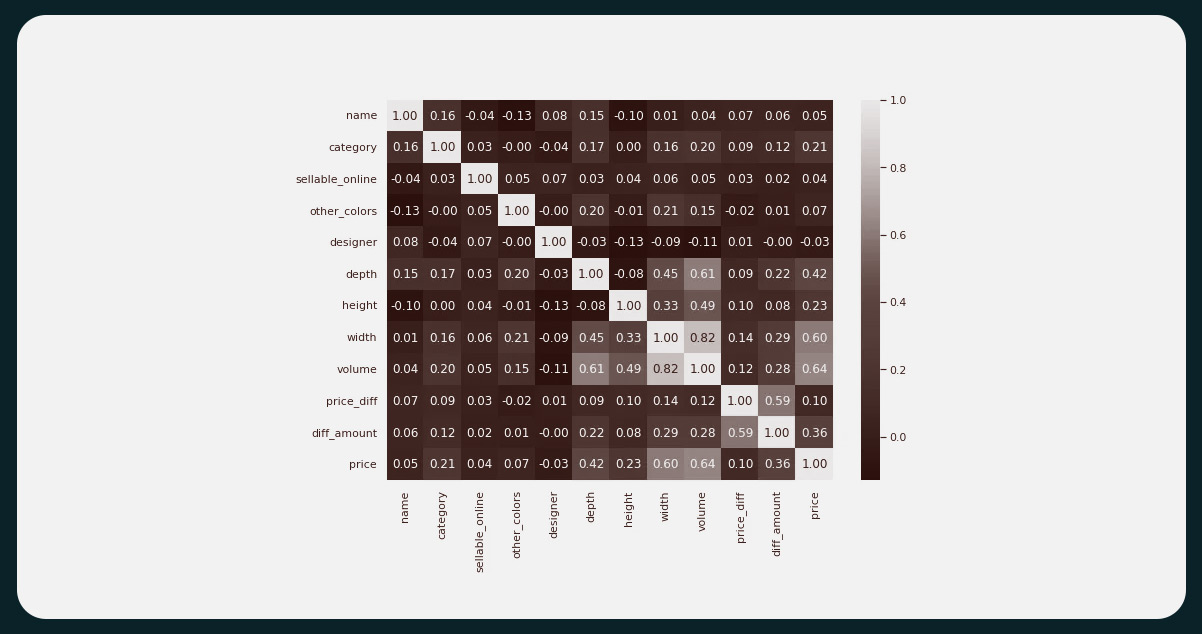
Based on the heatmap analysis above, we have decided to drop the columns "width," "height," and "depth" as they show a high correlation with other variables. Instead, we will retain the "volume" column, representing the product size and dimension.


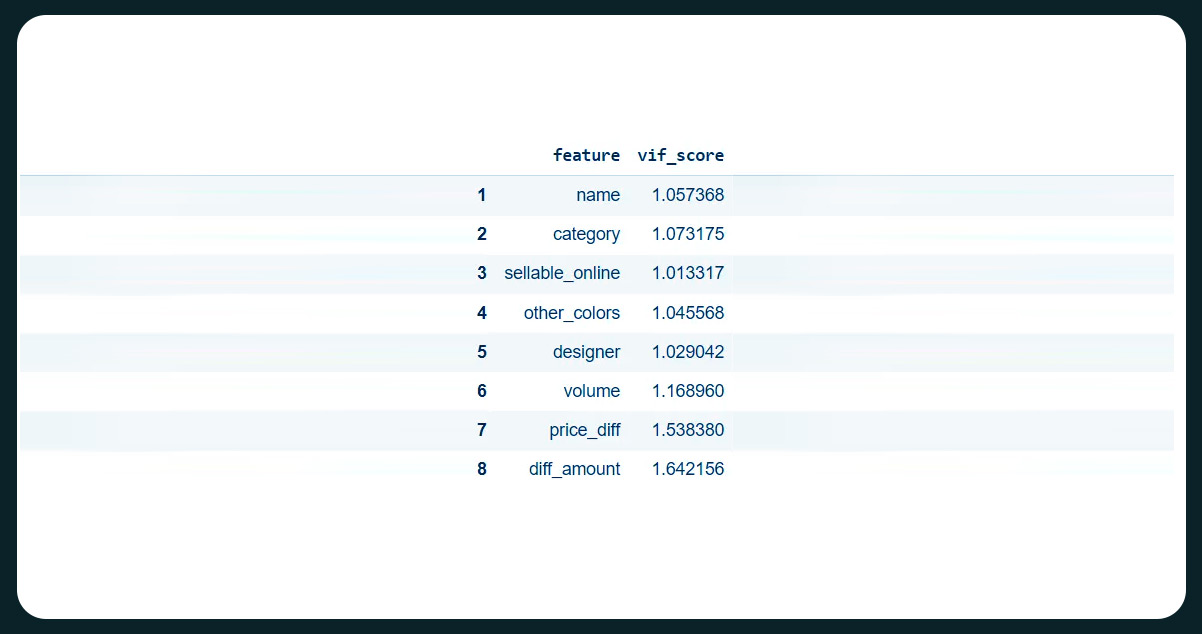
Excellent! With a reasonable VIF Score for our dataset, we can optimize our Linear Regression model using Ridge Regression. To achieve this, we need to determine the best lambda value for our model, which includes options such as [0.01, 0.1, 1, 10]. Lambda serves as a regularization parameter, helping prevent overfitting in the model.


Among the lambda values tested, lambda = 10 exhibits the lowest Root Mean Square Error (RMSE), making it the optimal choice for our Ridge Regression model.

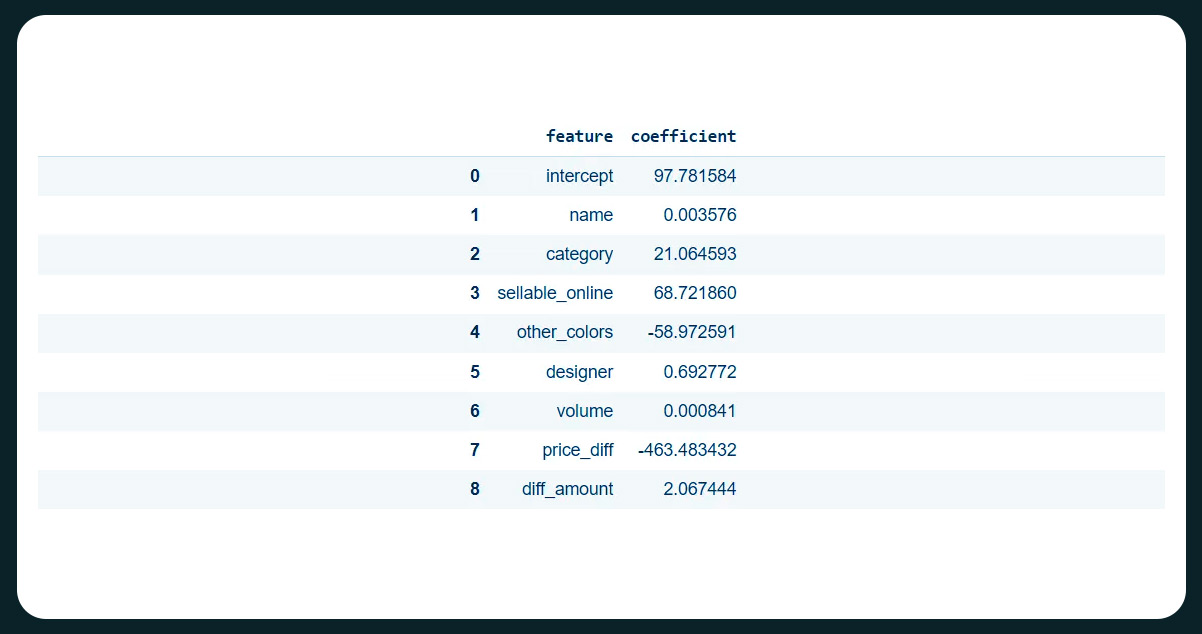
Assuming all other features are constant, the average product price is 97.781584.
For our LASSO Regression model, we will determine the best lambda value among the options [0.01, 0.1, 1, 10] to mitigate overfitting.


Among the lambda values considered, lambda = 0.1 demonstrates the lowest Root Mean Square Error (RMSE), making it the optimal choice for our Lasso Regression model to prevent overfitting.


With other features constant at zero, the average product price is 71.844397.
The training error for the RIDGE Regression model uses various metrics such as Mean Absolute Error (MAE), Root Mean Square Error (RMSE), and Mean Absolute Percentage Error (MAPE). These metrics help assess the performance and accuracy of the model in predicting product prices based on the given features.


LASSO Regression


Both RIDGE and LASSO models exhibit slightly higher values of Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), and Root Mean Square Error (RMSE) for the testing data compared to the training data. However, these differences are insignificant, indicating that both models are not underfitting. The higher values for testing data are attributable to the fact that the models have not been exposed to this data before.
Despite the differences, upon examining the scale of RMSE values in training and testing, we can conclude that the models can generalize well to new data.
Conclusion
We observed consistent results based on our price prediction modeling using both RIDGE and LASSO regressions. The factors that positively impact product prices include "sellable_online" (product availability online) and "category" (product category). On the other hand, "other_colors" (availability of other colors) and "price_diff" (price difference between the current and old price) harm product prices.
Products available online are more likely to command higher prices, highlighting the importance for IKEA to enhance its online selling capabilities. This strategy can lead to increased Sales of Goods while minimizing Operational Costs.
To leverage online and offline channels, IKEA could consider creating products exclusively available online but with offline displays. This approach would attract customers visiting physical stores and motivate them to explore the website for online purchases. To optimize production costs, IKEA should focus on creating products with a limited color option, streamlining product variations based on customer needs. This approach would enhance efficiency and cost-effectiveness in their product offerings.
For further details, contact iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile app data scraping needs