
GTIN represents Global Trade Item and is marked next to the product’s barcode. It is also known as product id and represents 13 digits. It represents EAN in Europe, and in the U.S., it is UPC. Every product has its unique GTIN number, and the manufacturer generates it. These numbers follow international standards and are formed by an international non-profit organization.
‘Moreover, GTIN is compulsory in most countries. These countries are Brazil, Australia, Italy, France, Japan, Spain, Switzerland, etc.
Most of the mass-produced products have a unique id, leaving the self-made products having IDs from GS1.
The GTIN is available next to the barcode on the product packaging. GTIN checking ensures that they are correct and updated. The data need to be very accurate. This Google will help understand which products are for sale.
GTINs are the numerical representation of the product’s barcode. It can be 8, 12, 13, or 14 digits long. Different types of GTIN represent where in the world the product has come from. The types of GTIN that currently exist are listed below:
The four different types of GTIN in use are:
Moreover, regardless of digit numbers, every GTIN has the same structure. It comprises of Item reference, Company Prefix, and a Check Digit. In the case of GTIN-14, the additional indicator requires that says whether the product is an item or case.
The GTIN-8, 12, and 13 represents as GTIN 14. They are left justified with zeroes.
For example, the GTIN 12 number 012345678907 becomes 000012345678907 in GTIN 14 format. Two additional zeroes get added to the left of the number to bring its count to 12 to 14.
Several shopping engines like Google Shopping and Amazon Marketplace use GTINs. They contain nearly all GTINs that are available in the world. A GTIN number is compulsory whenever you upload your product using a data feed on any of these platforms. The platform will automatically reject your product if you don’t provide a GTIN number or insert the wrong one.
GTINs make the most relevant match between the user’s search and product availability. With millions of products listed online, how will the engine display the right product you search for? It is only because of the availability of GTIN numbers. It also helps users to compare products and offers a more feature-rich shopping experience.
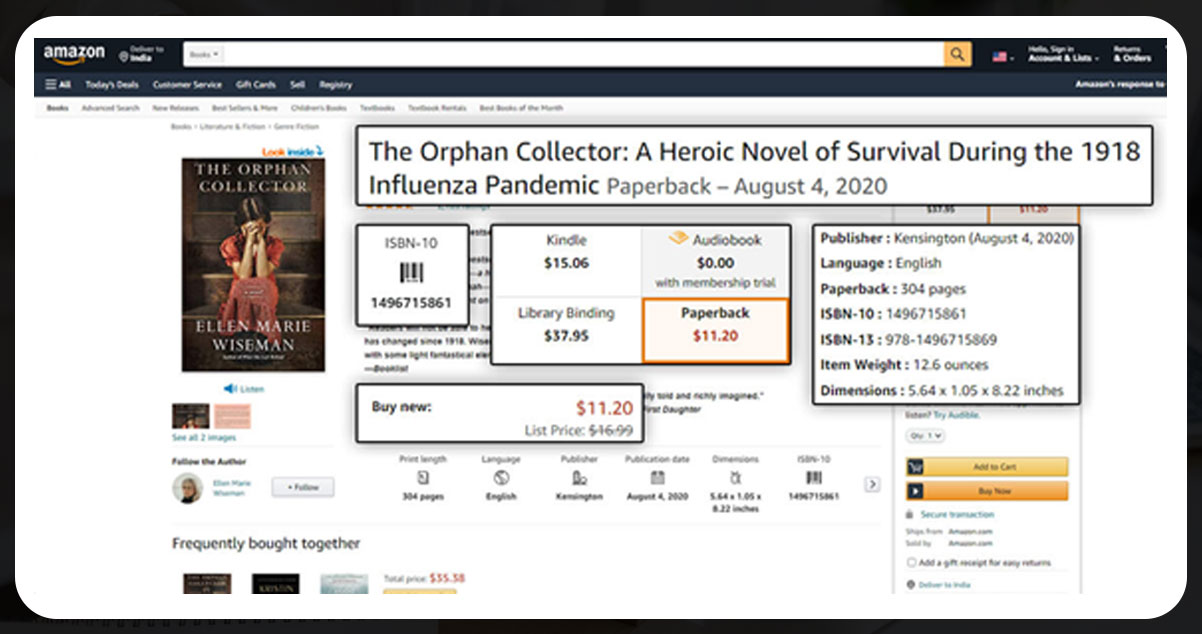
Here we will provide details on how to scrape GTIN or ISBNs from Amazon iWeb Data Scraping. We are performing the scraping procedure to scrape all products, especially books’ ISBNs, from Amazon.
Web data scraping is a perfect method to collect particular data from Amazon into JSON files or spreadsheets. Automate the monthly, weekly, or daily procedure to constantly update the data.
First, install the BeautifulSoup library through the pip module to scrape book information.
Now import all necessary packages you wish to use for scraping data from the website and visualize.

The URL mentioned here is the one that you will scrape:
The first step lies in discovering the total number of pages from the website. For connecting to the URL and fetching HTML, you require the following things:
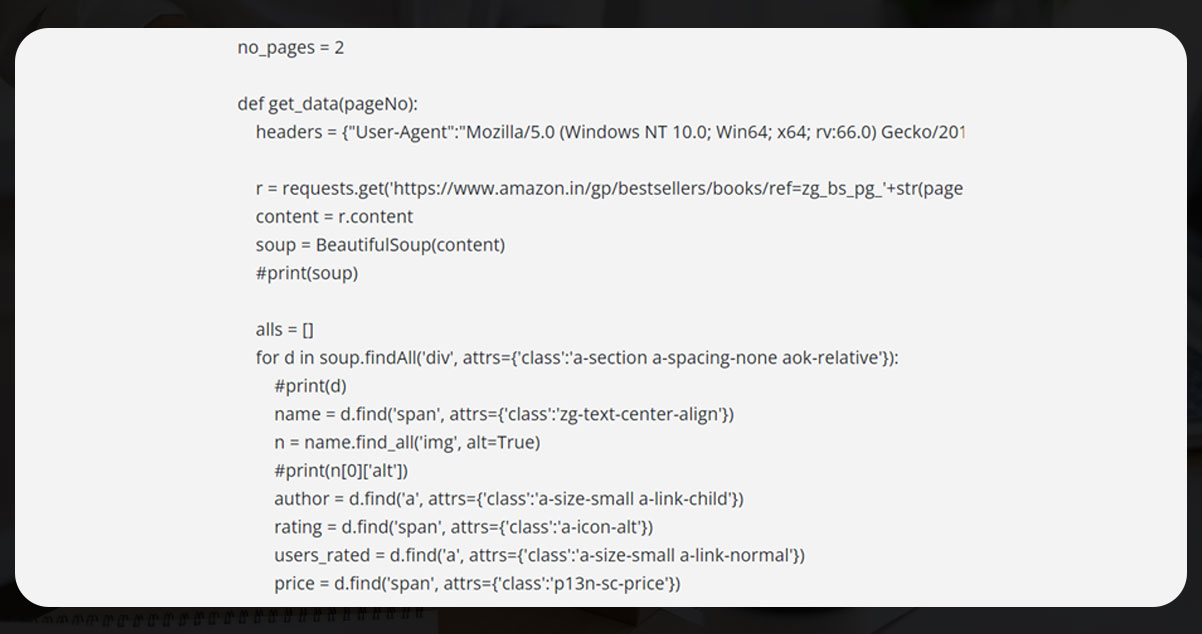
A get_data function will input page numbers like an argument.
A user-agent assist in bypassing detection as a scraper.
Now, using requests. get, identify the URL. Pass a user-agent header like an argument. Scrape the content using requests. get.
Here the data which we will scrape is:
The below image shows the parent tag.
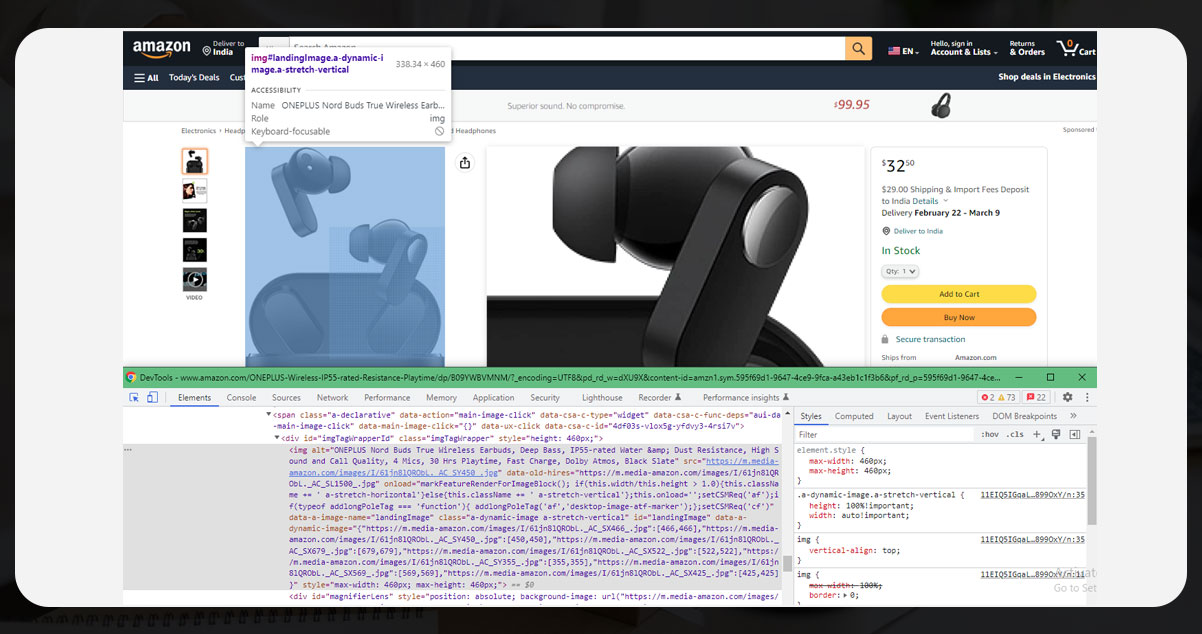
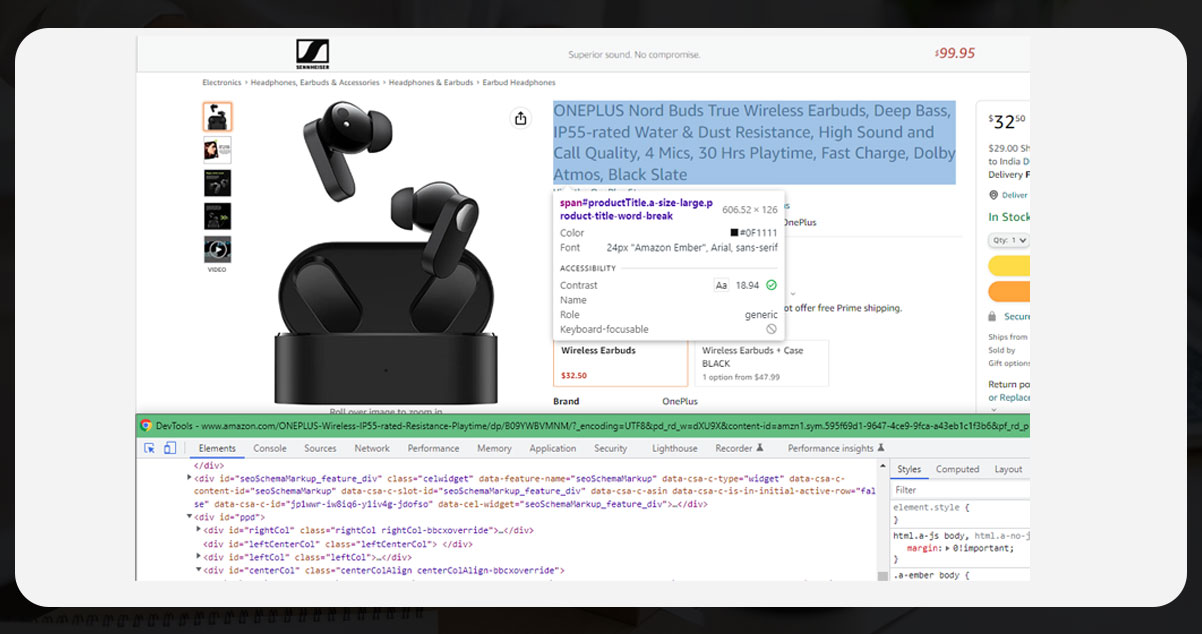
Similarly, you will need to obtain attributes for book name, author, ratings, price, etc. Visit the webpage that you wish to extract. Select the attributes and inspect them by right- clicking on them. It will appear as follows:
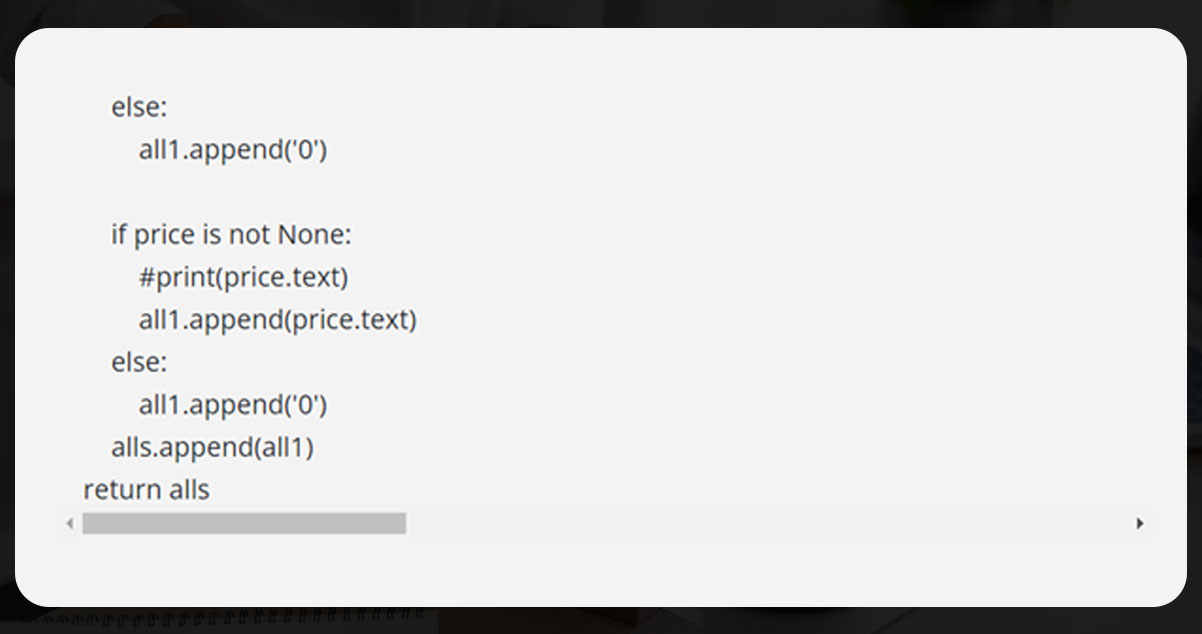
Now, to find the author names, apply if-else conditions.

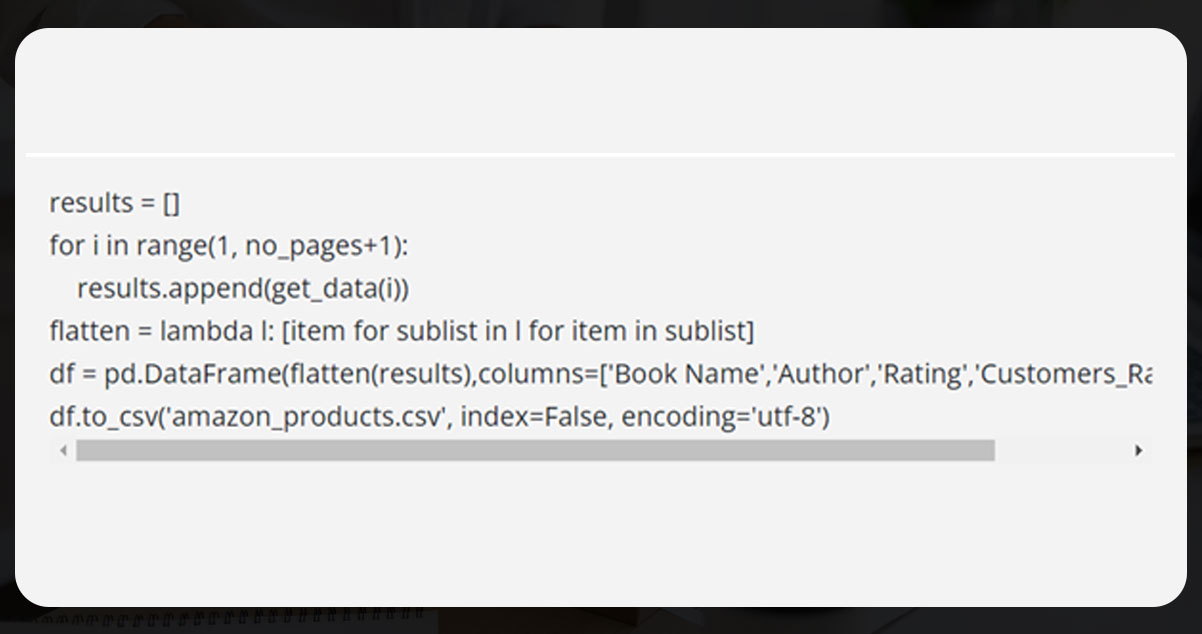
As the output available is in the nested form, flatten it and pass it to the data frame. Now save the data frame in a CSV file.
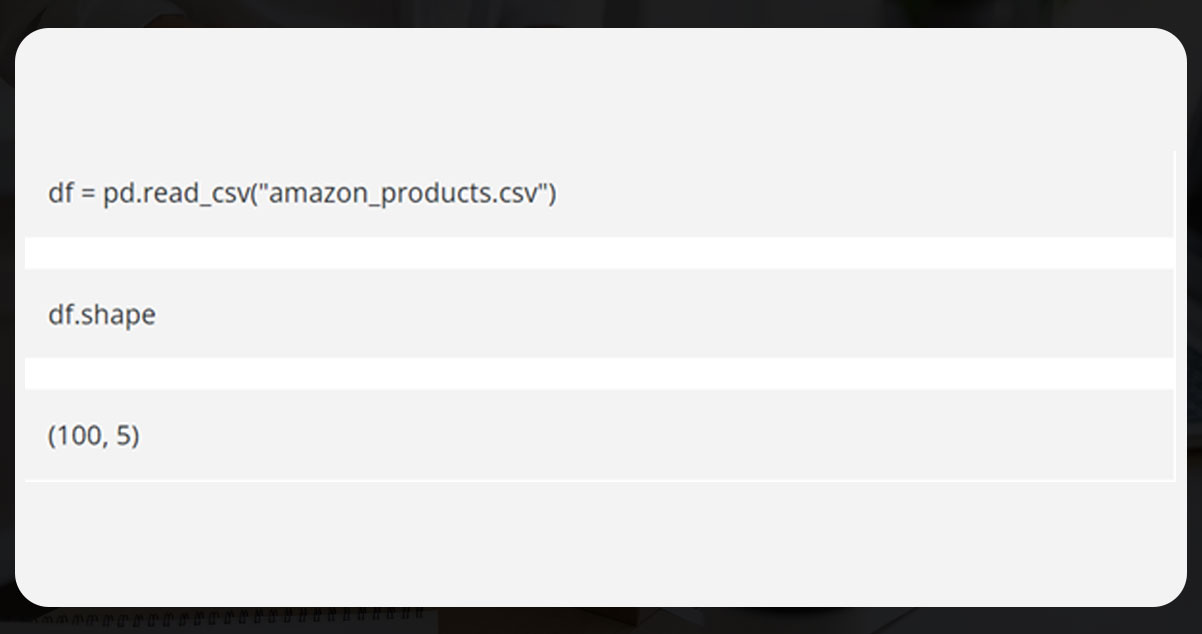
Load the CSV file and save it in the given cell.
This discloses that there are five columns and 100 rows within the CSV file.
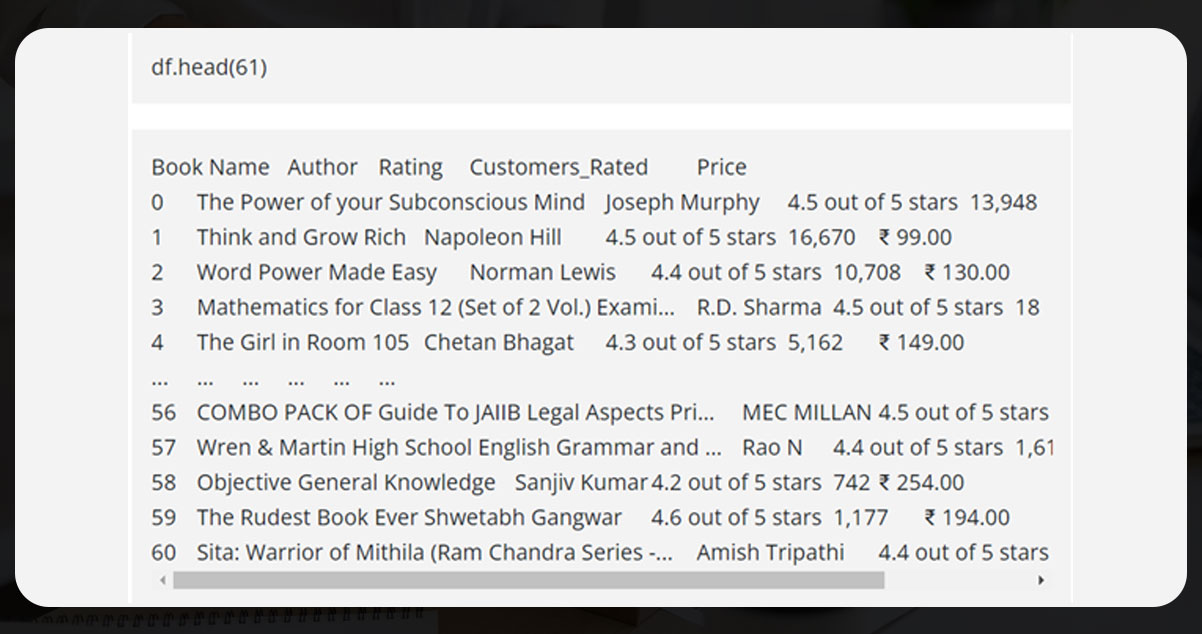
If you want to scrape the books with respect to ratings, keep only ratings and remove all other parts.
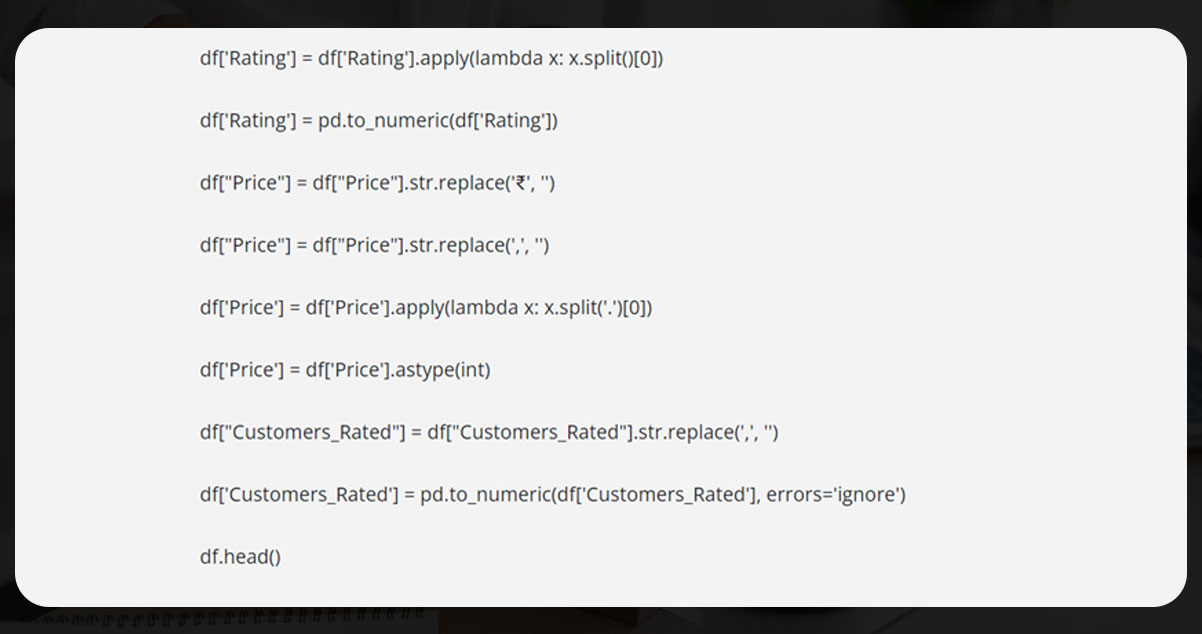
From the customers_rated column, remove the comma.
From the pricing column, remove the comma and rupees symbol and split it using the dot.
Now convert all three columns into an integer.

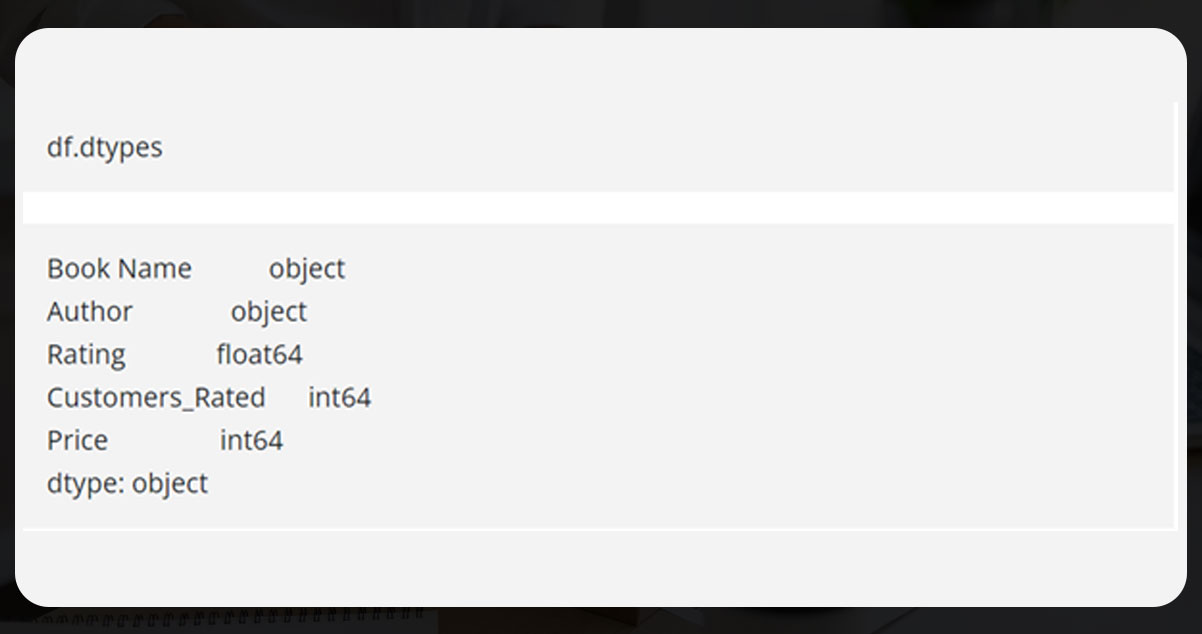
Now, verify the data numbers of the data frame.
Replace zero values with NaN.
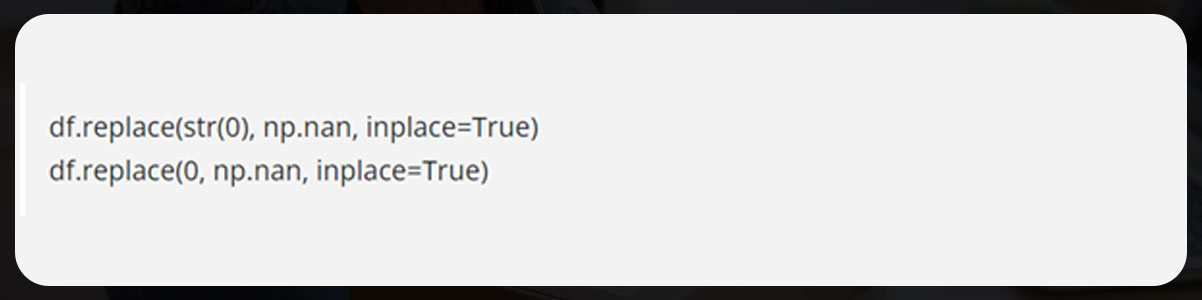
Now, count the total number of NaNs within the data frame.
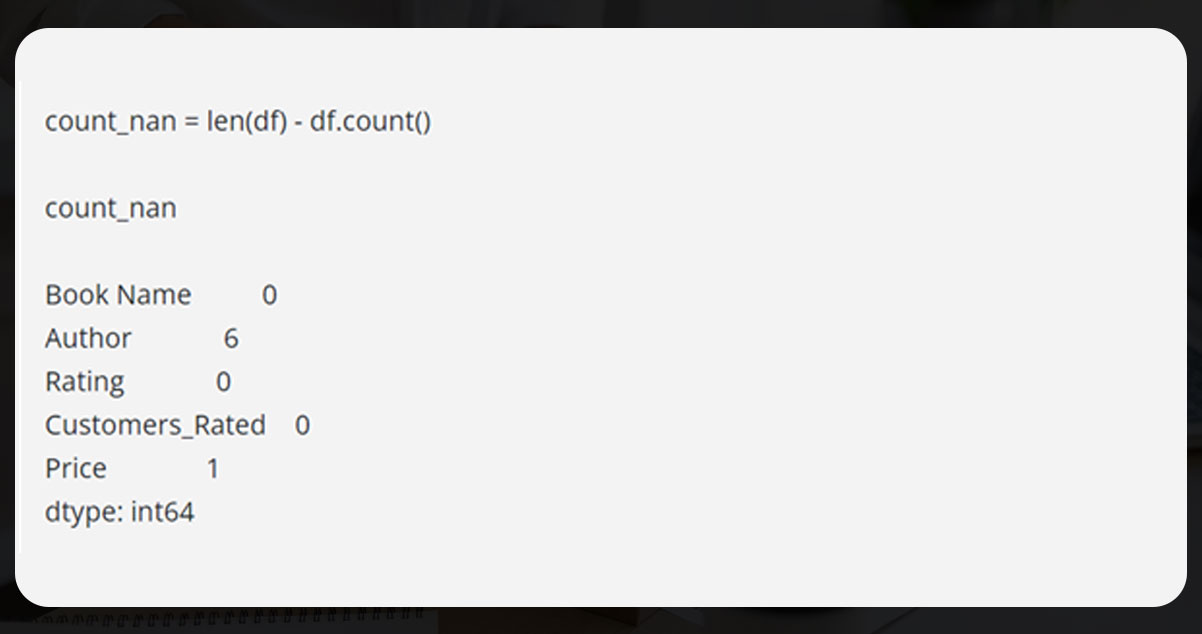
Thus, from the given output, you can find out that a total of six books do not have author names, and one book doesn’t have pricing information.
Conclusion: In the above procedure, we have tried to give a brief idea about how to scrape product GTINs or ISBNs from the website.
CTA: For more information, contact iWeb Data Scraping now! You can also reach us for all your web scraping services and mobile app data scraping requirements.