
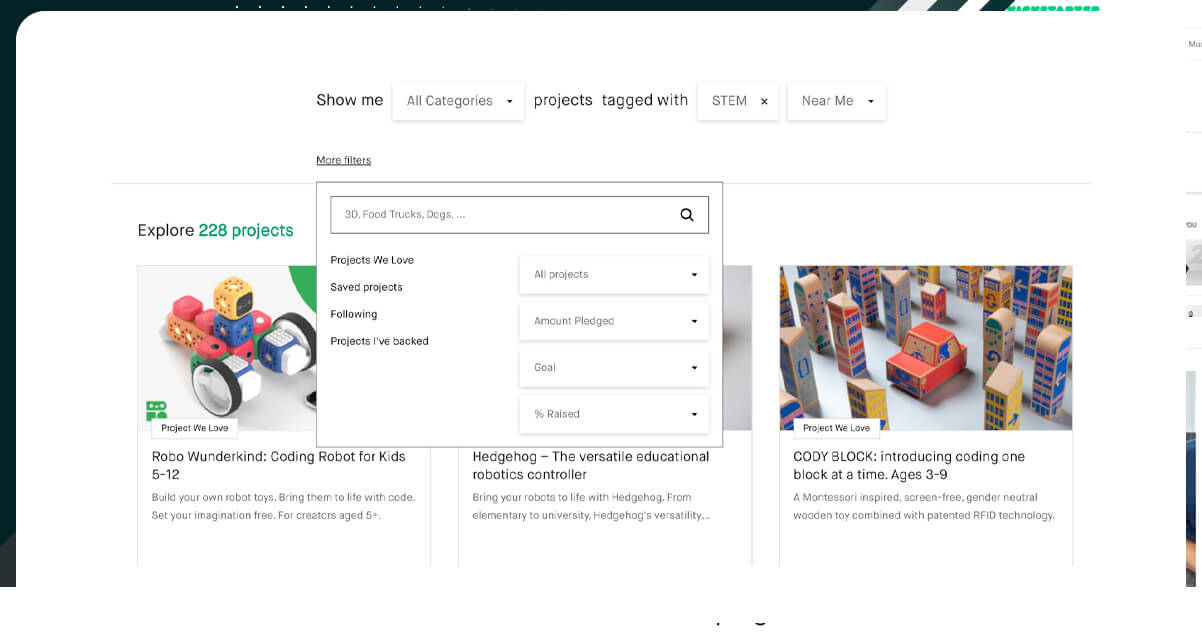
Kickstarter is one of the largest platforms for fundraising for creative projects. Several creators post their projects on Kickstarter, hoping that several interested investors will crowdfund them. However, every Kickstarter project has a title, image, location, short description, and other funding details.
With more than 16 categories and several thousands of creative projects, you can easily participate in any of them. Sometimes, although you want to participate in crowdfunding projects, you don’t know which one to choose. You don’t even have enough time to browse through a long list of categories to search for projects per your need.
In such an instance, data scraping plays a significant role. The Kickstarter scraper will crawl and scrape on all projects of the Kickstarter webpages category. All these data are in easy-to-access and easy-to-read formats. The data extracted will help the funding agencies decide on funding release.
This blog gives a clear idea of how to scrape Kickstarter data. Here, we are using the Python module. BeautifulSoup to code specific web scraping scripts. It will provide valuable information about Kickstarter projects.
Step 1: We first imported the necessary modules to start the process.

Step 2: Get the HTML
Before using BeautifulSoup, first, we require some HTML. Here, we used a standard Python module, urllib2. Now, pass the URL into urllib2.urlopen() and read(). This will obtain HTML from a page.

Step 3: Get Start with BeautifulSoup
We first initialized the BeautifulSoup object simply by running HTML into the BeautifulSoup()constructor.

After initialization, we get access to multiple pieces of information.

Step 4: Avail More Information
This is where browser development tools are required. Chrome/Chromium and Safari are known to have a fantastic set of development tools.
To directly search for the element in the page’s source HTML, right-click on the page element and then select Inspect Element. For example, we tracked Kickstarter backers with our scraper. After inspecting one of the information elements, we obtained HTML attributes like ‘itemprop’ having a value of “Project[backers_count].”
Now, using this attribute, instruct BeautifulSoup to find the element. Although, we can see several backers. But our objective is to find this attribute programmatically with ‘soup’ with the help of the ‘find’ method. As the first argument, we will pass the ‘data’ tag followed by the attribute we want to match. It will appear like this.

It returns with one BeautifulSoup HTML object. Now let’s get several backers using the element’s ‘value’ attribute.

Let’s see if we want several backers on the project page.

Now let’s understand what Indiegogo is.
Similar to Kickstarter, Indiegogo is again an online crowdfunding platform. This platform allows users to support campaigns featuring creative designs, products, and innovative ventures. Indiegogo runs both reward-based campaigns and donations. It rewards the crowd investors in return for investing.
However, there are two fundamental differences between Kickstarter and Indiegogo. The differences are in terms of the Python bot built-up.
You won’t find filters by country on Indiegogo. It possesses standard filters like projects by popularity, category, and most funded. The bot has to go much deeper to find the project country and extract the data.
By Query

By Category

The above URL provides two parameters – one by query and the other by category. Apart from these, you can also add the most funded project, campaign, and timing.
The tools and libraries used are the same as Kickstarter. Both Selenium and BeautifulSoup are used. Web APIs are only sometimes helpful in extracting data, especially from crowdfunding platforms. Crawlers and scrapers are the alternative approaches for data extraction. We are interested in the service’s campaign section to analyze the crowdfunding campaign. Each campaign is identified with the URL
https://www.indiegogo.com/projects/jolla-tablet-world’s -first-crowdsourced-tablet#story.
Here the extraction is entirely focused on Jolla’s crowdfunding campaign. Using our iWeb Data Scraper, we extracted the data from Jolla’s Indiegogo campaign. A total of 21,565 funders existed. After loading the funders page, we obtained a list of 20 funders. On clicking ‘Show More,’ 20 more funders get added. This indicated that to get the complete list browser emulator is needed. We then applied a navigation scripting and testing utility written in JavaScript. It allows the scraper to run full browser features. This gives a complete list of the campaign’s funders.

The above code is the crawler code for scraping individual campaign funder data. After the complete representation of the funders list, the utility data gets distilled using a scraper. The below code includes scraper code in Python.


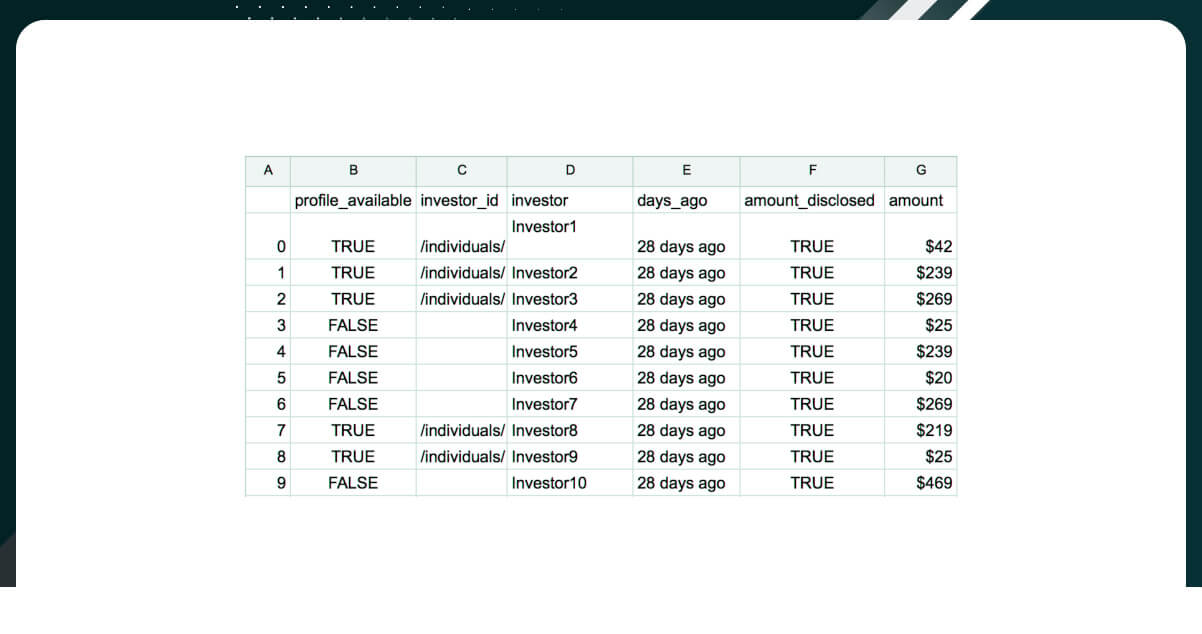
The outcome of the data in an organized form is available in an excel format. The available data includes the individual funder’s ID number, profile availability of the potential funder, investor id, and investor name, as shown below.
For more information, contact iWeb Data Scraping now! You can also reach us for all your web data scraping and mobile data scraping service requirements.