In this article, we will scrape & automate job data from websites. Both of these tasks are achievable using several tools and libraries. Let’s have a look at each one of them.
Web Scraping: Web Scraping is a method that enables data extraction from websites and collecting them on spreadsheets or databases on a server. It is helpful for data analytics or developing bots for several purposes. Here, we will change it to small jobs scraper that can automatically run and fetch the data and help us see new scraped job offerings. The Job automate data scraper is the most used tool for this purpose.
Several different libraries help you achieve this task successfully:
Python: Both Scrapy and BeautifulSoup are the most popular used libraries for web scraping. The role of BeautifulSoup is to provide a simple interface for extracting data from HTML and XML documents. Scrapy, on the other hand, is a robust framework for building web spiders and crawling websites.
Node.js: Regarding web scraping in Node.js, Cheerio and Puppeteer are popular choices. Cheerio is a jQuery-like library that enables one to traverse and manipulate HTML. Puppeteer is a headless browser automation tool that is helpful for more complex scraping tasks.
Ruby: To perform web scraping in Ruby, Nokogiri is a commonly used library. It provides an easy-to-use interface for parsing HTML and XML documents and extracting data.
Android Automation: When it comes to performing automating tasks on Android devices, several tools and frameworks are helpful:
Puppeteer: a Node.js collection offers advanced API to switch Chromium over the DevTools Procedure. It possesses advance JavaScript and browser features.
Playwright: This library provides cross-browser automation via a single API.
Appium: Appium is an open-source tool for automating mobile apps on Android and iOS platforms. It supports multiple programming languages, including Java, Python, and Ruby, and allows you to write tests that interact with your Android app.
Thus, when it comes to scraping job websites, the best and most affordable option is to seek professional help from Job recruitment data scraping services. They are well equipped with the tricks and latest techniques that help obtain scraped job posting data and get the most relevant ones based on your needs.
Those, as mentioned earlier, are some of the few examples of the tools and frameworks required for web scraping job postings Python and Android automation. Depending upon your preference and specific requirements, you choose the one that best suits your requirements.
To scrape job recruitment data online, the site we are supposed to scrape is remoteok.io.
Installing Libraries: We use Puppeteer to scrape job data from the websites. To automate the scraping, we have to run the script every day. It is possible to use CronTab, a Linus time job scheduler utility. It is a headless browser API that offers the Chromium browser with easy control, similar to the other browsers.
We will use a framework generator to frame an project and the Pug template engine to show the scraped jobs via the Express server.
Inspecting the Site: The first and foremost step before scraping any site is to inspect every detail of the site content to know the process of building the script. However, scraping is a technique that mostly depends on understanding the website structure, like, how DOM is structured and which HTML Elements & attributes are important. We are using ChromeDev Tools or Mozilla Dev Tools for inspection.
First, take a glance at the Puppeteer Docs to know the function. Then, introduce a browser on Puppeteer doc and then scroll to the job page on theremoteok.io. We will save all the jobs in a list format.
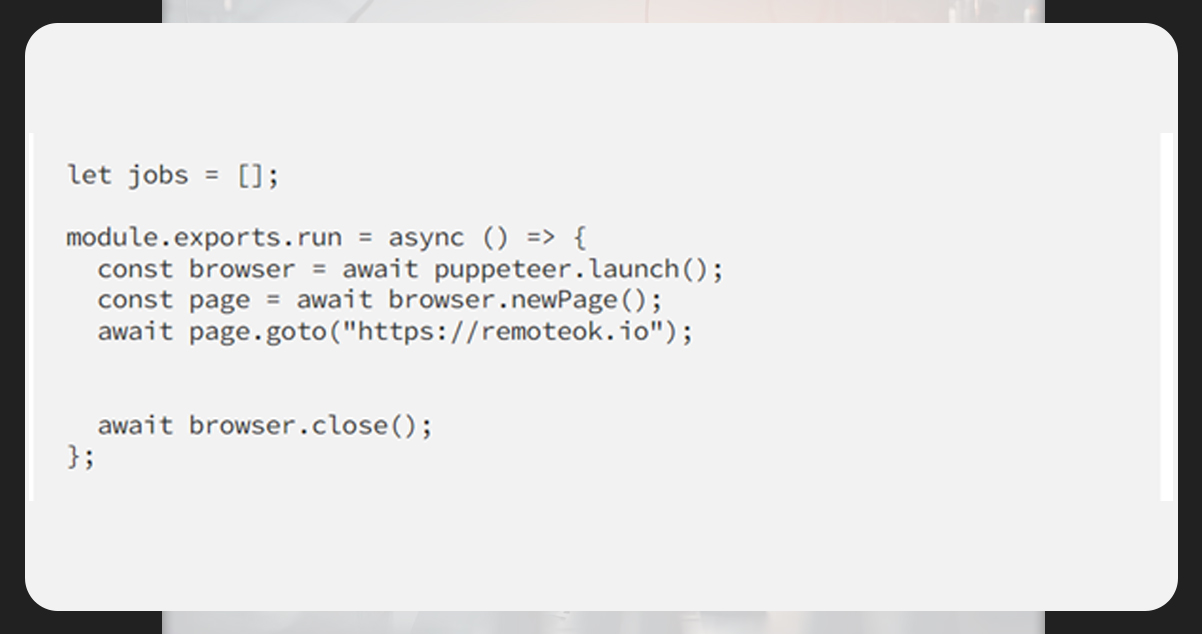
All async codes are handled using async/await. We will also export the primary function to the modules run to be used from outside and called from our server.
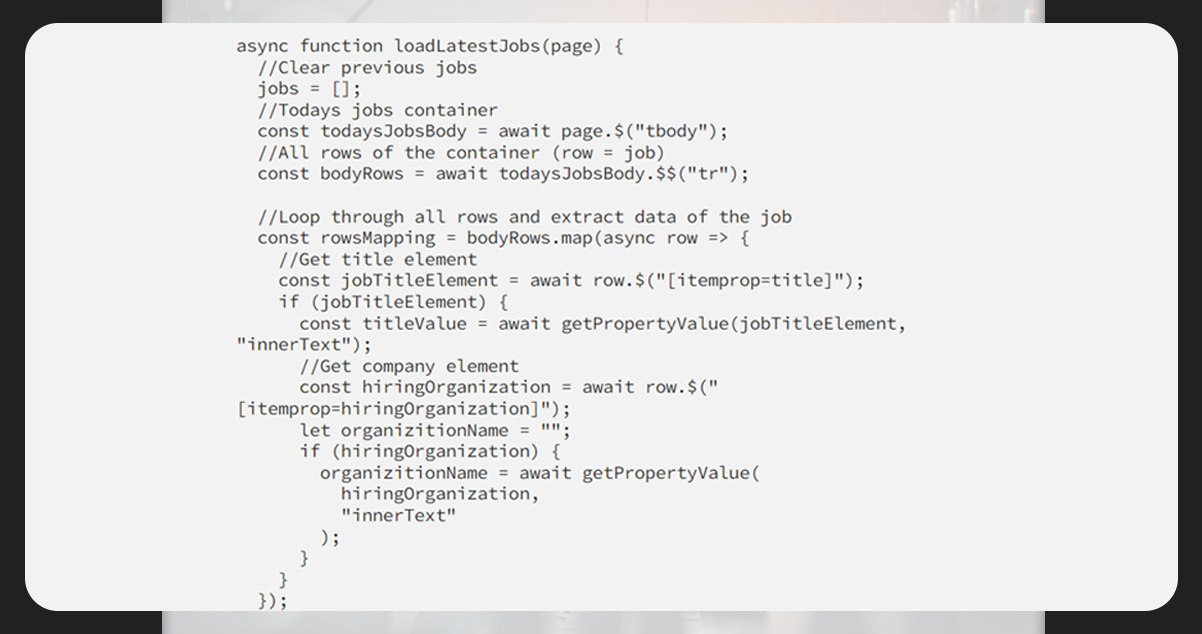
Next, we will look for the job and extract the Title, Company, and other details.
The jobs are encased in tbody (table), each under tr.
The title and company have attributes (itemprop=titlke) and (itemprop=hiringOrganization). Hence, it is easy to extract those via selectors.
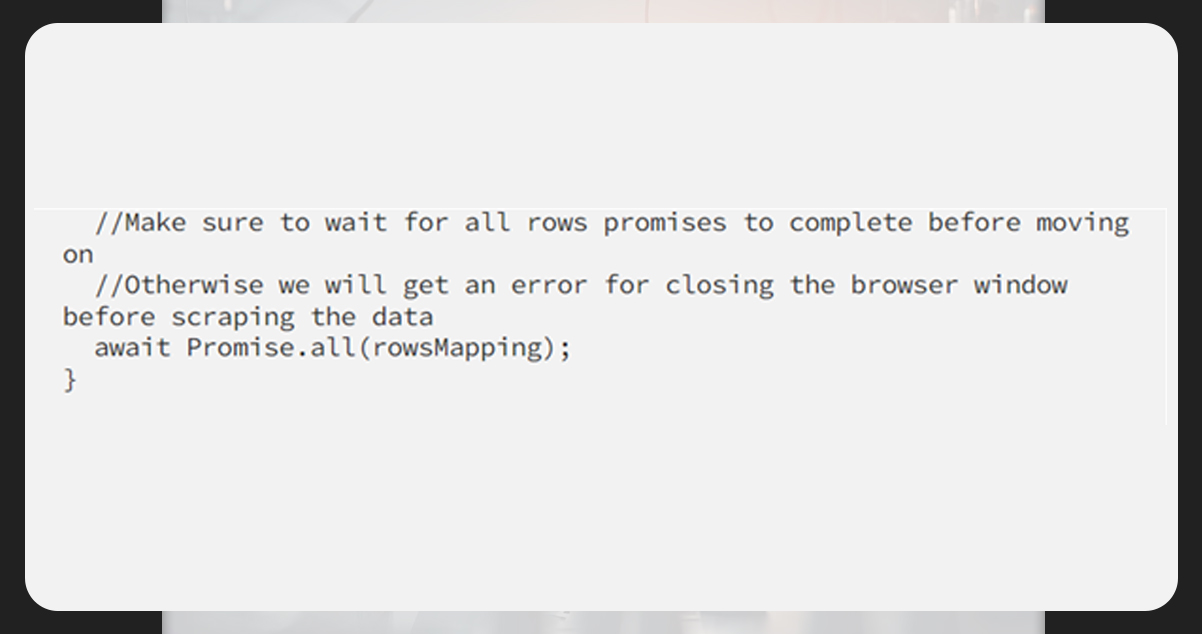
The next step is to get all the technologies related to a specific job. Each technology lies within a hyperlink (a) element and all tags are within the .tags container.
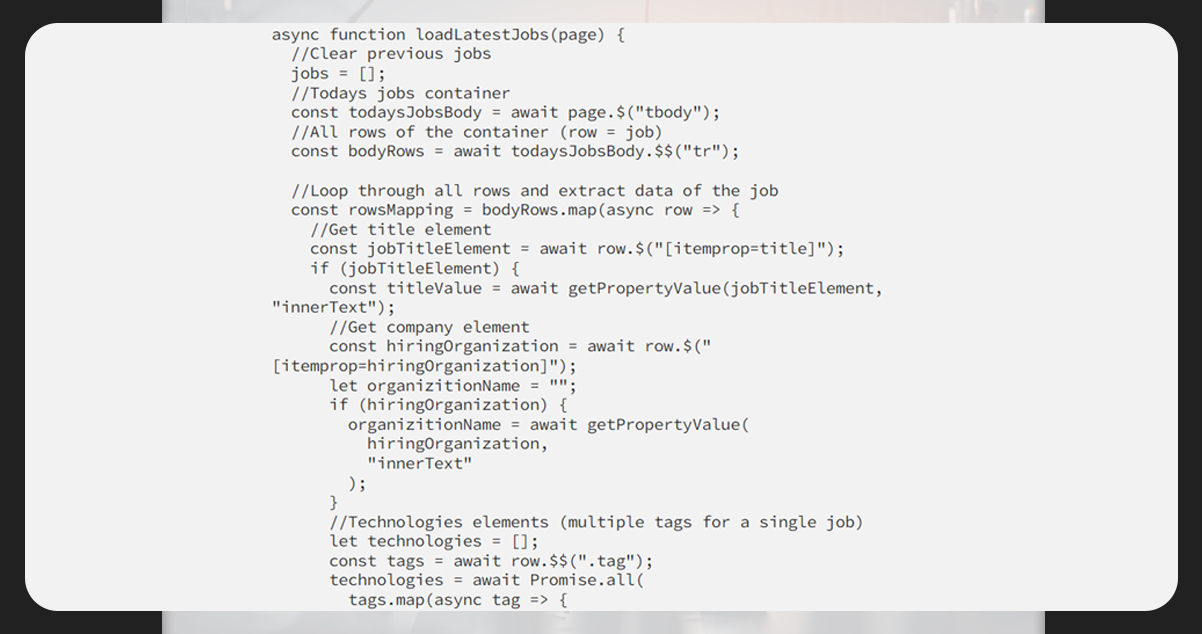
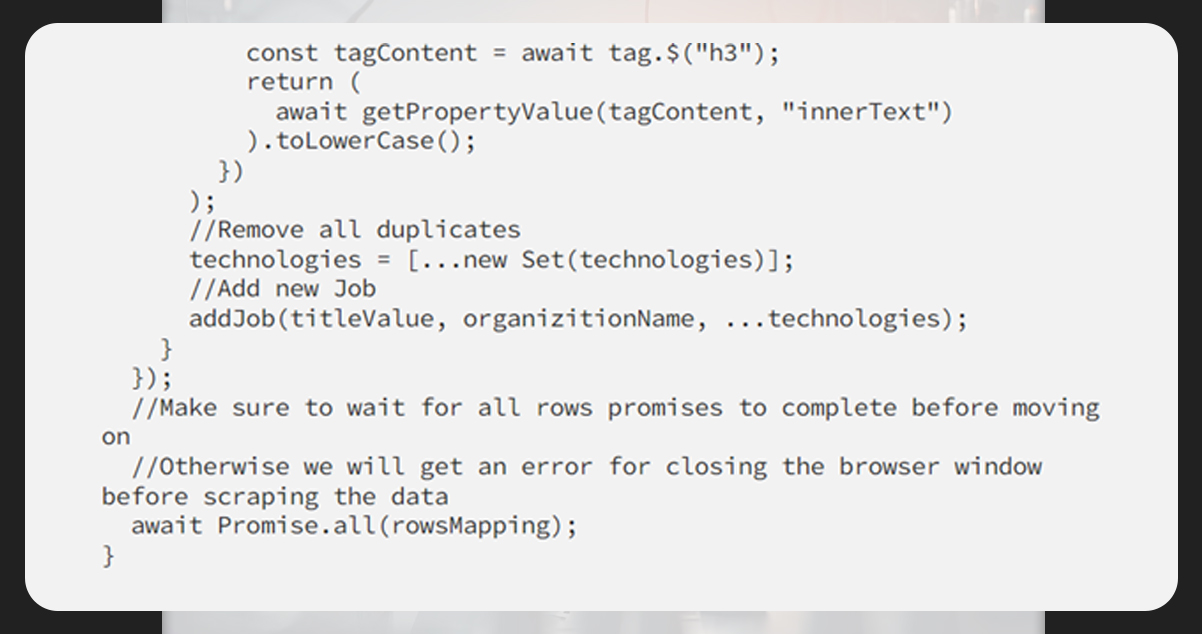
Ensure to add a helper function for adding new jobs to the list of jobs having titles, companies, and other details.

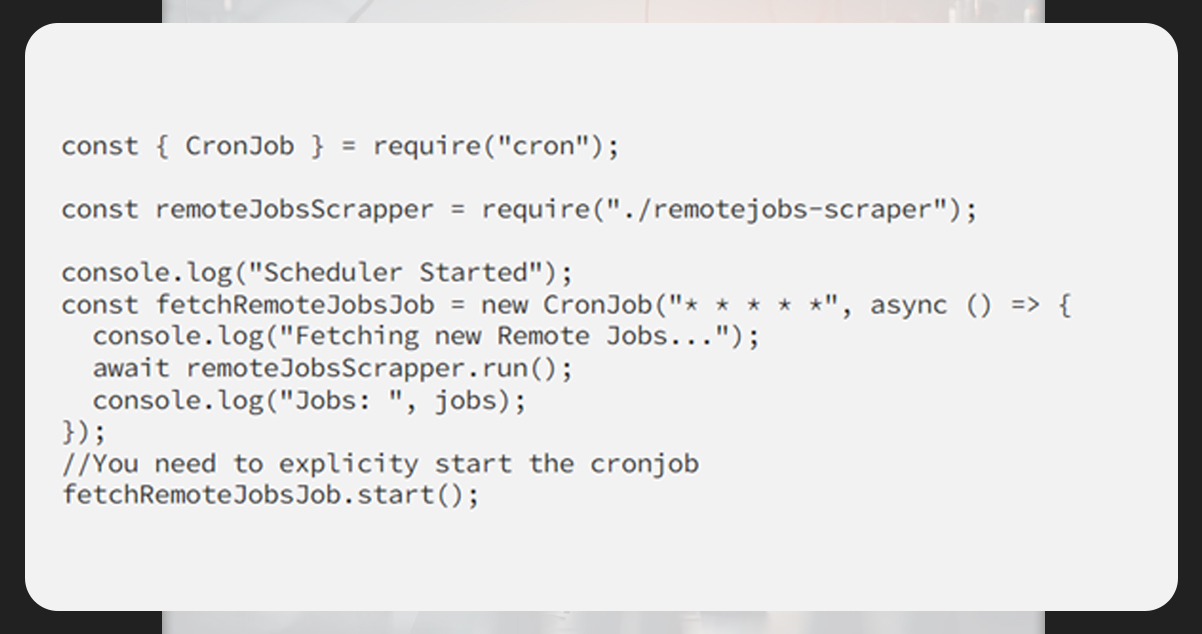
For running a script on a regular time interval, you can schedule scripts using Crontab.
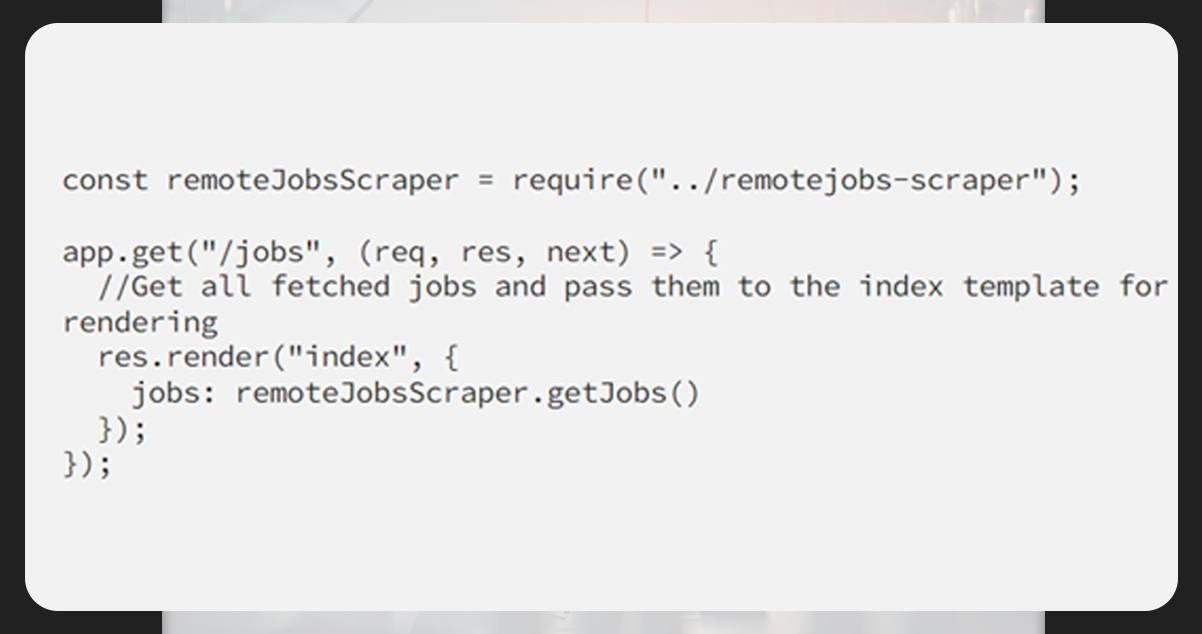
Within app.js, add a new get route on the server on the jobs route.
Ensure you import the pre-defined module to begin the cron job once the server is all set for running.
The cron job will automatically be inclined of as soon as the server shutdown.
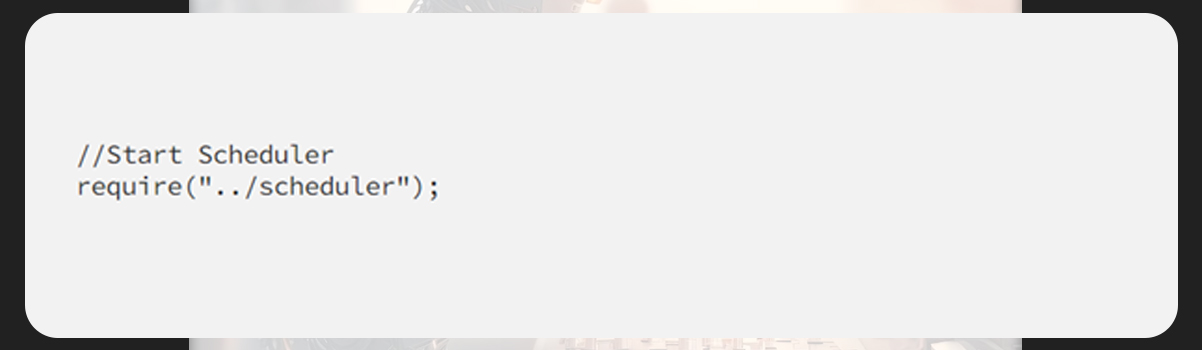
Next, for job displaying, we will use the Pug template.
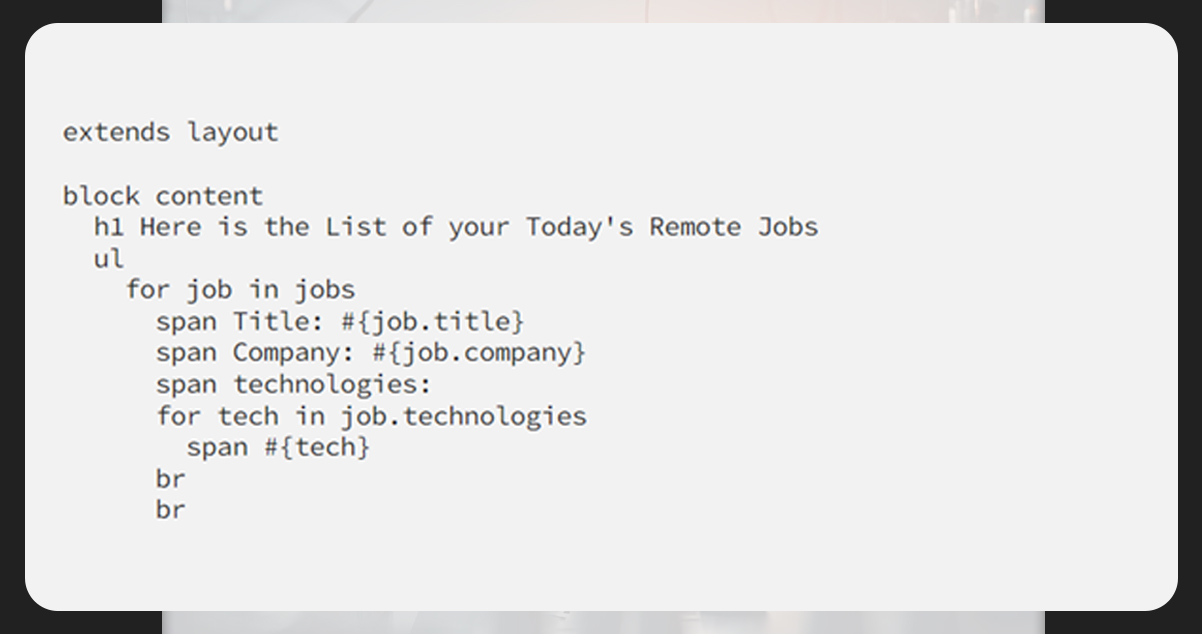
Now, let’s integrate the saved data into the database, Postgres.
To start with the Postgres database, we will install psycopg2

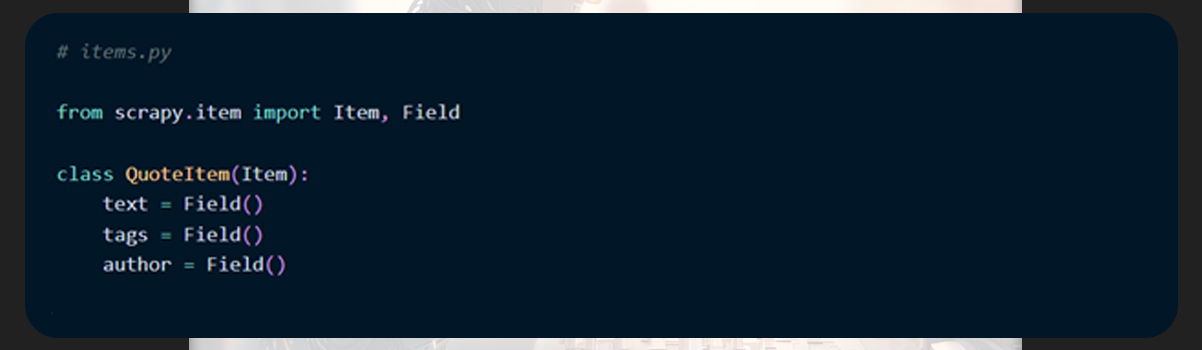
Open the pipelines.py file and then set up the pipeline.
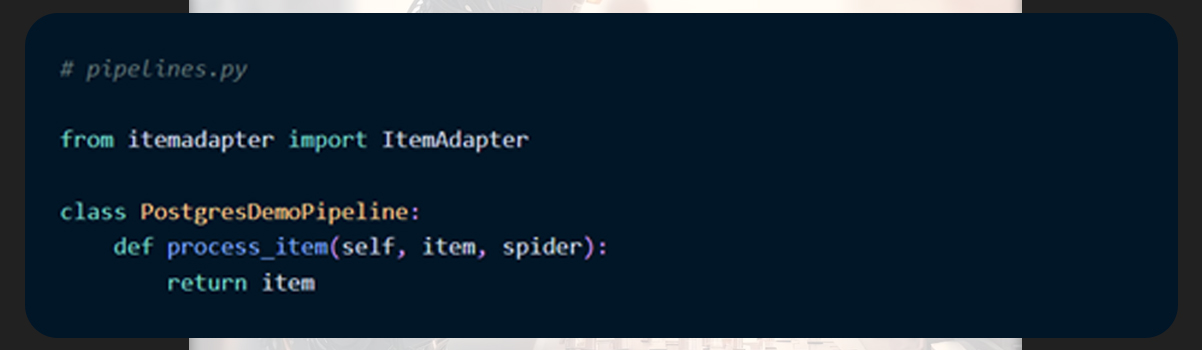
Now, organize this empty pipeline for data storage.
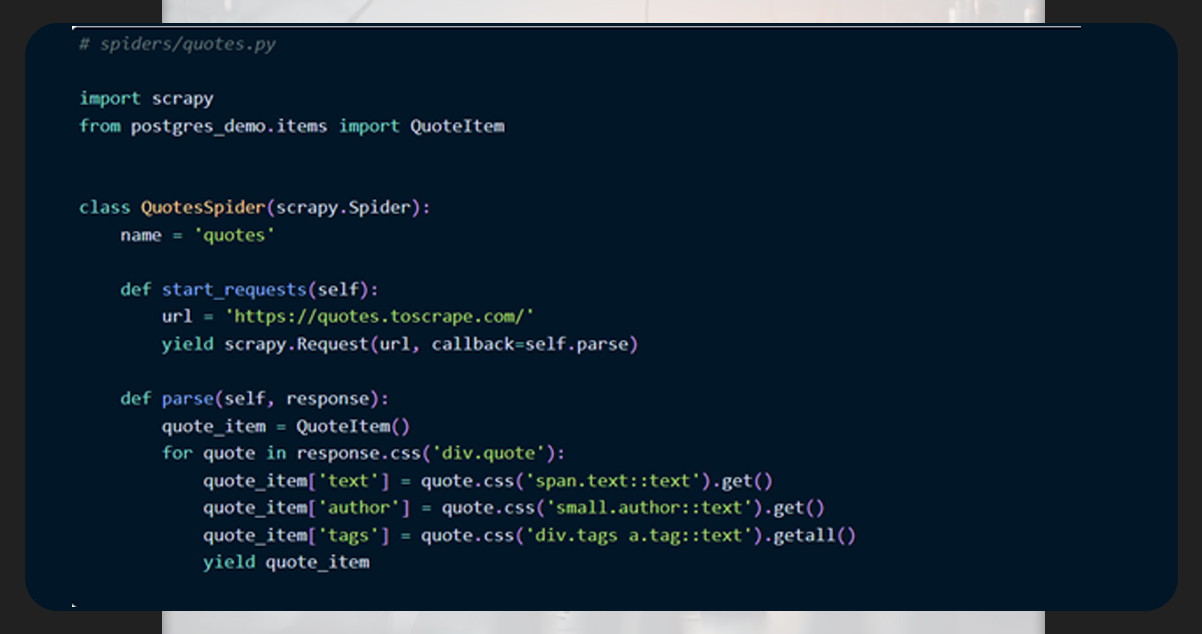
And
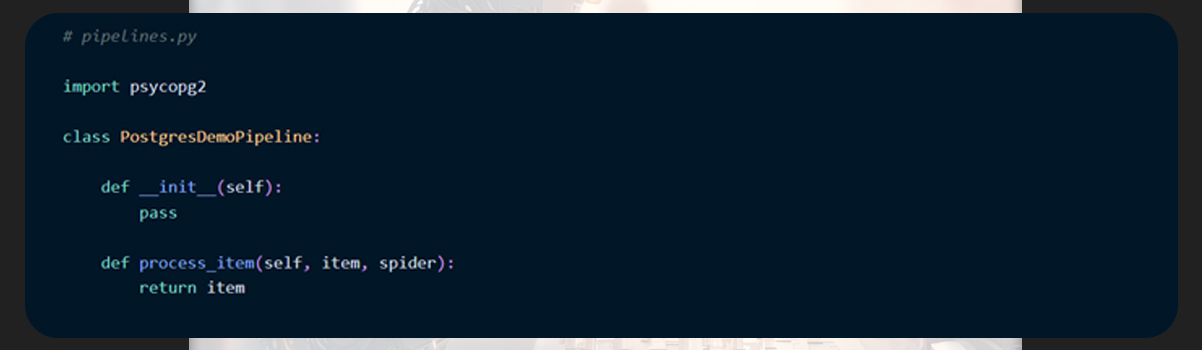
First, we will import psycopg2 into our pipeline.py file and then generate _init_method to generate our database and table.
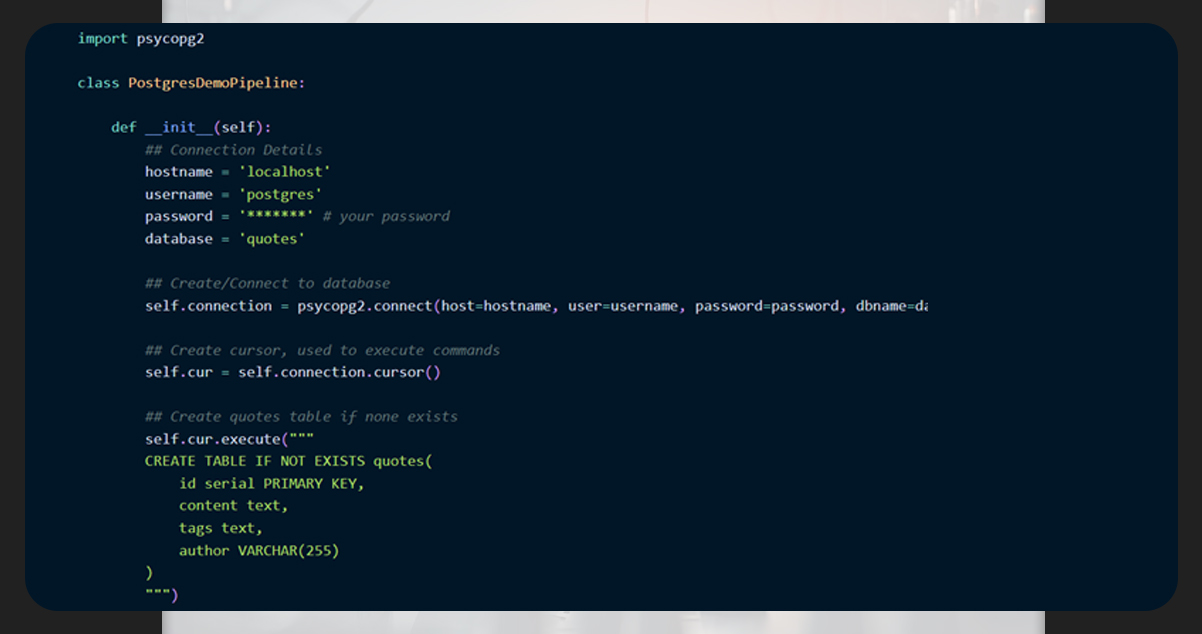
Within the _init_ method, we will configure the pipeline to perform the following:
To connect our database. If it doesn’t exist, create a new database.
Create a cursor to execute the SQL commands in the database. Create a new table with columns, including content, tags, and author.
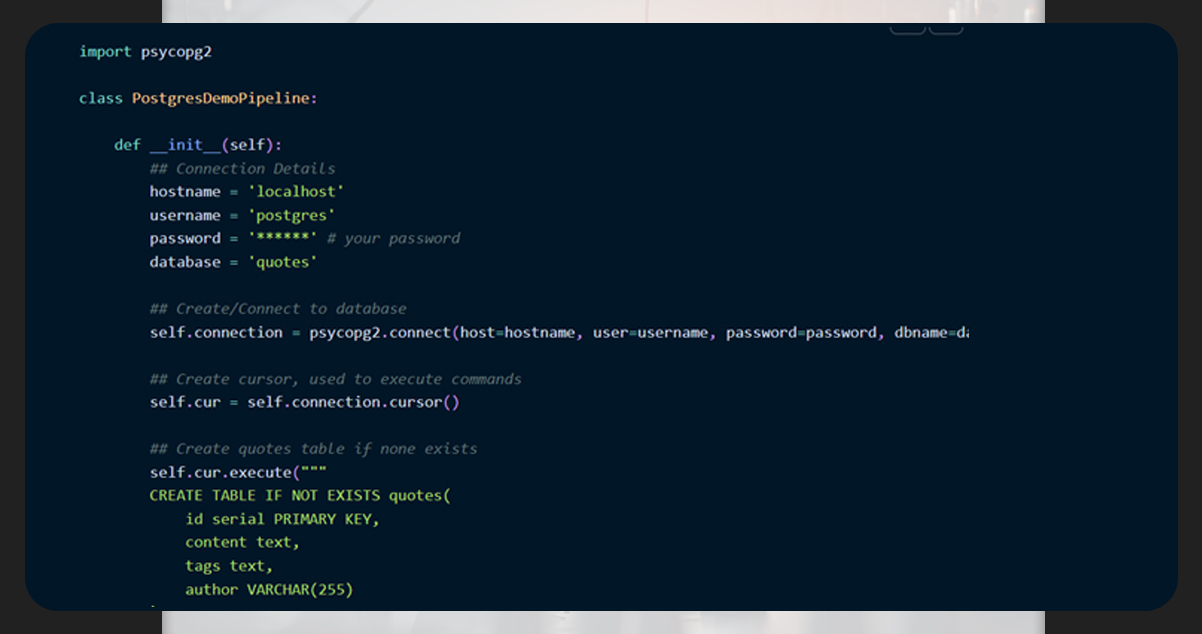
Within the Scrapy pipeline, we will use process_item to store the data in the Postgres database.
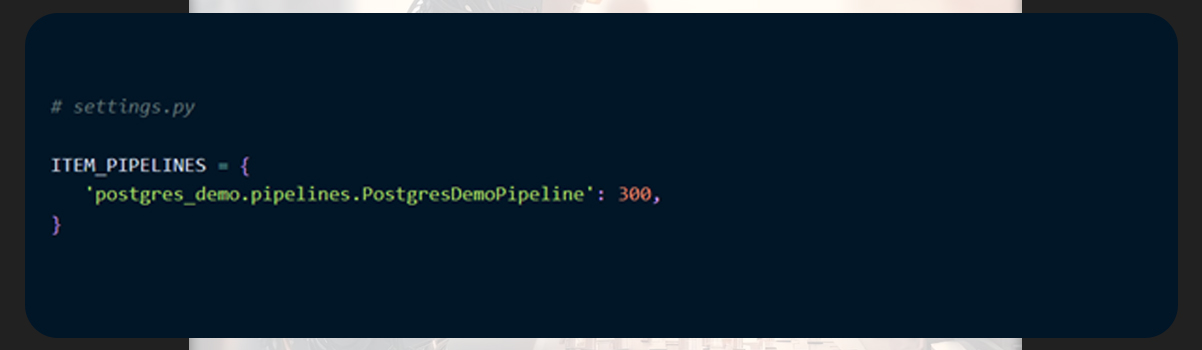
Finally, activate the item pipeline using the settings.py file.
For more information, get in touch with iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile app data scraping requirements.