
If you're planning to sell your newly developed product on Amazon, you'll need to know the path to list your product on the platform to get maximum revenue. It will give you an idea of the potential challenges, how to mitigate them and what modifications are required in your product and marketing strategy, etc.
In this tutorial, we'll walk through the process of extracting amazon best seller list data using python to help you with your market research.
It is an automatic process to extract the desired data from websites in a usable format in large quantities for market research purposes.
Web data scraping is generally used for marketing purposes where businesses extract the data from the websites of their competitors like product/service prices, articles, and top-performing product details to plan a better marketing strategy. However, Data extraction is not only limited to marketing. It is also valuable for machine learning, SEO, and many more fields.
Amazon is an American company that works in online eCommerce business and cloud computing across the globe. On this platform, a huge number of enterprises, and brands, sell their products to their customers. For example, Books, Sports gadgets, pet food, etc.
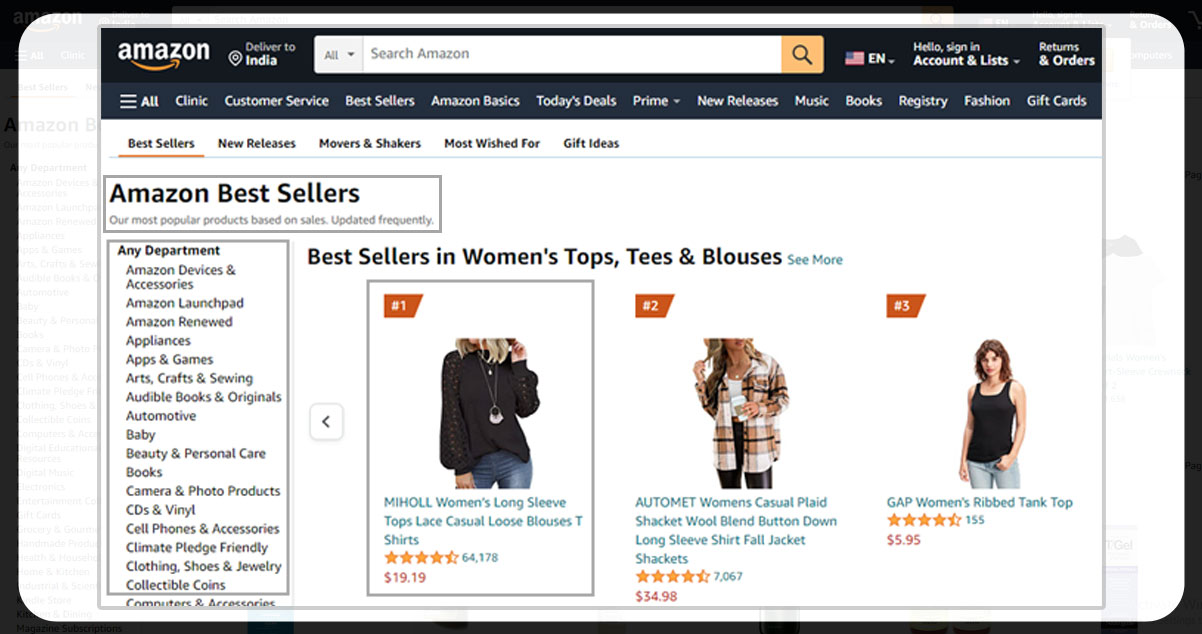
Here, best sellers are listed in alphabetical order and can be seen in Amazon's best sellers’ category. This page gives a list of more than 40 categories regrouped. Out of which, we will guide you to scrape amazon bestseller lists in different categories using python web scraping. We Will need to have python libraries Beautiful soup and Requests to crawl, parse and mine the data we want from the page to scrape Amazon best seller listings using python.
We will follow the below-given steps for our needs to run Amazon scraper using python.
Once the data extraction is done, we'll save all the data in CSV format, as shown below.

You can check the full reference code in the link below.
To run the developed code, you can go to the Run button at the top of the page and select the Run on Binder option.
Note: Each category shows 100 products on 2 pages, with 40 categories of each department being shown. But a few pages are not accessible due to captcha issues.
Install request and beautiful soup libraries with pip command, respectively since these libraries are mandatory for extracting the data from the webpage.
Download and save the source code of the HTML page using requests and beautiful soup python libraries to extract product categories URLs.

To download the page, we'll use the get function from the library requests. Further, we'll define the header string of the user agent so that servers will be compatible with the application, OS, and requesting version. It is helpful to show that we are not scraping the data. The command requests.get gives the output containing data from a targeted webpage. While the status_code property checks if the output was accurate or not. To check that, we can manually verify the HTTP response code, which lies between 200 and 299, for successful output.

We can use this response.text to see the downloaded page content. Adding to it, we can also check the length of the downloaded data using len(response.text). In this example, we've just extracted the first 500 characters using the print command.
Now, let's store the extracted file in an HTML extension.
with open("bestseller.html","w") as f:
f.write(response.text)After saving, we can check the file using the File>Open menu in jupyter and open the bestseller.html file from the files shown on the screen.
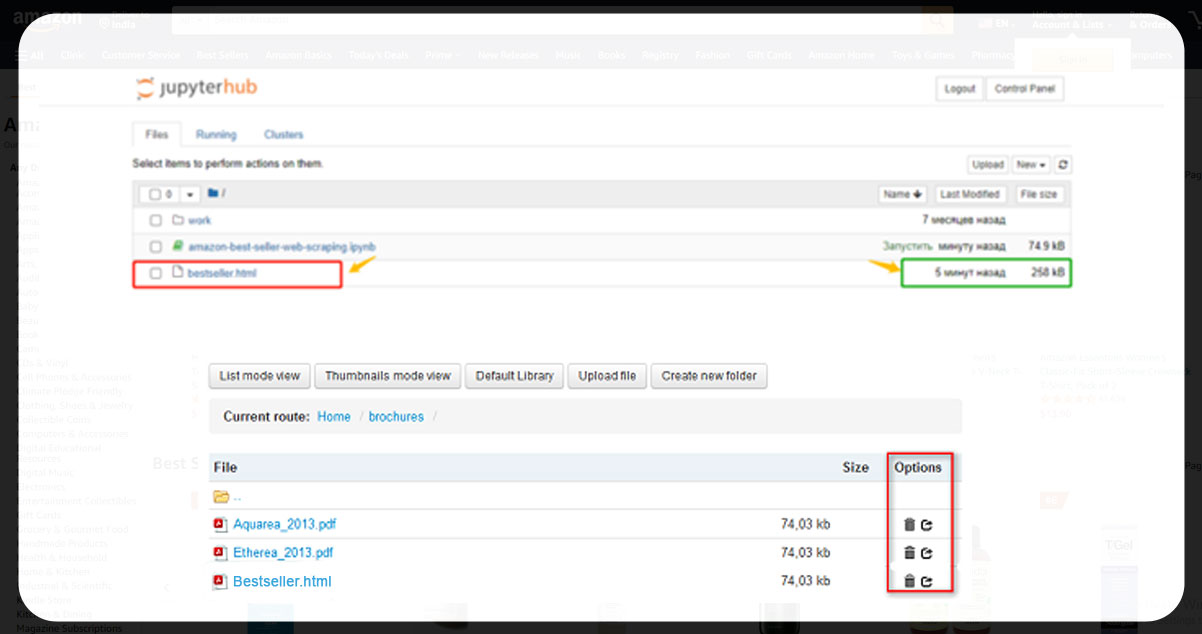
To know whether the extracted data has been saved or not, there is an option where you can check the file size. If the file size is around 250 kB, the process is successful. However, if the file size is 6.6kB, means the process has failed. Reasons to fail could be security or a captcha.
This is what we can observe when we open the file.
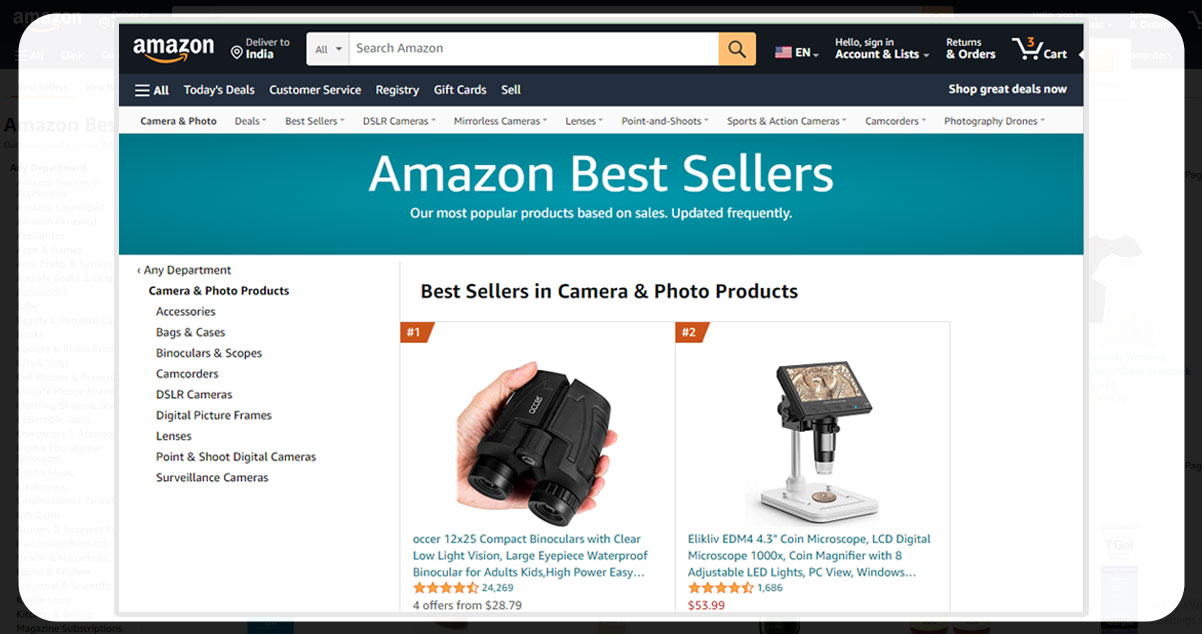
Though this looks like the original web page, it's just a copy of that page, and we can't open any link from the copy. To check and customize the source code of the saved file, click File>Open in Jupyter, then opt for the .html file for this operation from the lists and click on the edit option.
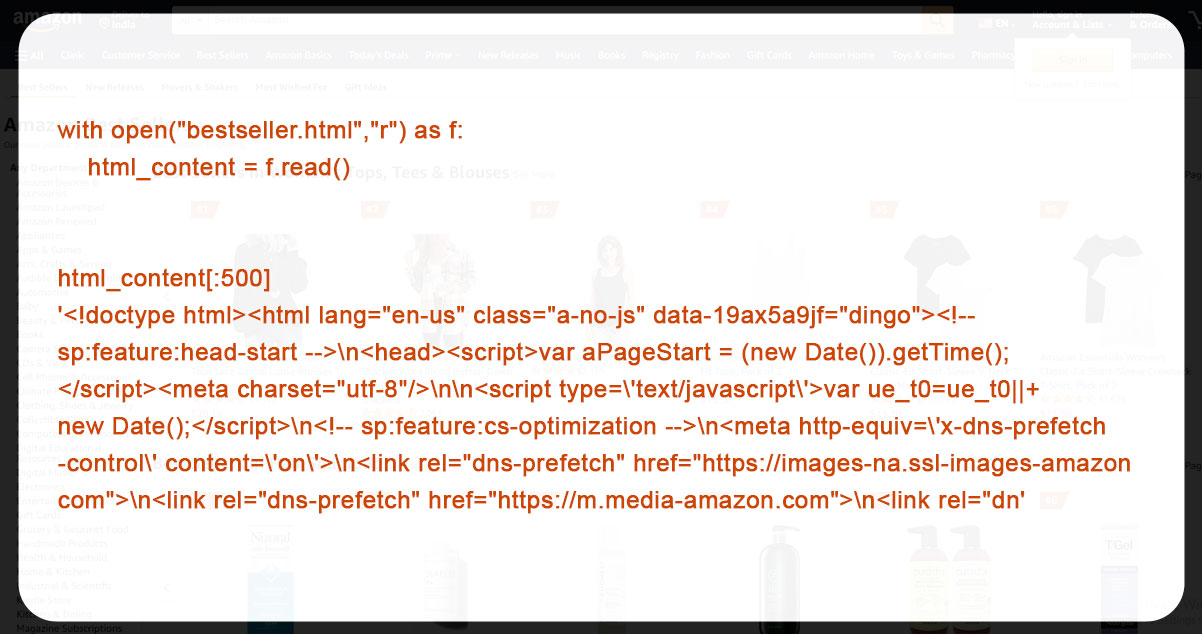
So far, we have just got the data for the first 500 characters. Now, we'll move ahead to parse the web page to check the type using BeautifulSoup.

Now, let’s use the below code to access parent’s tag so that we can get the attributes for all info data tags.

After finishing the above process, let's find a list of item topic and categories, their titles and URLs, and store them in the device.
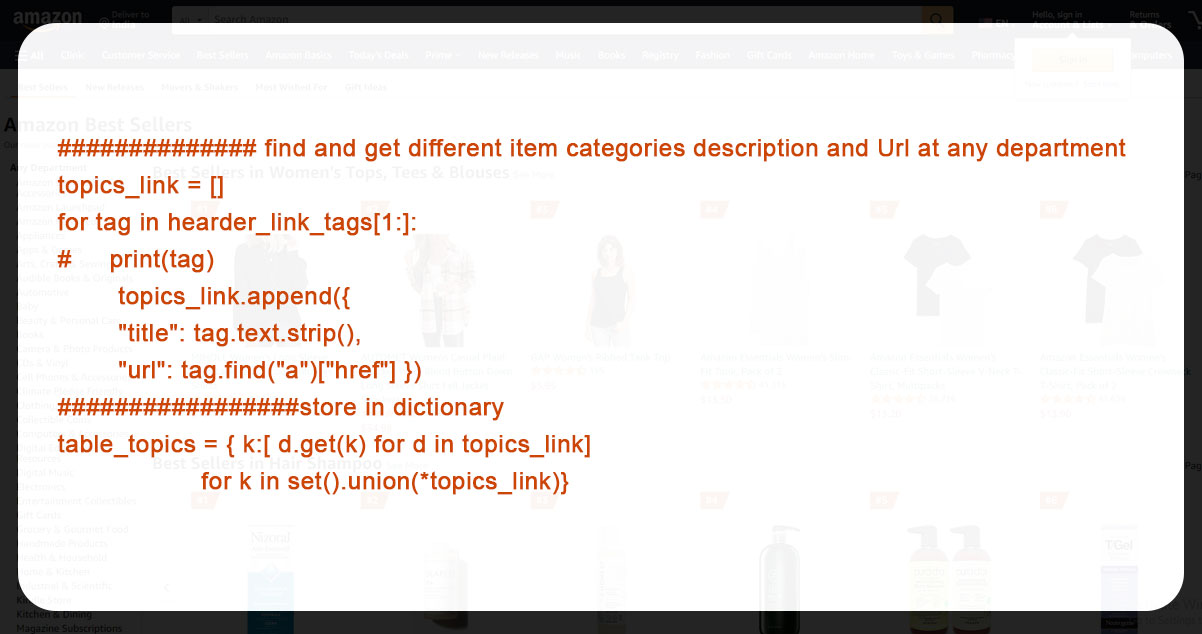
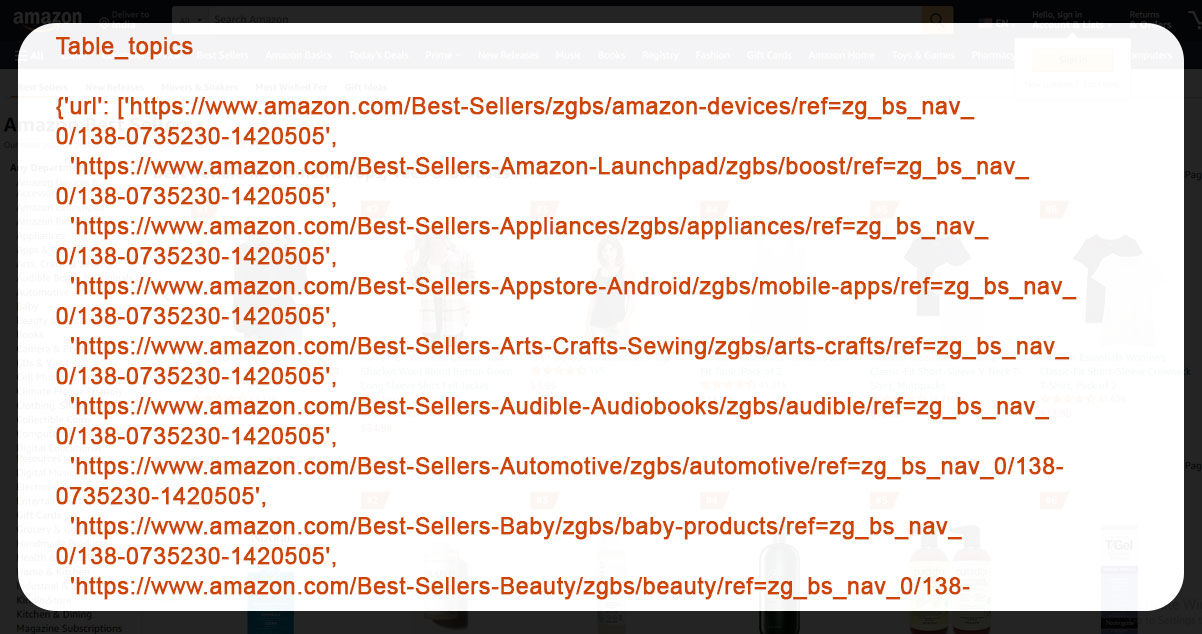


Here, we've extracted the list of 40 bestseller product categories accurately.
To avoid access being denied by a captcha on several pages while extracting data; we’ll import the time library to apply the sleeping time of a few seconds.
import time
import numpy as npWe are going to define a function, namely parse_page, to extract and parse every single page link saved from the top ranking best-selling product of any category.



If the parsing fails in the first attempt, we'll have a provision for that too. To achieve this, we will define a function reparse_failed_page and will apply it whenever the first attempt fails. Further, we will keep it in a while loop to repeat until it gives the output.

To get the maximum number of pages while parsing, we have defined the function parse to achieve 2 levels of parsing.




Here, we have successfully mined 76 pages out of 80 which is good enough.
In this part, we have defined a function to scrape the data fields like product description, min and max price of the product, product reviews, image URL, product rating, etc. this data as bees extracted using an HTML element from the above-parsed data.
An HTML element is a tool consisting of child nodes, tag names and attributes, text nodes, and a few other factors. This can be used to scrape data. Further, the elementary can also manipulate HTML.
The easiest way to know an HTML tag is to understand how a device knows what content to display on the screen, where to show it, and how to show it. Further, differentiating between titles, headings, paragraphs, and images. All this is done using HTML tags on the computer. It is a web-based command to push browsers to take action on something.
HTML tags have syntaxes like HTML, body, head, and div. It is to show their meaning, and define how the browser will perform as per the command considering that these tags also represent keywords.
Talking about attributes of HTML like href, src, alt, class, and id, they are modifiers of HTML element type. They are used inside opening tags to manage elements.
Child nodes are elements nested in another element.
We can use different types of HTML tags and attributes in single-page content. The below picture is on HTML tags and attributes to find the price tag information of the product.
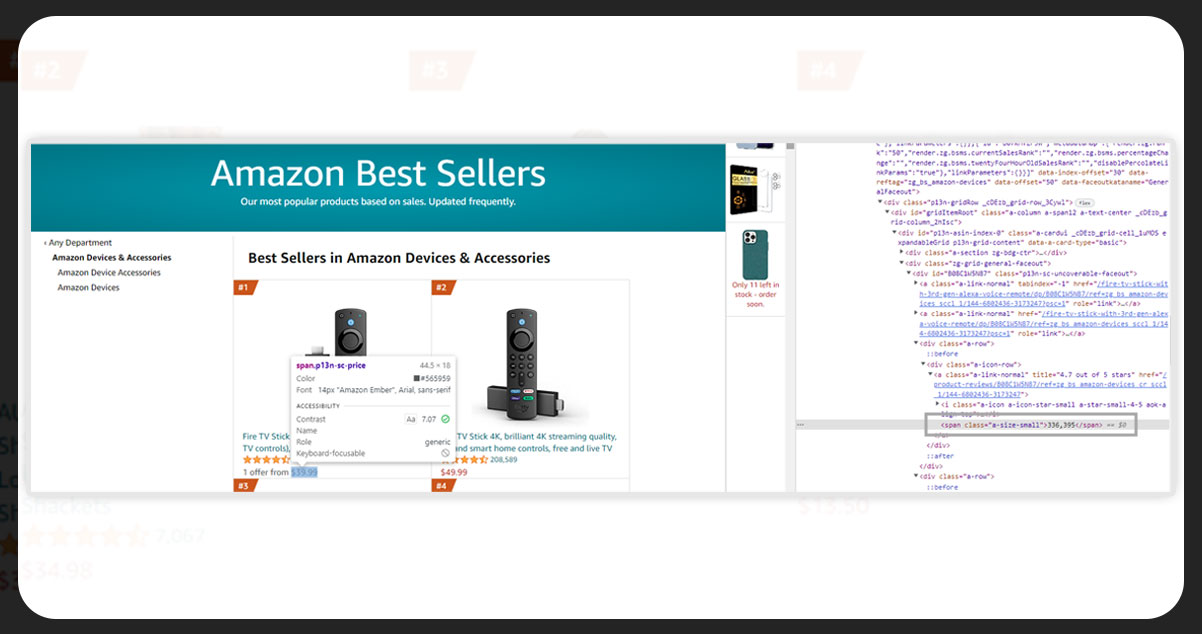
To get the product description, we will define get_topic_url_item_descriptuon as shown in the below code.

After that, we have defined get_item_price to scrape minimum and maximum price of the products.


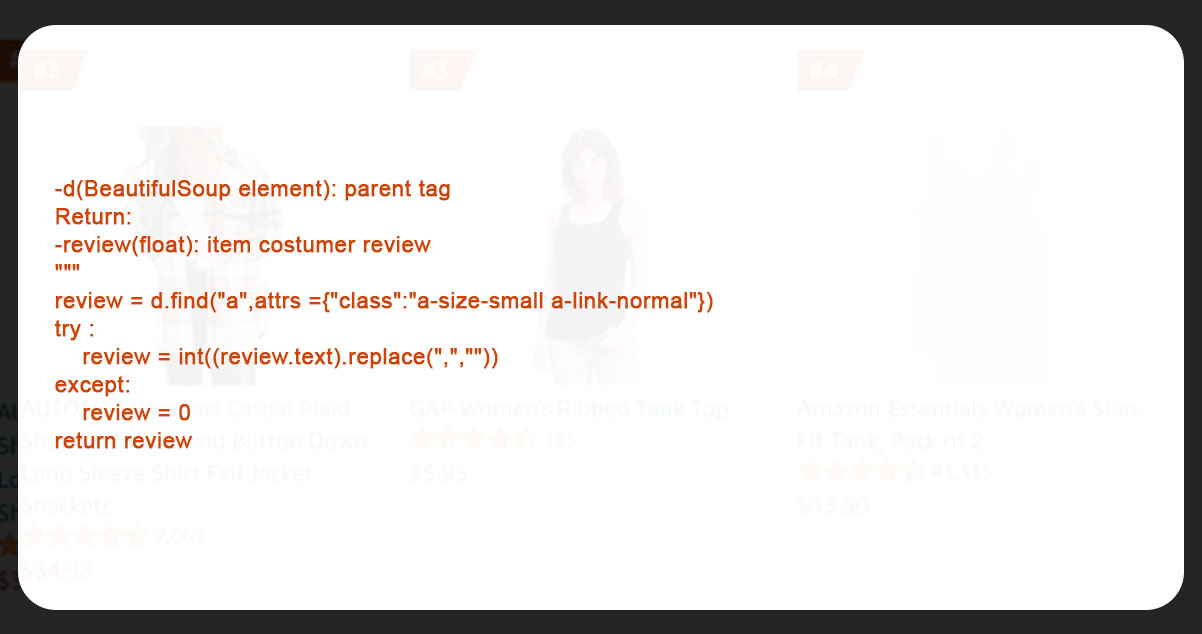
Now, we defined get_item_review and get_item_rate functions to get product reviews and rates.

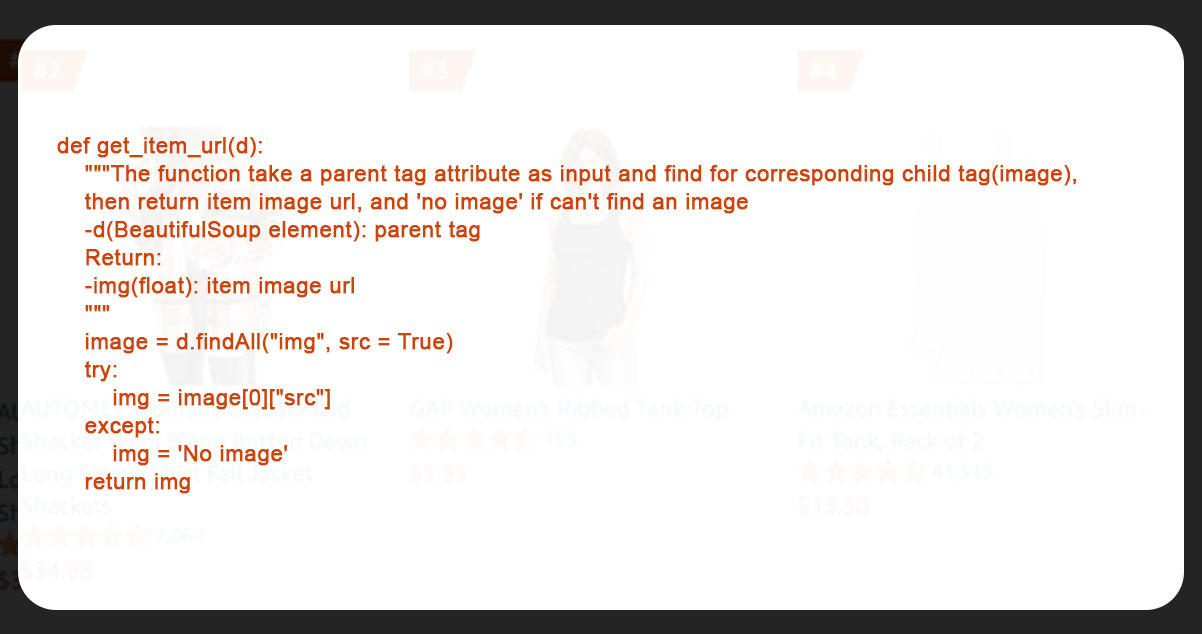
Lastly we defined get_item_url to mine the image URL of the product.
Thus we have extracted all tube relevant data for the bestseller products and stored them in the usable format.
We have designated the function get_info to compile all the product data in a python library.


After a couple of parsing attempts, we got the maximum products data from amazon. Now we will store it in a data frame using pandas
Let's begin to store the data in the data frame.
dataframe = pd.DataFrame(data)
We got the data in about 3800 rows and 8 columns using the process. Now let's save it in a CSV file using pandas.
dataframe.to_csv('AmazonBestSeller.csv', index=None)Here is how you can access the file - File>Open
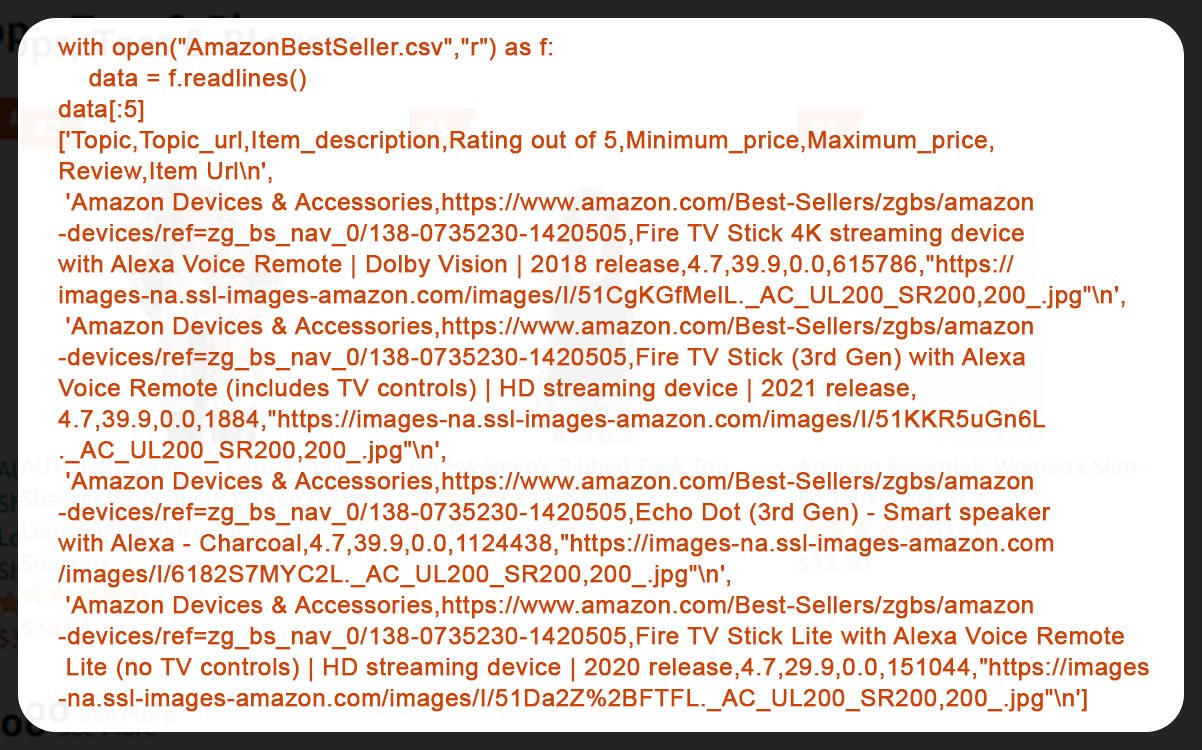
Now, Let's open the CSV file to print the first 5 lines from the data.
Finally, let's have a look at the product with the highest number of reviews by customers.

In this post, we have gone through the below process to extract amazon bestseller listing using Python..
Here is what the CSV format code will look like by the end of the project.

That’s it for this project. If you still are not getting the process, or you have a time limit for your business, iWeb Data scraping can help you with web scraping services, you are just a single mail away from us.