
Gone are those days when you wind up your office work quickly to reach your home on time to catch up on your favorite shows on TV. Nowadays, with the launch of several entertainment apps, you can enjoy your favorite shows and games on the go.
Several entertainment apps are preferable in Dubai. Some of them are

The data application’s insight quality and results depend entirely on the data quality, which is why iWeb Data Scraping offers the best Dubai entertainment app scraping services. We used data processing technologies like structuring, cleansing, and deduplication to make the data machine-ready. We provide the data in several formats that ensure compatibility and can easily use the data analytics system.
However, in this blog, we will describe how to collect data from the entertainment app of Dubai.
The following Data fields we scrape from the Dubai entertainment app:
Install a few of the different libraries:
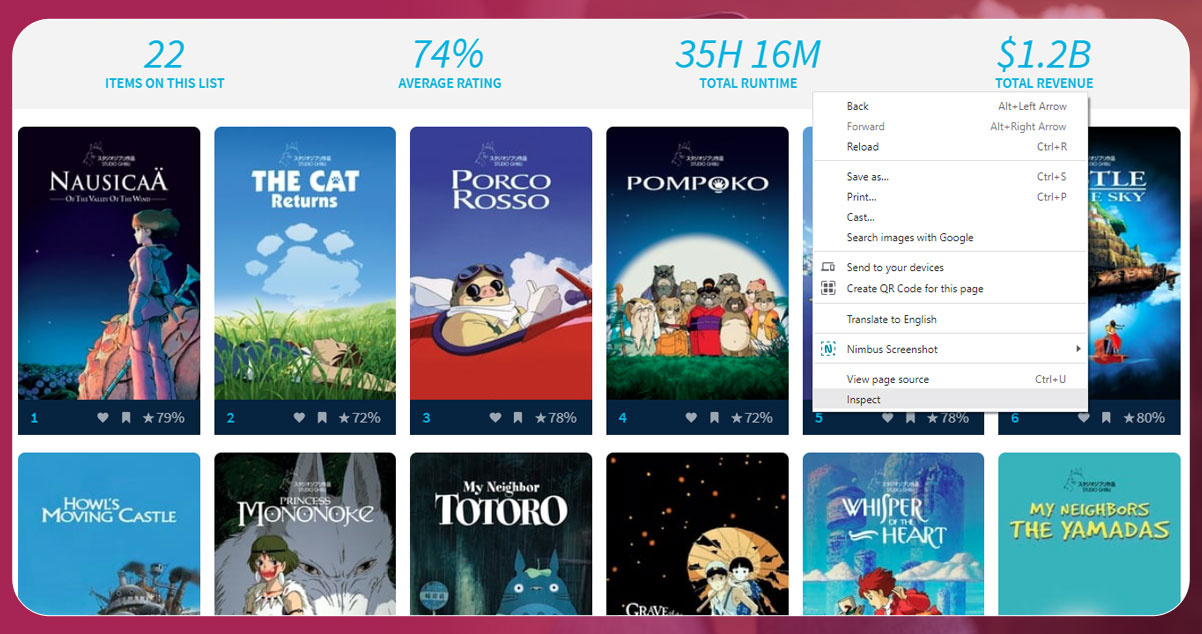
Steps Involved in Scraping the Movie Database (TMDB) Dubai Entertainment App.
Out of the lists mentioned above, we are explaining how to scrape data from the Movie Database (TMDB) Dubai entertainment app.
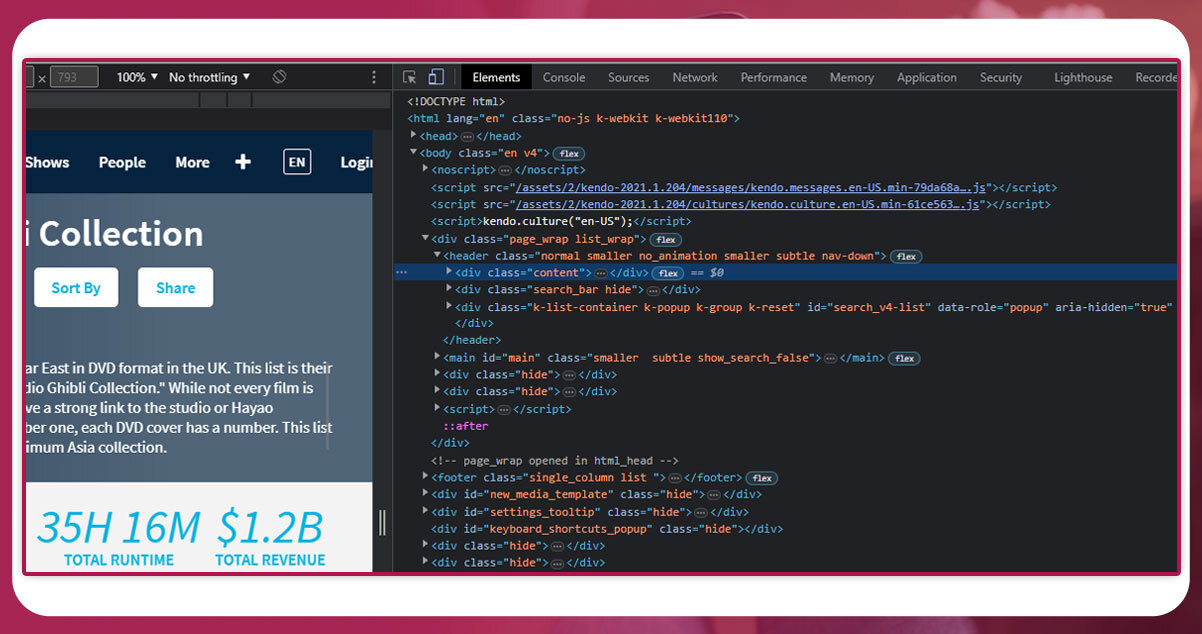
First, right-click on the page and go to inspect
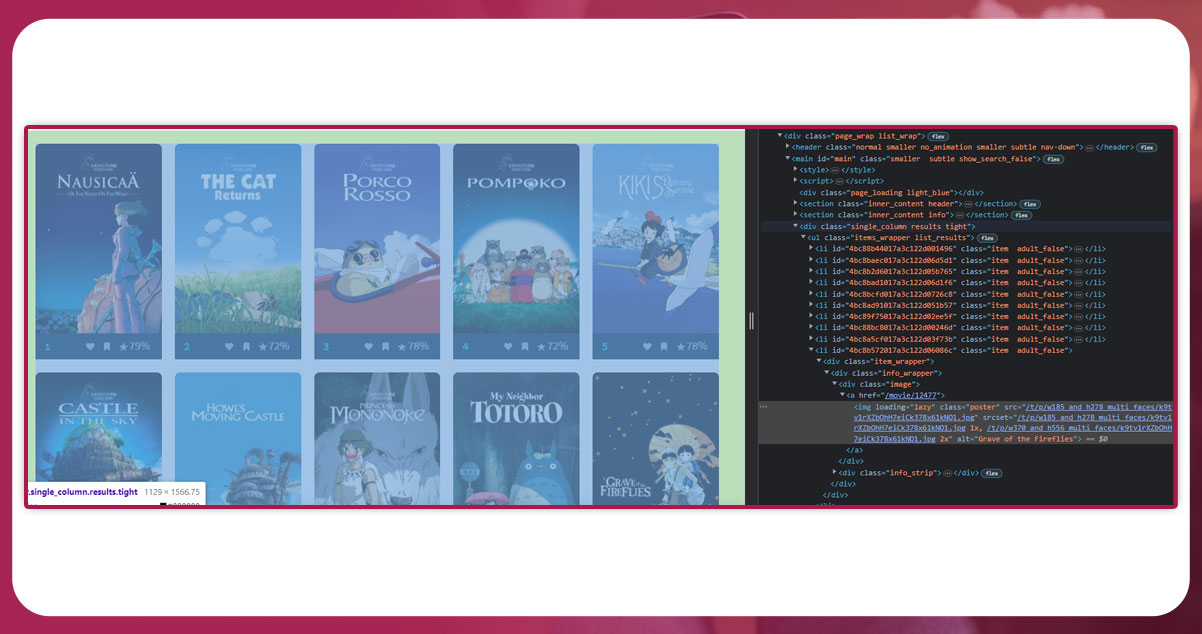
Select the element on the website to inspect.
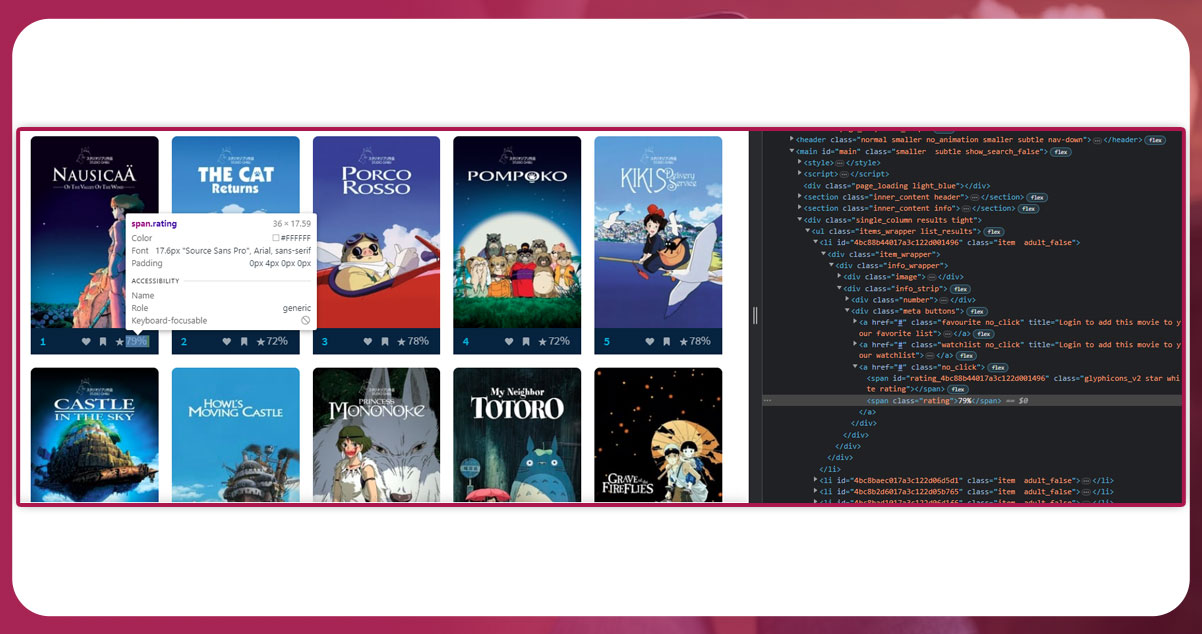
First, we will scrape the ratings. So, click on where the rating is. The exact location is available on HTML lines of code.
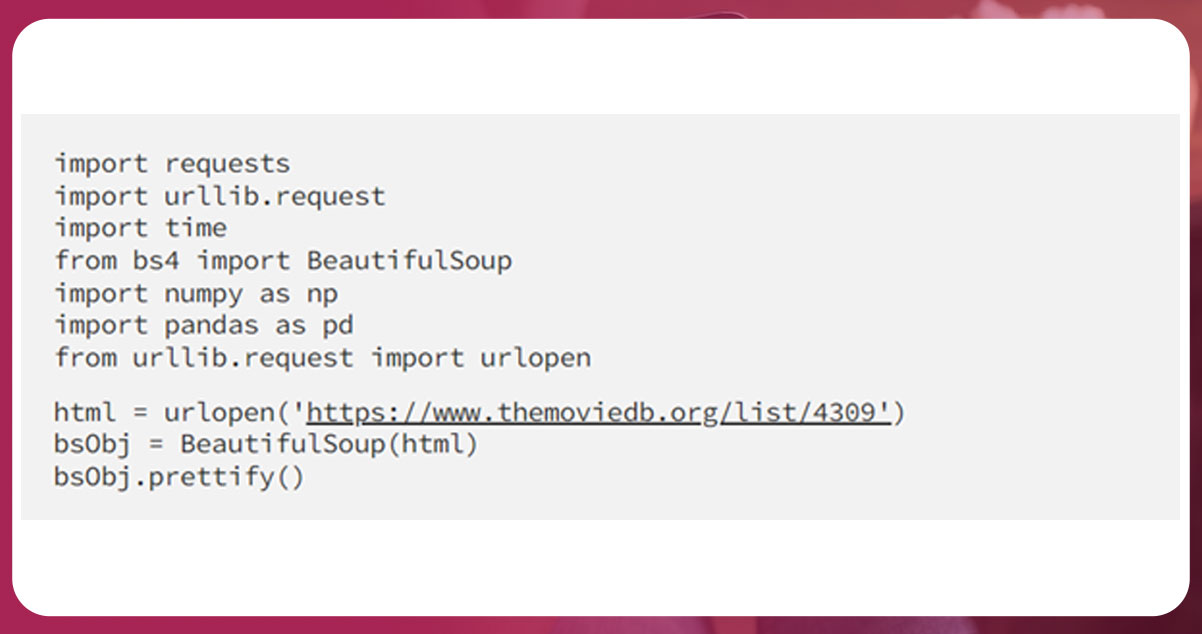
The output is in HTML format. The movies list remains in < ul > tag having attribute id=list_page_1. We will extract data with find_all(tag, attribute) . Then, retrieve a list of all < li > tags within the tag < ul >.
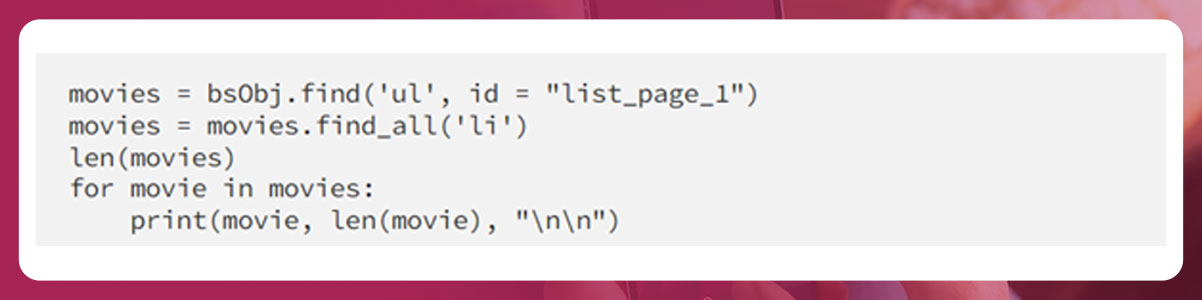
The find_all() function will return all the objects mentioned in the parenthesis. We know that the length of the movie item is 3. Hence, the items with length >0 will give the movie information.
movies = [movie for movie in movies if len(movie) > 0]Here we will scrape data like URL, title, rank, image, and rating. Each movie is ranked in a different tag having the same structure. So, we will start with the first movie. The image’s URL and title remain inside the img tag. The current tag is li.

The .img displays the img tag, which wraps in the current tag. The attributes attrs allow you to gather the attribute of the img tag.
The outcome will be:
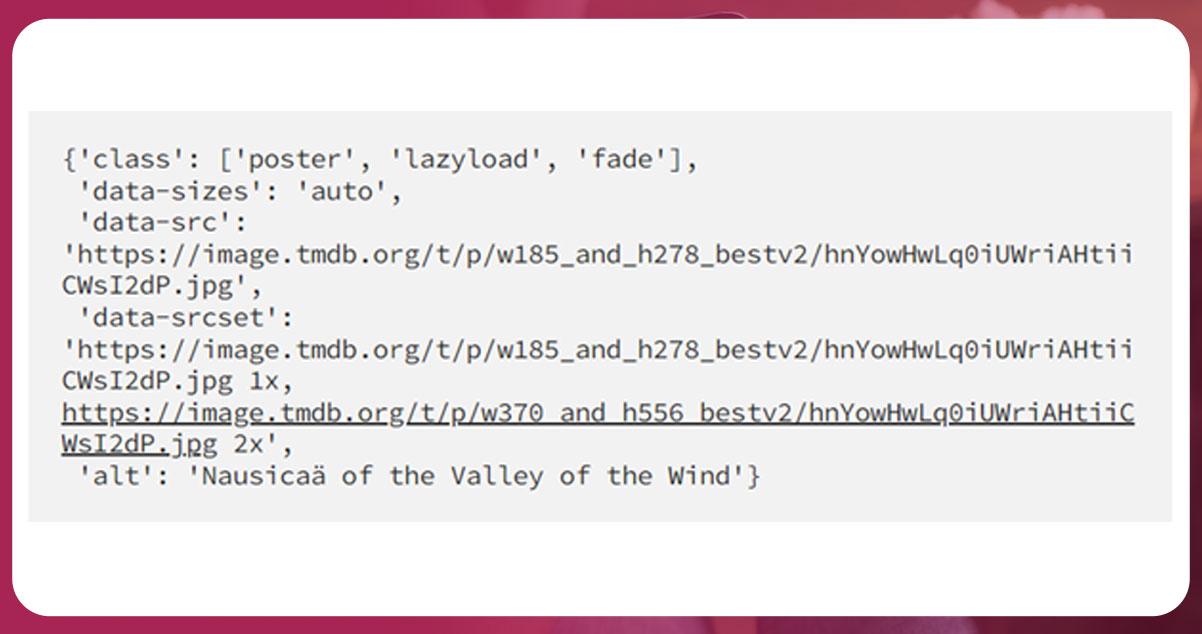
Now, find the title
movie_1.img.attrs['alt']The outcome will be
'Nausicaä of the Valley of the Wind'Find the movie’s image link and use the image to display an image to ensure the link works.
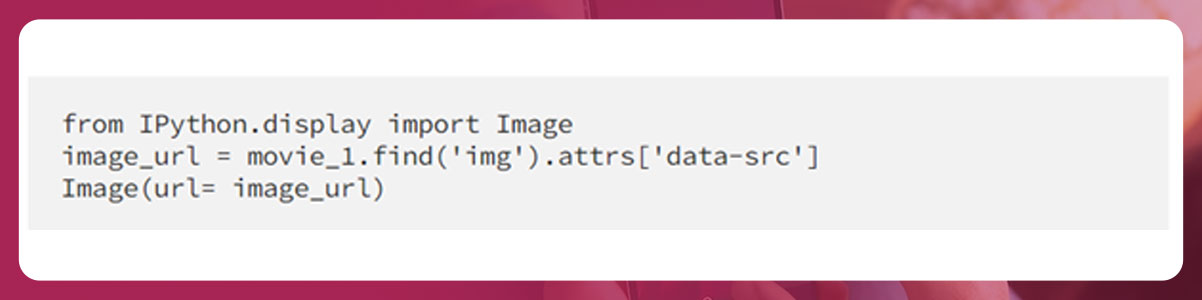
Extract the URL by accessing < a > tag and then to its attribute href

Outcome:
/movie/81The link to the movie is Get the URL of the first movie.
full_url = "https://www.themoviedb.org" + urlNow find the rank by accessing the div tag with class=number. Access the span tag. To return the text inside the tag .text, use the following.
int (movie_1.find('div', {'class':'number'}).span.text)To find the ratings, perform the same steps.
float(movie_1.find_all('span',{'class':'rating'})[1].text)Loop all through the movies using the same lines of code.
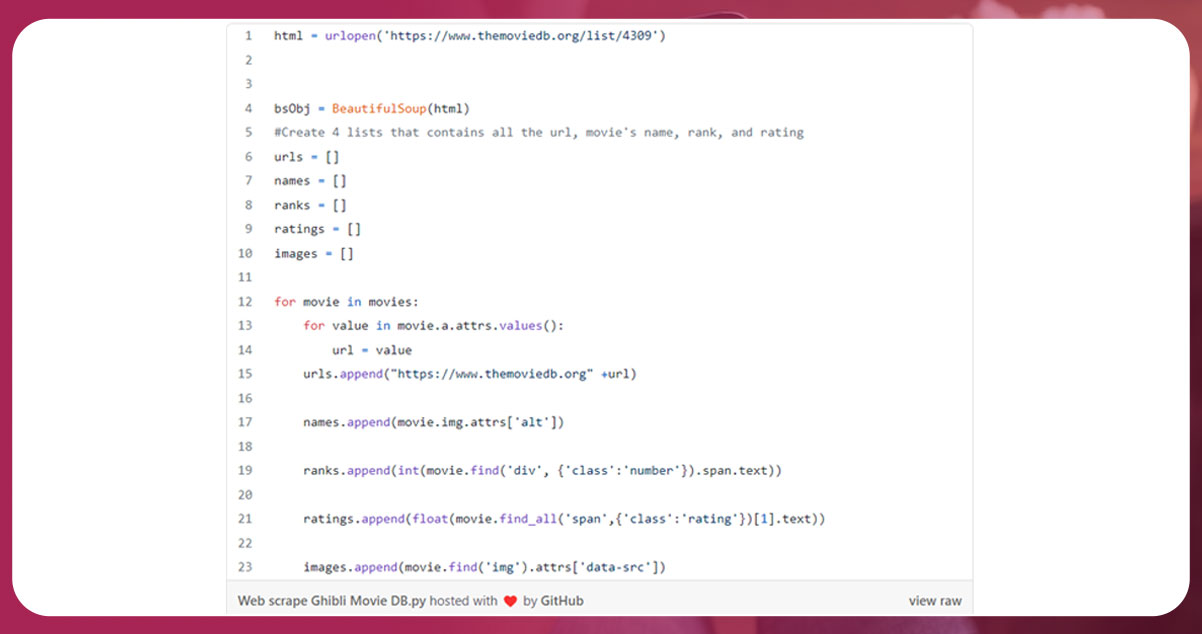
Now, find the following tag and scrape multiple pages.
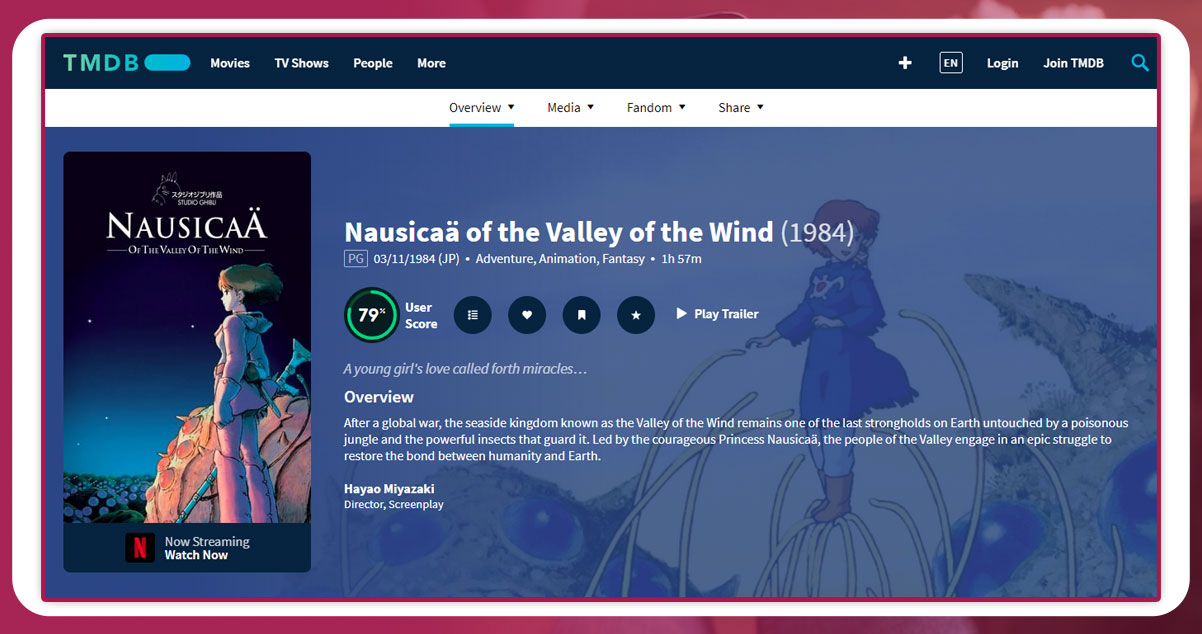
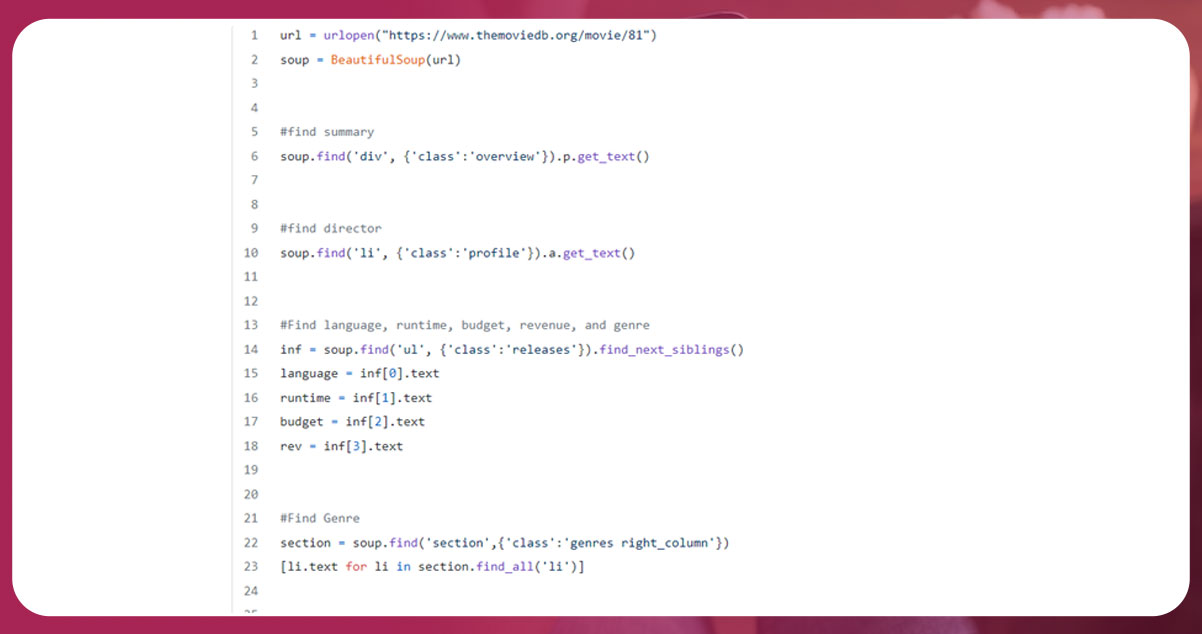
Now click on one of the lists of movies. Use the URL you found previously to extract the information about the movie, including director, runtime, language, revenue, budget, and genre.
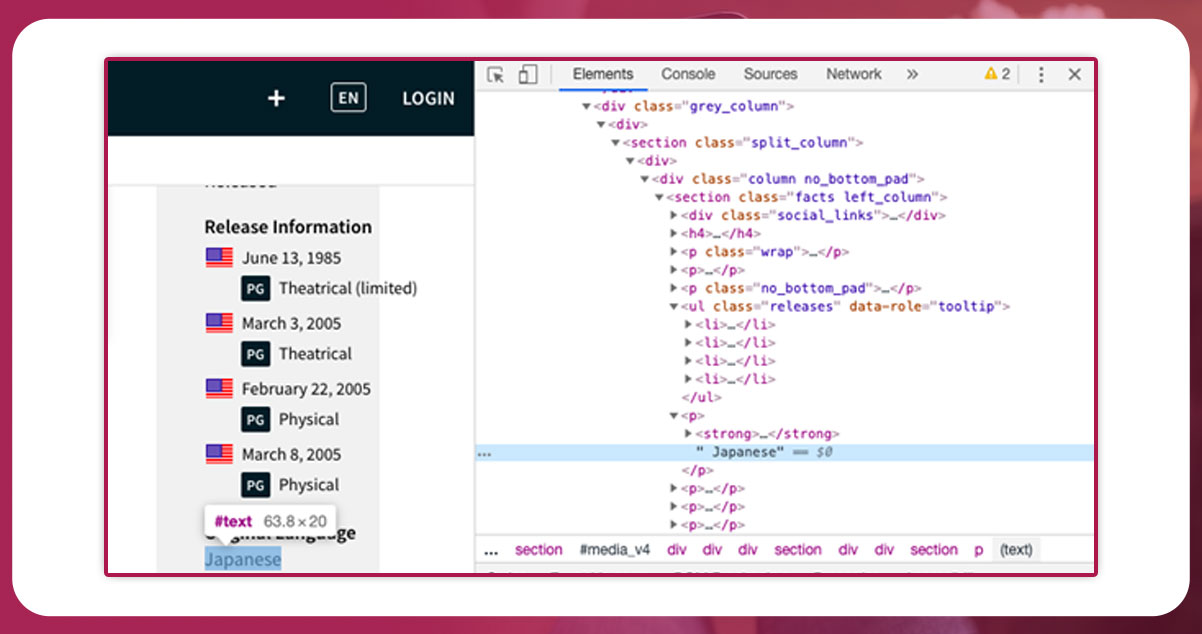
If you want to access the < p > tag that includes the information, use .find_next_siblings() to access the p tag using the ul tag.
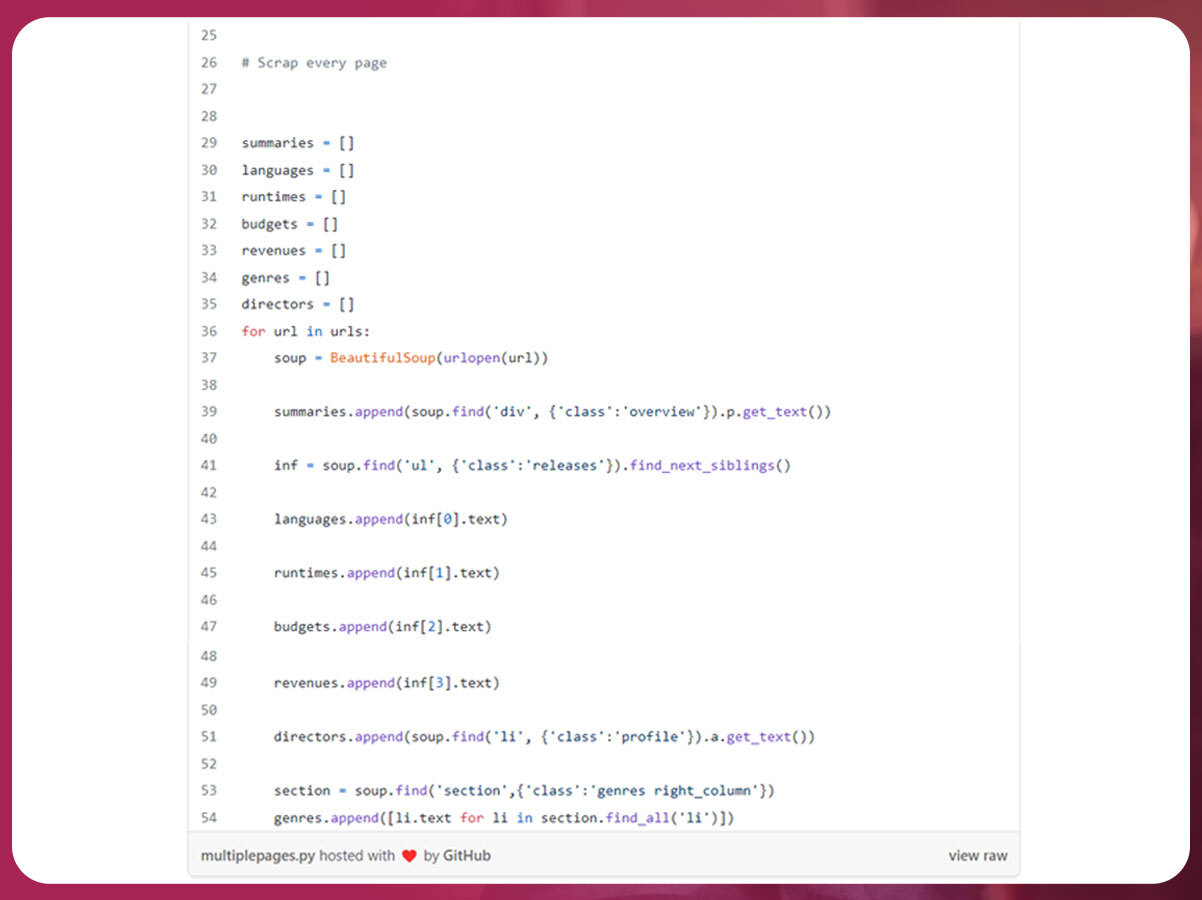
Put Data into DataFrame

Outcome:
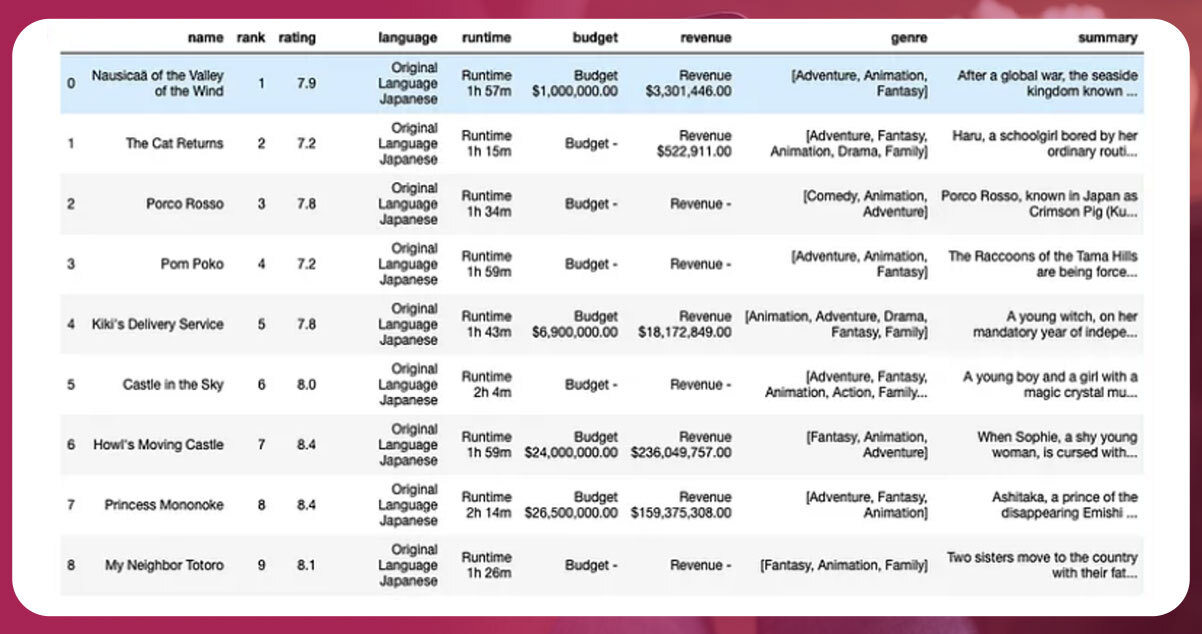
Now, we have a dataset that we can use for future engineering.
For more information, get in touch with iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile app data scraping service requirements.