What is web scraping? The majority of people ask this question. It aggregates data from the website using a web scraper tool. This data aggregation tool collects data from the website and social media profiles. It scans a webpage for relevant information relating to URL entered, phrases, and keywords. After collecting all the applicable data, the web scraper extracts the information into a document. It gets organized, thereby making it easy to analyze.
Always keep in mind that all the scraping processes are done ethically. The following are the best ethical practices to follow to avoid harming others:
Gathering such a massive amount of data gives the maximum power to the person to scrape a lot of personal information to the person operating the web scraper.
Social networking services have been continuously booming in the past few decades. People, however, leave several digital footprints on LinkedIn, Twitter, Facebook, and so on. These digital footprints paint a picture of what happens in the real world. Analyzing these footprints is considered social network analysis. This creates data on a large human scale that hasn’t been seen before.
Social networks are undoubtedly massive. It comprises dozens of millions of users. The interaction between these users is even more complex. No matter what kind of social networks are, they all have some everyday things in them. The most common properties include the small world effect, power law distribution, and strong community structure.
Similar to Twitter, Sina Weibo is a micro-blogging social media platform. The Sina Weibo core is ‘weibo’ ( ). The Sina Weibo users perform two main functions with weibos: They author and read. Banning Twitter in China, Sina Weibo is considered an alternative to it. It has reached more than 56 million daily active users. This social network is highly informative regarding content, verification system, and user interaction.
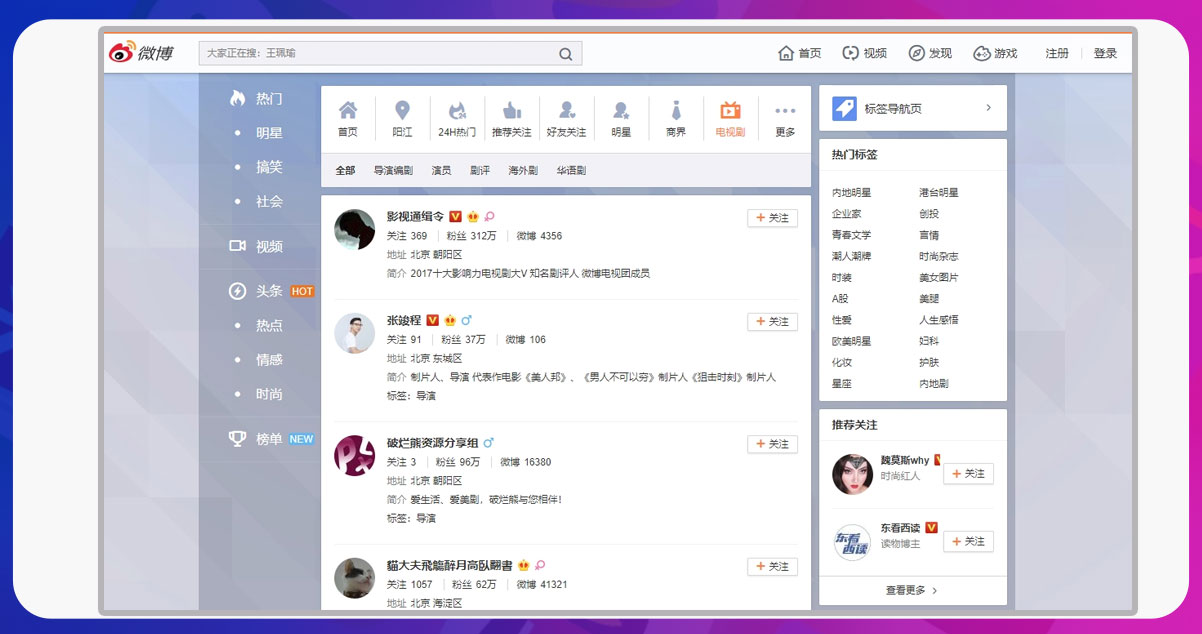
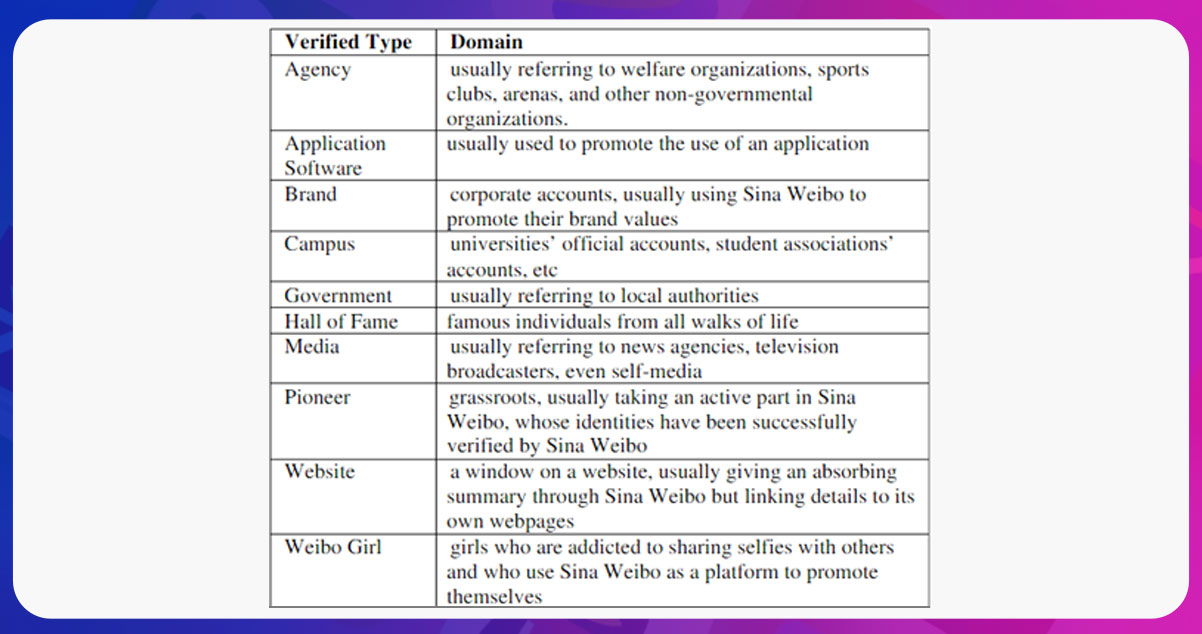
Apart from posting comments on someone’s weibo, and replying to others’ comments on someone else weibo, Sina Weibo also allows users to participate in its identity verification process. Verified users are divided into eleven groups.
For example, a user page appears as follows:
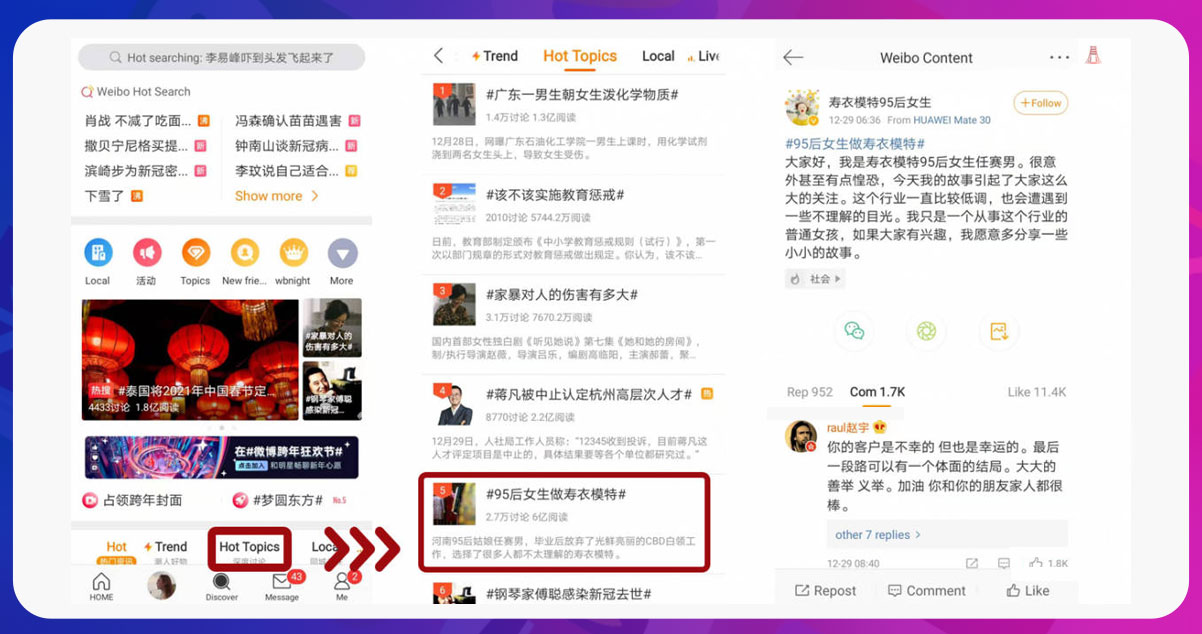
When a user visits a social media platform website, say http://us.weibo.com/gb, he interacts with the platform’s web interface. This interface facilitates the interaction between a human user and the social media platform. However, several social media platforms provide an API, an additional interface to simplify the interaction between software and social media platforms. Let’s take an example. On your phone, the Twitter app requires you to fetch your tweets. Those tweets are requested from the Twitter API. The API returns structured data in JSON format. Then, this optimizes by software for processing.
Both API and web interface and the API is used to gather data from the social media platform. Collecting via HTML or web interface needs web harvesting software. Moreover, both social media and web harvesting are complementary to each other. It holds different strengths and weaknesses. The critical points of collecting via API are:
Requisite of Weibo API
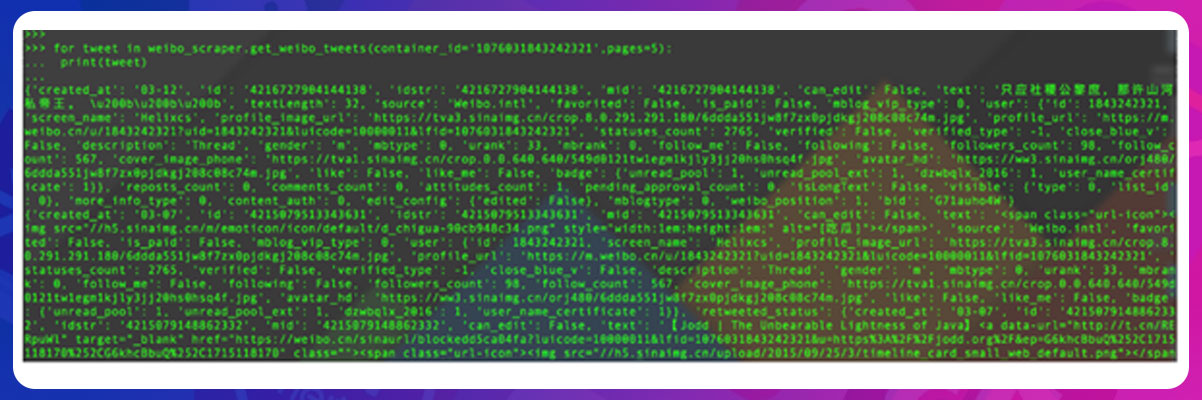
Below is the part of the weibo retrieved from the Weibo API


JSON is a simple format extensively used to exchange data on the web. Other necessary fields are:
Like other social media APIs, Sina Weibo also offers various methods of interacting with the API. These include ‘status update’ for weibo posting and ‘friendship destroy’ for unfollowing another user.
In this context, we will collect weibo data from researching big data using iWeb Data Scraping.
Pip
$ pip install weibo-scraperOr upgrade it
$ pip install --upgrade weibo-scraperpipenv
$ pipenv install weibo-scraperOr upgrade it
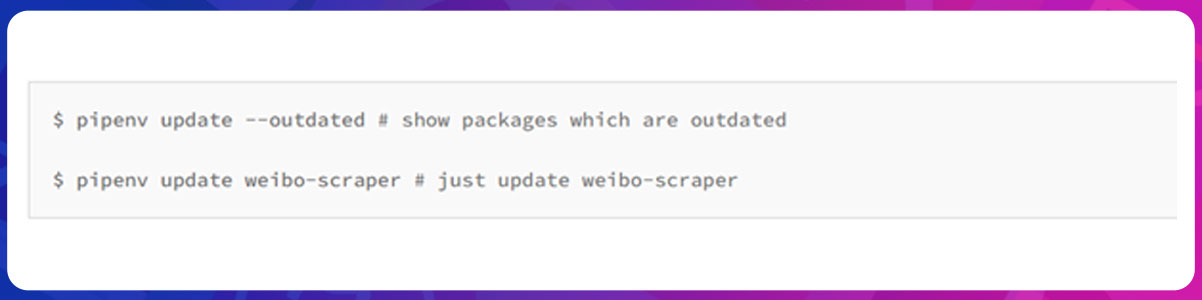
Only Python 3.6+ is supported
1. First, get weibo profile by name or uid
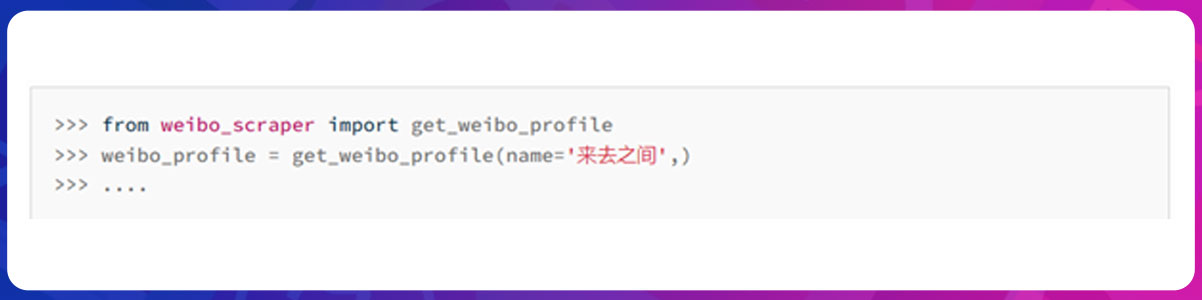
You will see weibo profile responses like this
weibo_base.UserMeta
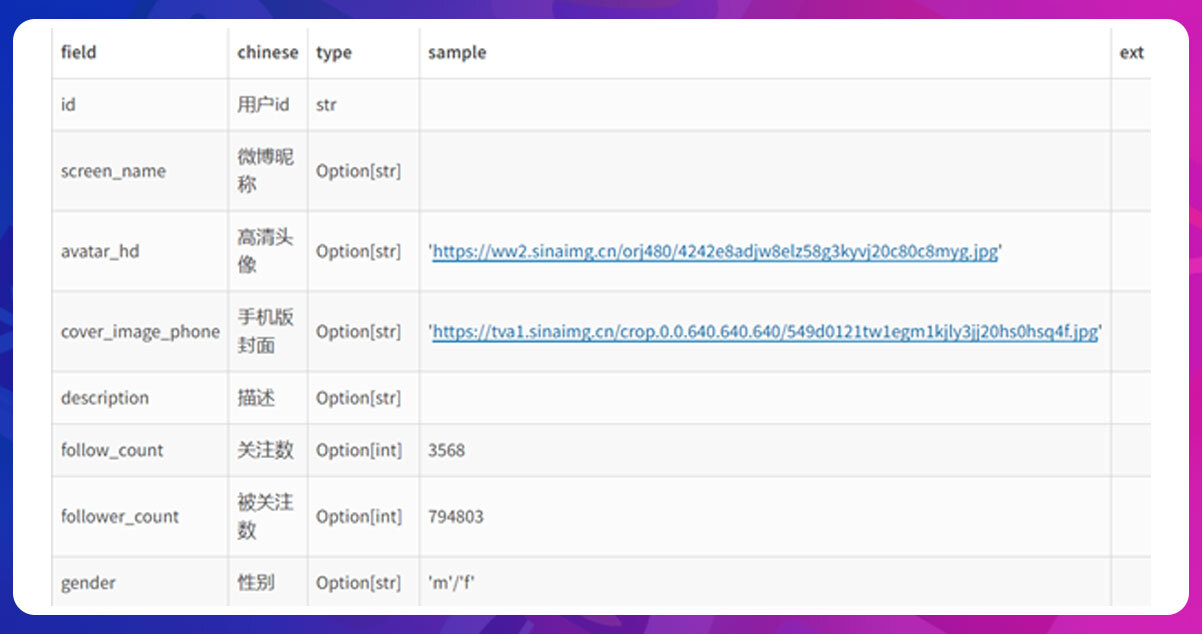
This response will include the following
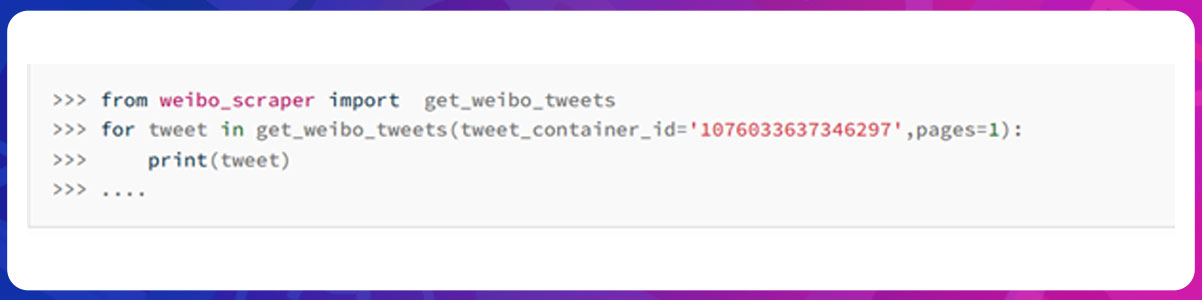
To get weibo tweets, you can choose tweet_container_id
Getting the raw weibo tweets by a nickname is also easy. The framework of pages is optional.
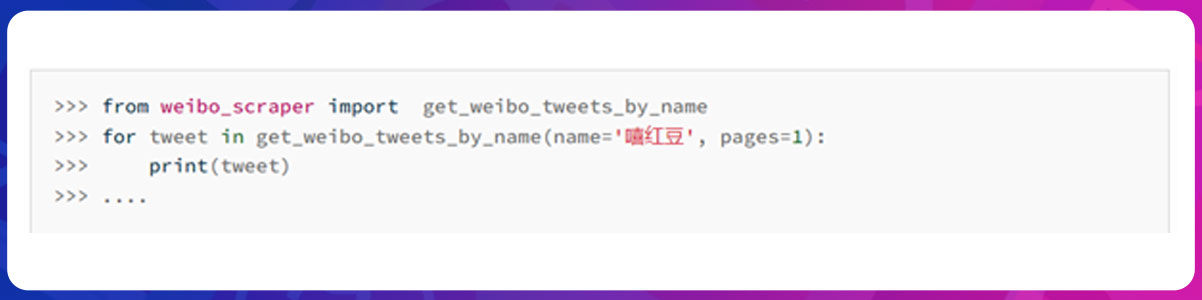
To get all tweets, set the framework of pages as None.
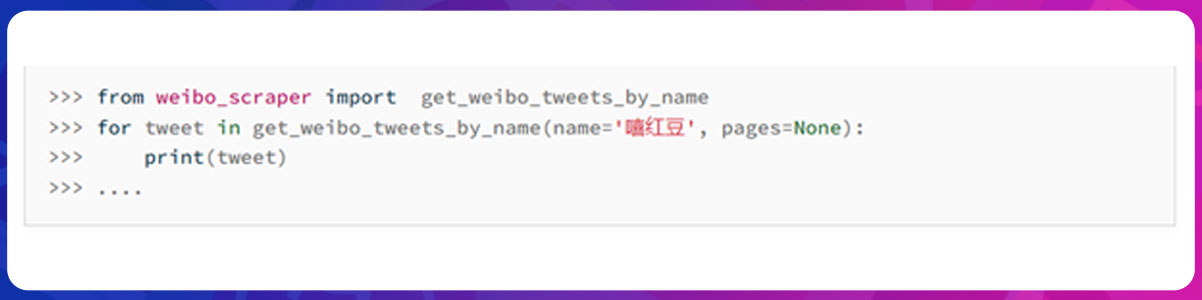
You can also get formatted tweets using the API of
weibo_scrapy.get_formatted_weibo_tweets_by_name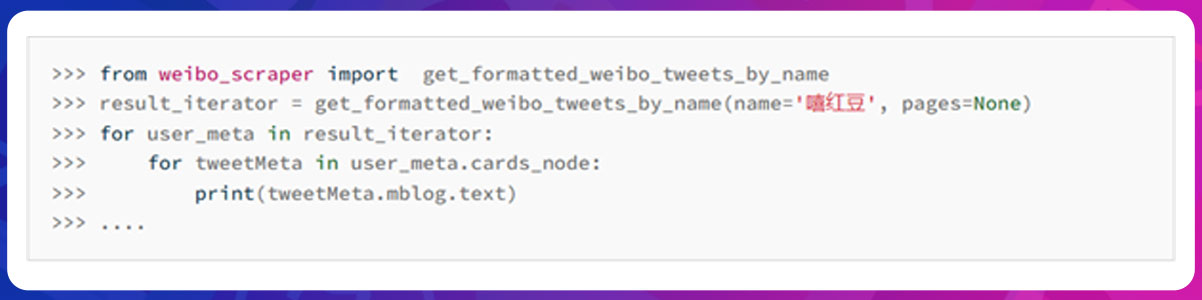
CTA: For more information, contact iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile data scraping requirements..