Web scraping is the data extraction process from websites. The web scraping software access the World Wide Web directly using the Hypertext Transfer Protocol or a web browser. Although software users perform web scraping manually, it is an automated process run using a bot or web scraper. Nowadays, scraping plays a significant role in Web APIs design and more.
Node.js, an open-source project, is a popular runtime environment with collective features for easy-to-develop stuff. Within a web browser, manipulating the DOM is something that JavaScript & libraries like jQuery perform well. Hence, writing web scraping scripts in Node.js is better, as it gives enough options for DOM manipulations.
Here, we will brief you on the web scraping of Google Jobs with Nodejs.
First of all, we will install google-search-results-nodejs
The complete code will look like this.
npm i google-search-results-node.jsThe complete code will look like this.
Here, we will brief you on the web scraping of Google Jobs with Nodejs.
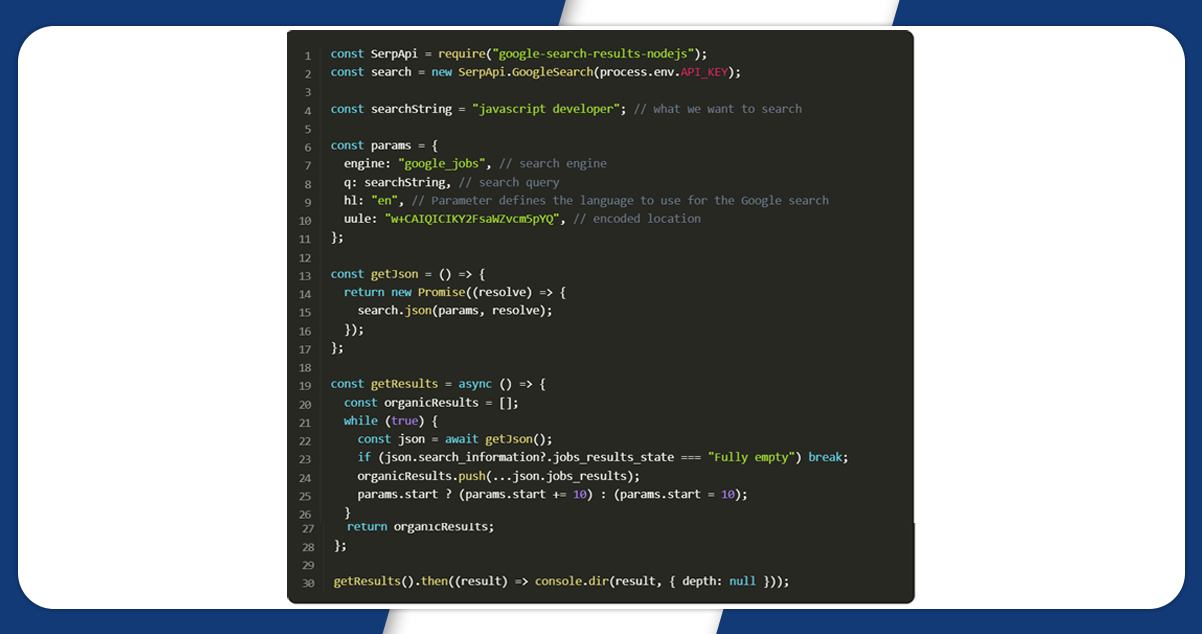
We will first declare SerpApi from google-search-results-nodejs the library and then define a new search instance using the API key from SerpApi:

Next, we will write a search query and the required parameters for making a request:

Then, we cover the search method from the SerpApi library

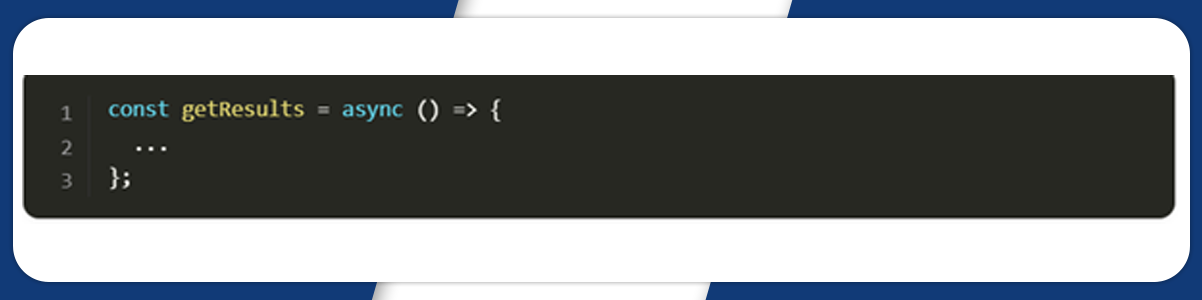
Finally, we declare the getResult function to get and return data from the page.
In this function, first, we declare a list of organicResults with the result data.

Now, we will use a while loop. In this loop, we obtain json with results. Track if the results are available on the page jobs results state isn't "Fully empty" move the results to the organicResult list, mention the start number on the results page, and repeat the same until you get the results on the page.

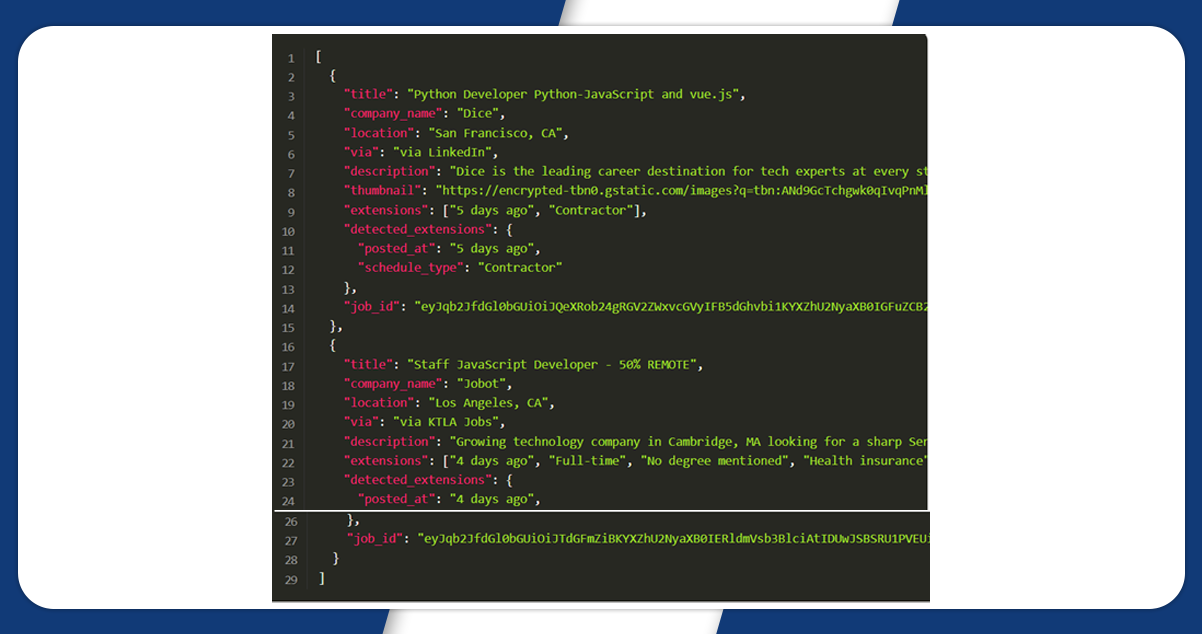
After running the getResults function and printing all the necessary information in the console, using a console.dr process, it allows using an object with the necessary parameters.
The output will be like this:
First, create the Node.js project and then add npm packages, including a puppeteer, puppeteer-extra, and puppeteer-extra-plugin-stealth for controlling Chrome or Firefox.
To perform this, open the command line and enter npm init -y , and then npm i puppeteer puppeteer-extra puppeteer-extra-plugin-stealth
Using the SelectorGadget Chrome extension, getting the correct CSS selector is very easy. First, we will scroll through all job listings until no more are available. Then, after finishing scrolling, we will extract data from HTML. The below Gif presents the approach of selecting different parts of the results.
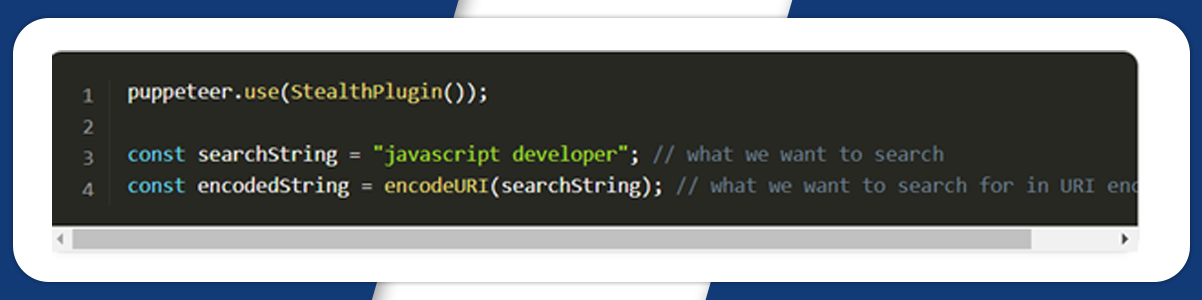
Instruct the puppeteer to control the Chrome browser using puppeteer-extra and StealthPlugin to restrict the website from detecting that you are using a web driver from detecting that you are using a web driver from puppeteer-extra-plugin-stealth library
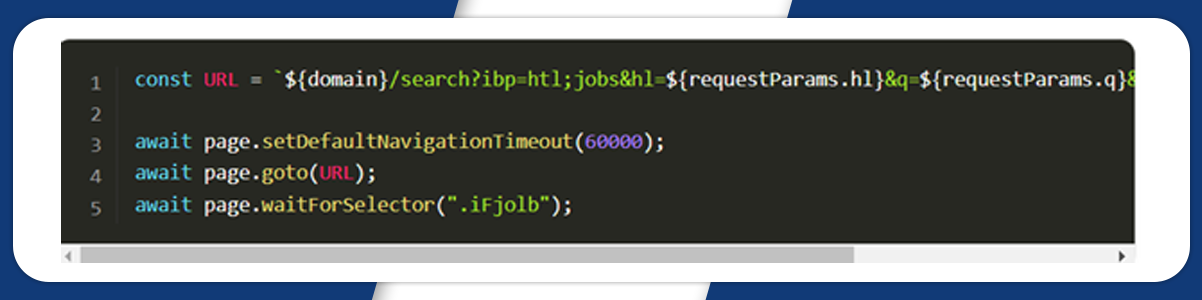
Now, add ‘use’ to puppeteer stealthPlugin. Mention what we are searching for and encode it within the URI string.
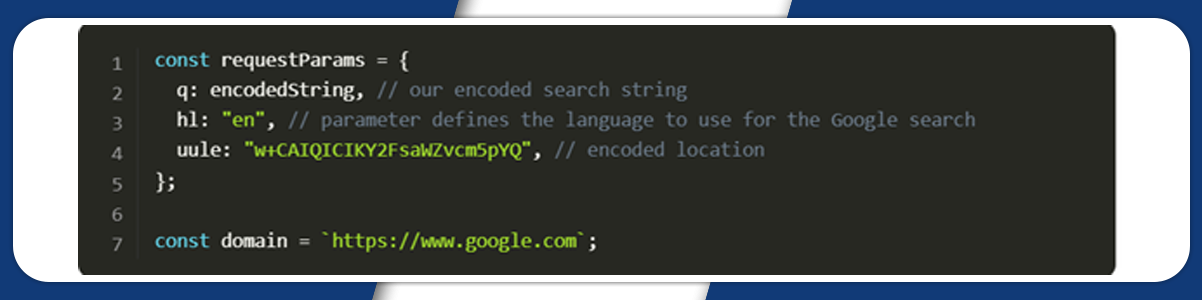
Next, we will write the request parameters and Google domain URL:
We will then write a function to scroll the page to load all articles.
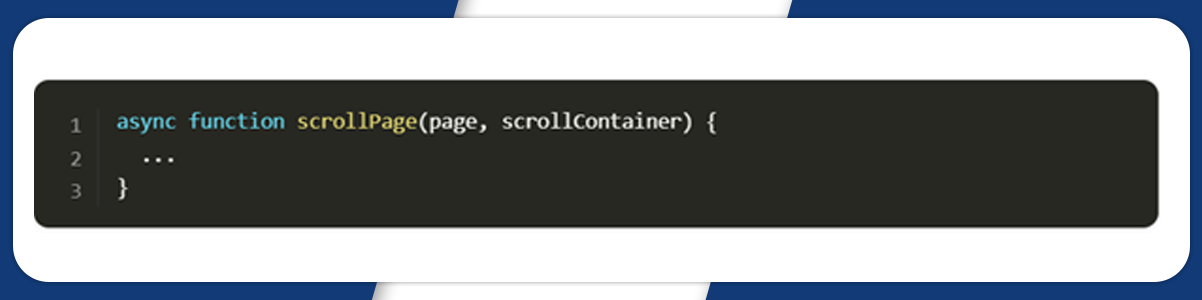
In this function, first, we require ScrollContainer height. Then, we will use a while loop to scroll down, wait for 2 seconds, and get a new ScrollContainer height.
Next, we will stop the loop if the newHeight is equivalent to lastHeight. Otherwise, we will define the newHeight value to the lastHeight variable and repeat the same until the pages don’t scroll completely.
Next, we will write a function to get the job data from the page
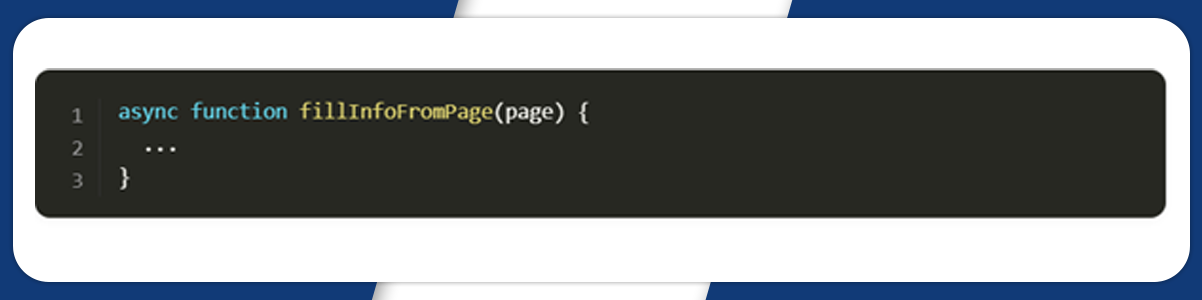
First, we will get all the job results on querySelectorAll() and make a new list from got NodeList.

The next step is to assign the essential data to each object’s key using textContent and trim() methods. It gets the raw text and eliminates white space from both ends of the string.

To control the browse and avail information, we will write a function.
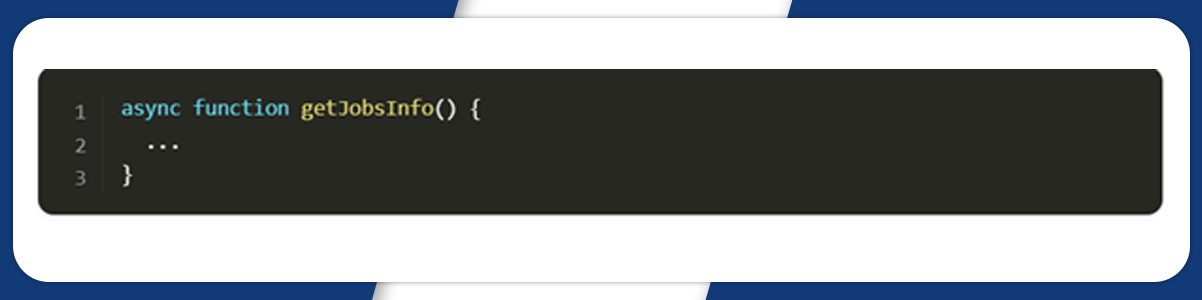
In this function, first, we will define a browser using puppeteer.launch method with current options. It includes headless: false and args: ["--no-sandbox", "--disable-setuid-sendbox"]
>We will open a new page:
Next, we define the complete request URL, change the default time for waiting, and obtain the following:
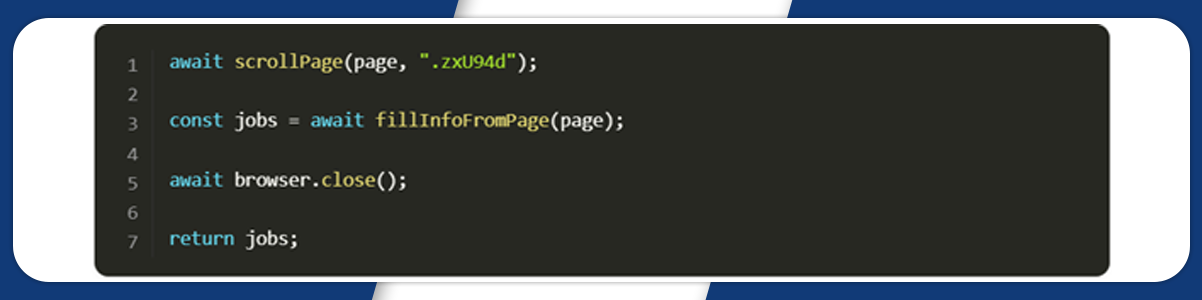
Finally, we will wait for the page to scroll, save jobs data, close the browser, and return the received data:
We will now launch the parser:
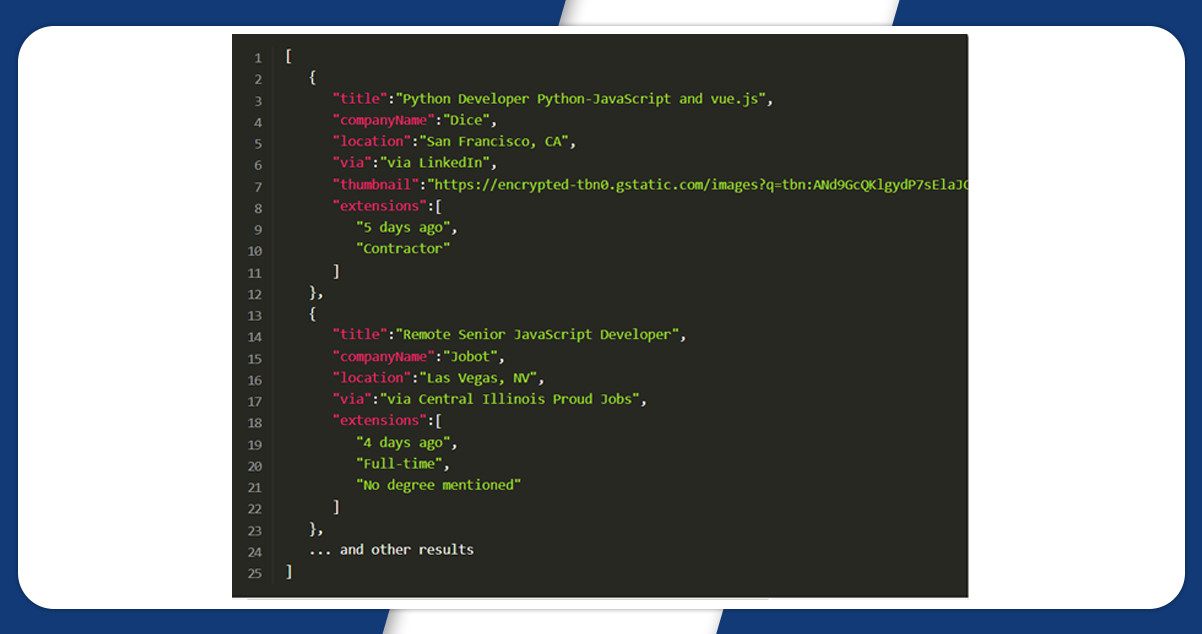
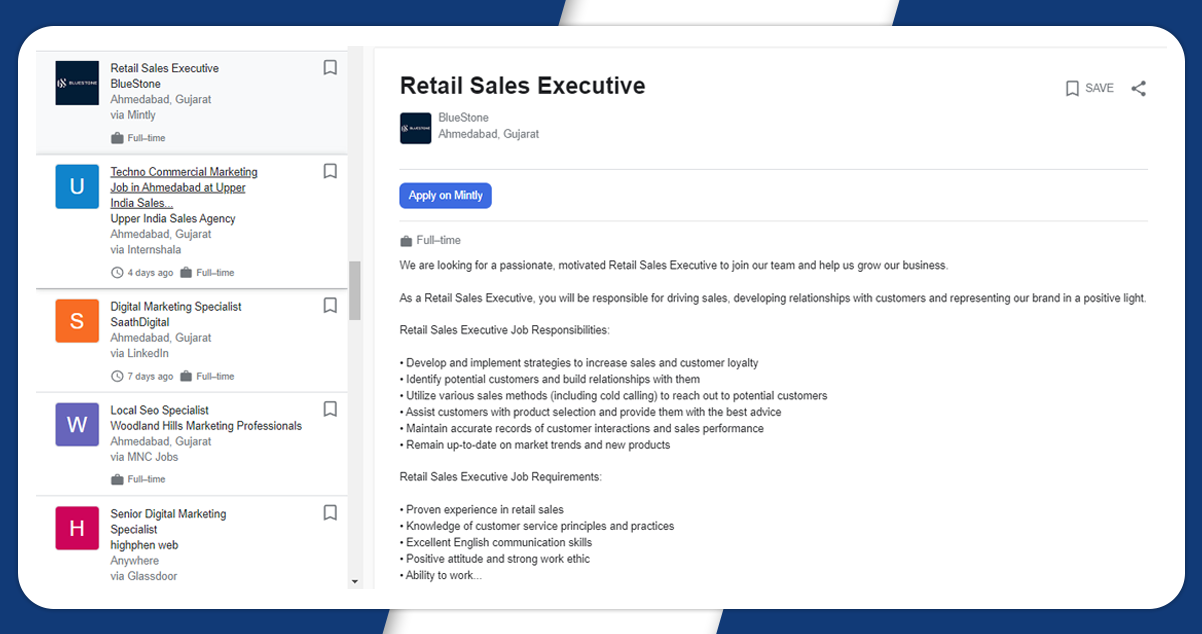
The output result will appear like this:
Conclusion: Finally, we have done web scraping of the Google jobs organic results with Nodejs. It will give complete detail on the type of jobs, company name, location of the company, etc.
For more information, get in touch with iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile app data scraping service requirements.