
If you work in the travel sector, you're likely acquainted with TripAdvisor, among the most prominent travel websites globally. In this discussion, we'll explore the process of extracting data from TripAdvisor, a leading platform in the travel industry.
TripAdvisor is an online platform that aids users in their travel planning and booking endeavors. It accomplishes this by offering numerous reviews, ratings, and recommendations about hotels, restaurants, attractions, and more. With its extensive collection of millions of reviews, photos, and other content, TripAdvisor is an invaluable resource for businesses and individuals seeking to enrich their travel experiences. The significance of TripAdvisor data scraping becomes evident when you understand how to leverage the data it provides.
Nevertheless, manually retrieving data from TripAdvisor can prove to be an uphill and formidable task. It is where the utility of a TripAdvisor data scraper becomes apparent. This guide will delve into what a scraper is, how it operates, and the process of extracting valuable data from TripAdvisor.
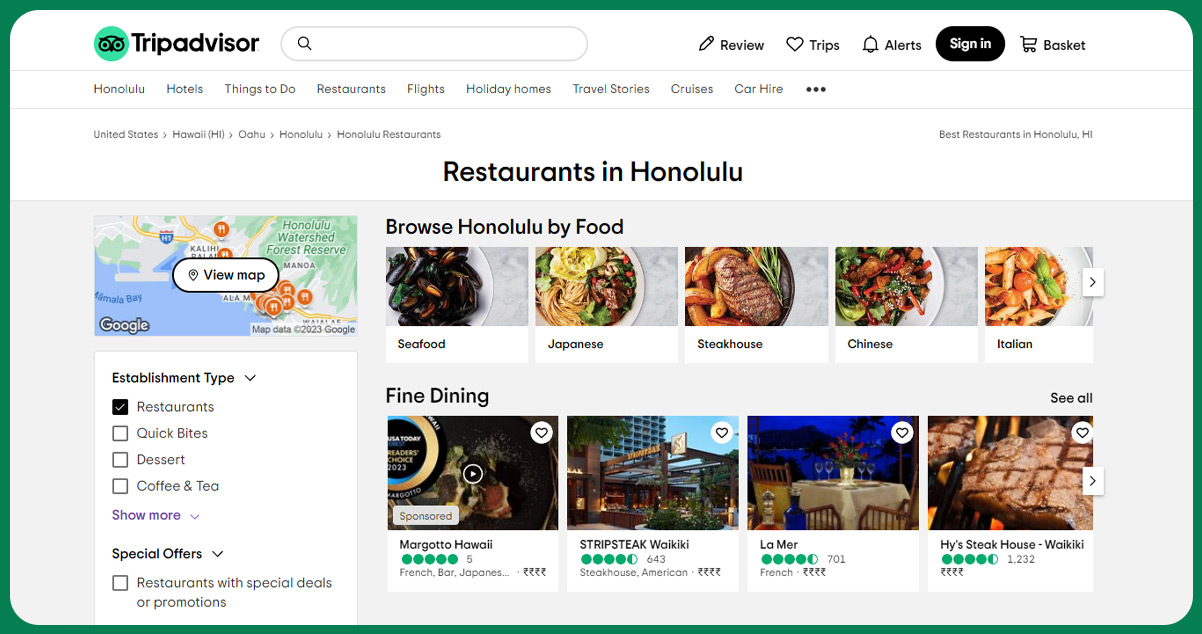
TripAdvisor Restaurants Data encompasses information and details about dining establishments featured on the TripAdvisor platform. This data includes restaurant-related information, such as customer reviews, ratings, photos, menus, contact details, and location information. Businesses and individuals often seek access to this data to make informed dining choices, analyze restaurant performance, and gather insights into culinary trends and customer preferences. Extracting TripAdvisor Restaurants Data can be valuable for restaurant owners, food enthusiasts, and data-driven professionals looking to understand the dining landscape and make informed decisions within the restaurant industry.
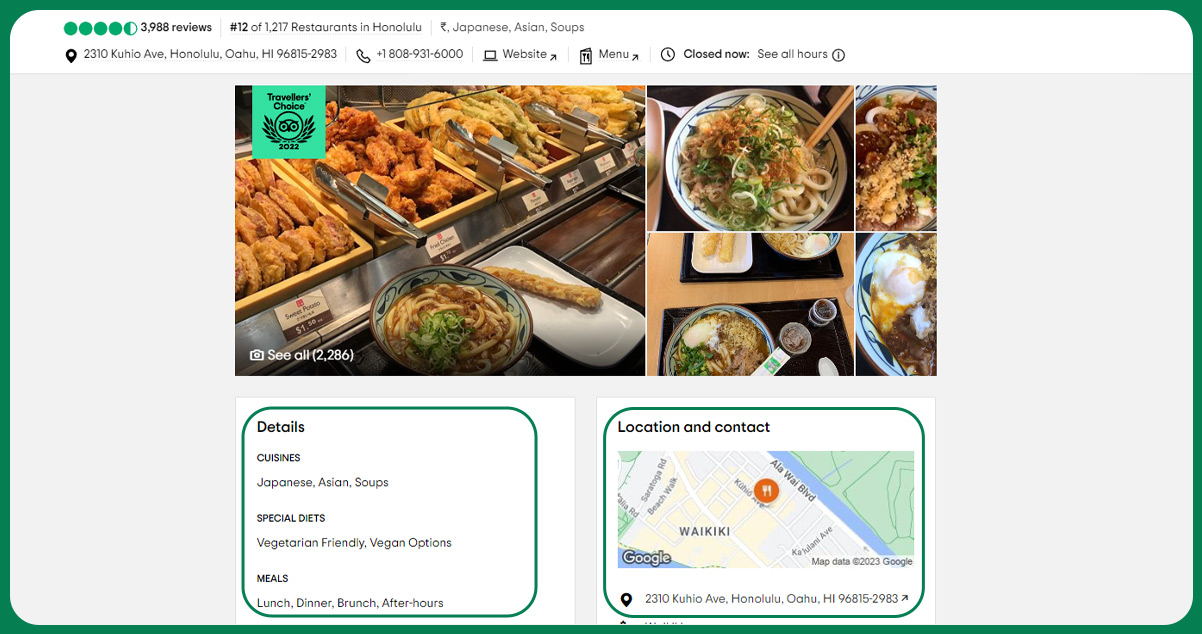
One of the most effective approaches is web scraping when it comes to harnessing the wealth of information provided by TripAdvisor. Extracting Restaurant Data From TripAdvisor involves the automated collection of data from web pages, making it valuable for gathering pricing and review details. Integrate this data into a database for further analysis or share through a scraper API.
For those operating within the travel industry, the TripAdvisor API offers a seamless way to incorporate TripAdvisor reviews and more directly into your website. This integration proves advantageous as it enables website visitors to access authentic evaluations from a trusted travel source, enhancing the overall user experience.
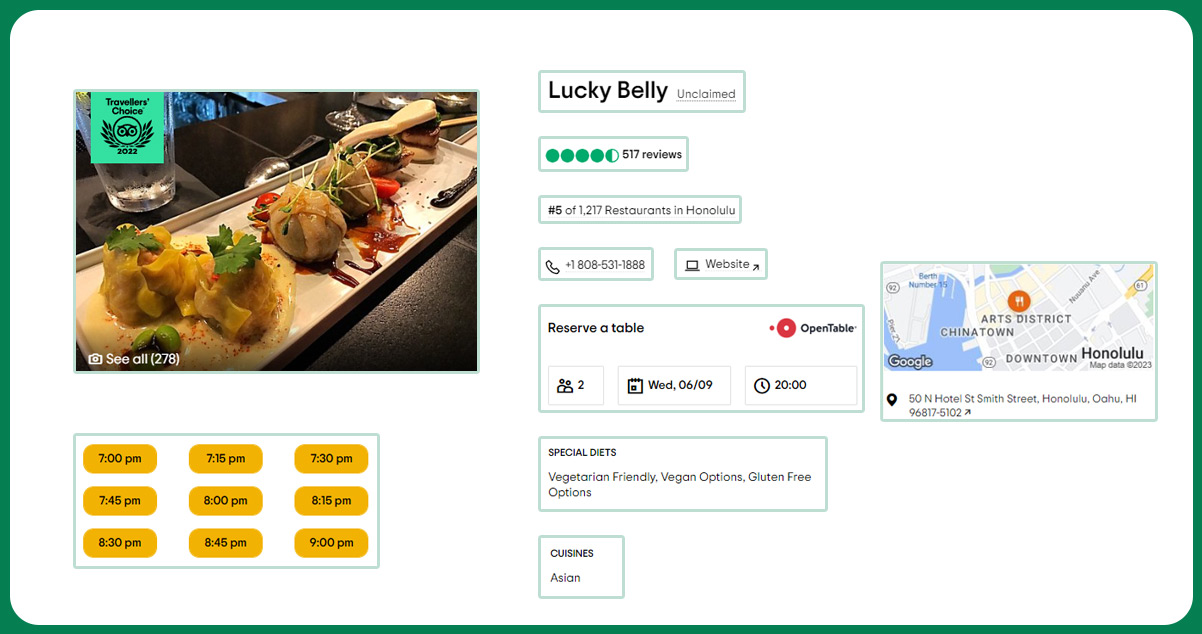
Local Insights: Scraping TripAdvisor data allows businesses to gain local insights into specific regions or neighborhoods. It can help them tailor their offerings to meet different locations' unique preferences and demands.
Seasonal Trends: By analyzing scraped data over time, businesses can uncover seasonal trends in hotel and restaurant bookings, helping them make informed decisions regarding marketing campaigns, staffing, and inventory management.
Diverse Cuisines: By analyzing scraped data over time, businesses can uncover seasonal trends in hotel and restaurant bookings, helping them make informed decisions regarding marketing campaigns, staffing, and inventory management.
Special Offers: Scrape restaurant data from Tripadvisor to get pricing information helps track special offers, discounts, and promotions competitors offer, allowing businesses to adjust their pricing strategies accordingly.
Operational Efficiency: By scraping hotel and restaurant data on operating hours and peak reservation times, establishments can optimize staff schedules and resources for maximum efficiency during high-demand periods.
User-Generated Content Moderation: Hotels and restaurants can use scraped data to monitor and moderate user-generated content, ensuring their online presence remains free of harmful or inappropriate reviews or comments.
Data scraping from travel websites is common in data analysis and web development. One popular target for web scraping is TripAdvisor, a platform rich in information about hotels, restaurants, and attractions.
The following guide will walk you through scraping TripAdvisor using Python, providing a step-by-step tutorial. Our tools for this endeavor will be the BeautifulSoup and requests libraries, essential for extracting data from TripAdvisor's web pages.
Step 1: Install the required libraries
Before commencing the scraping process, installing the necessary libraries is essential. To install these libraries, open your command prompt or terminal and input the following commands:

Step 2: Find the URL for Scraping
The first step to initiate the scraping process on TripAdvisor is to identify the webpage URL you intend to scrape. This tutorial will focus on scraping reviews for a particular restaurant. To locate the URL for the restaurant, visit TripAdvisor's website and search for the specific restaurant of interest.
Once you've found the restaurant, navigate to the "Reviews" tab. In the address bar of your web browser, you'll observe the URL for the reviews page. Copy this URL, as it will be essential for the subsequent steps in the process.
Step 3: Retrieve the HTML content
We'll employ the requests library to fetch the webpage's HTML content. Below is the code demonstrating how to retrieve the HTML content:

In the provided code snippet, our initial step involves importing the requests library, which is essential for handling HTTP requests. Subsequently, we specify the URL of the restaurant's webpage that we aim to scrape. We employ the "requests.get()" function to retrieve the web page's content, making an HTTP GET request. The HTML content of the webpage is then captured and stored in a variable aptly named "html_content." This preparatory process readies us for the subsequent stages of web scraping, where we can extract and analyze the desired data from the HTML content.
Step 4: Parse the HTML Content
Now that we have successfully obtained the HTML content of the webpage, our next step involves parsing it to extract the specific data we're interested in. To achieve this, we will leverage the BeautifulSoup library. Below is the code demonstrating how to parse the HTML content:

In the provided code snippet, we begin by importing the BeautifulSoup library. We then employ the "BeautifulSoup()" function to parse the previously obtained HTML content. Store the outcome of this parsing operation in a variable aptly named "soup." This parsed representation of the HTML content enables us to easily navigate the webpage's structure and proceed with data extraction.
Step 5: Data Extraction
Having successfully parsed the HTML content, we are now poised to extract the desired data, which, in this instance, involves the review text and the associated review rating. Below is the code that demonstrates how to accomplish this task:

Within this code snippet, the initial step involves the creation of an empty list termed "reviews." Subsequently, employ a for loop to iterate through all the review containers present on the webpage. For each review container, both the review text and rating are extracted. Store these extracted values as a tuple, and this tuple is added to the "reviews" list using the append() function.
This process collects and organizes the review text and ratings into the "reviews" list, facilitating further analysis or utilization of this data.
Step 6: Print the Data
To conclude the process, we can print the data we've extracted. The following code snippet demonstrates how to accomplish this by printing both the review text and the associated rating:

Step 7: Refine the Data
Sometimes, the data extracted from a webpage may contain undesirable characters or require further refinement to enhance its usability. For instance, it may be necessary to eliminate unwanted characters from the review text or convert the review rating from a string to an integer. Below is the code demonstrating how to refine the extracted data:

In the provided code, we employ the "replace()" function to eliminate newline characters, utilize the "strip()" function to remove any leading or trailing whitespace from the review text and transform the review rating from a string to an integer. We further scale the rating by dividing it by 10 to obtain a rating on a 1 to 5 scale.
Step 8: Save the Data
After successfully extracting Tripadvisor hotel and restaurant data, you should preserve it for future analysis by saving it to a CSV (Comma-Separated Values) file. Below is the code illustrating how to save the data to a CSV file:

We import the csv library in the provided code, an essential tool for working with CSV files. Next, we utilize the open() function to create a new CSV file named "reviews.csv." Using the csv.writer() function, we establish a writer object that facilitates data writing to this file, including the initial column headers.
Within a subsequent for loop, we systematically iterate through each review in the 'reviews' list. We extract both the review text and rating for each review, then use the writerow() function to write this data into the CSV file.
Scraping TripAdvisor using Python can be a potent data extraction method suitable for various purposes such as analysis and web development. Throughout this process, we've covered the essentials of scraping TripAdvisor, including utilizing Python alongside the BeautifulSoup and requests libraries, as well as the subsequent steps of data extraction, refinement, and storage.
For further details, contact iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile app data scraping needs