In recent years, the food delivery industry has witnessed massive changes. In 2023, the Online food delivery market predicts to generate revenues of US $0.85tn. By 2027, this revenue is expected to boos at an annual rate of 8.90% (CAGR 2022-2027), having a market volume of $96.50 billion.
As the food-delivery market continues to flourish, it becomes challenging for almost all businesses to distinguish their brands and generate a profit. Hence, to gain a competitive edge, companies in the food and delivery industries are continuously looking for new opportunities and inculcating several new technologies into their workflows.
Web scraping tools are a boon to streamline and accelerate the data aggregation process. It reduces the turnaround time and the amount of human effort required for data retrieval.
At iWeb Data Scraping, we perform scraping activities to find online restaurant data, including self- pick-up data from Bangalore.
In this blog, we will throw light on what food delivery data is and how web scraping can collect food delivery data.
Web scraping is the procedure of aggregating geo-based food delivery data via an automated process and downloading the same in a readable format. The type of food delivery data scraped are:
Restaurant data like
Strategize Market-Based Pricing: It is one of the important pricing strategies for achieving price optimization. It allows the business to gather data related to food pricing, food menu pricing, discounts, etc., from the competitor’s page.
Helpful in Handling Local Competition: When you are in this business, you must keep track of how your competitors are performing? What strategies are they using to make it different from others? Web Scraping will extract geo-based food delivery data along with restaurant location information. You can easily scrape competitors’ contact information, website, ratings, delivery routes, and working hours.
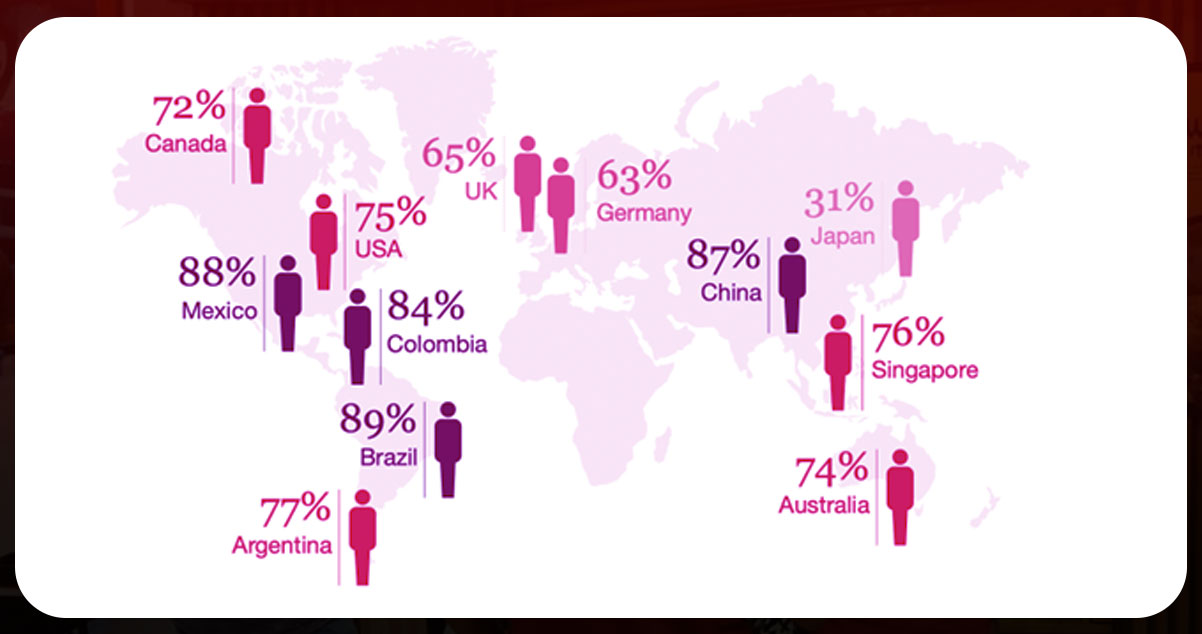
Convert Customer Reviews into Insights: Nearly 74% of individuals use customer experience to make a purchasing decision. Web scraping can collect restaurant reviews from several food delivery websites like Zomato/Swiggy. The scraped data from Zomato food delivery website is used by businesses to conduct sentiment analysis.
Helps to Discover Trends in Food Industries: With web scraping, you can easily scrape food descriptions, food preparation time, menu items, and delivery routes from different web sources. Data extraction will give insight into food industry trends and help keep pace with ever-changing businesses.
Modules Used
Requests: This library can interact with the language. This means that manually adding query strings to URLs isn’t required. Using Python requests will allow you to send HTTP/1.1 requests. This will help you in adding content like form data, headers, multipart files, etc. You can also access the response data of Python similarly.
BeautifulSoup: It is a Python library for extracting data out of HTML and
XML files.
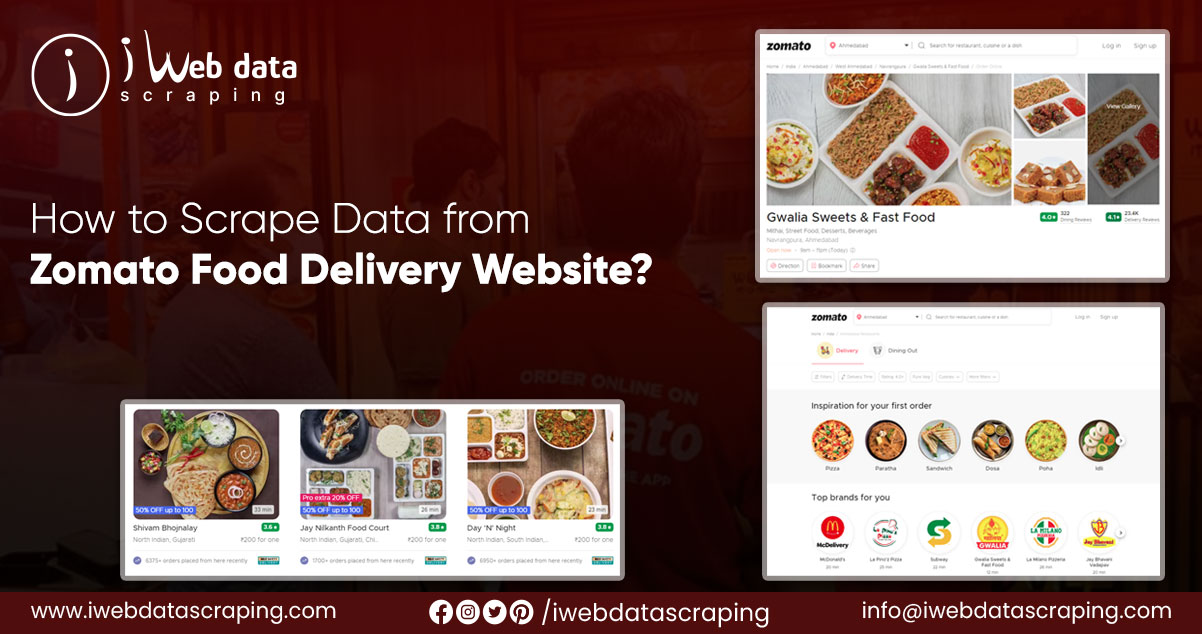
For webpage access, type the website address and then submit the HTTP requests. To attain the data scraping from Zomato food delivery website page, we have to feed the request similarly.


Here we are accessing the Zomato website first.

Pass this content to the BeautifulSoup to get data with HTML/valid website tags used for developing the website.



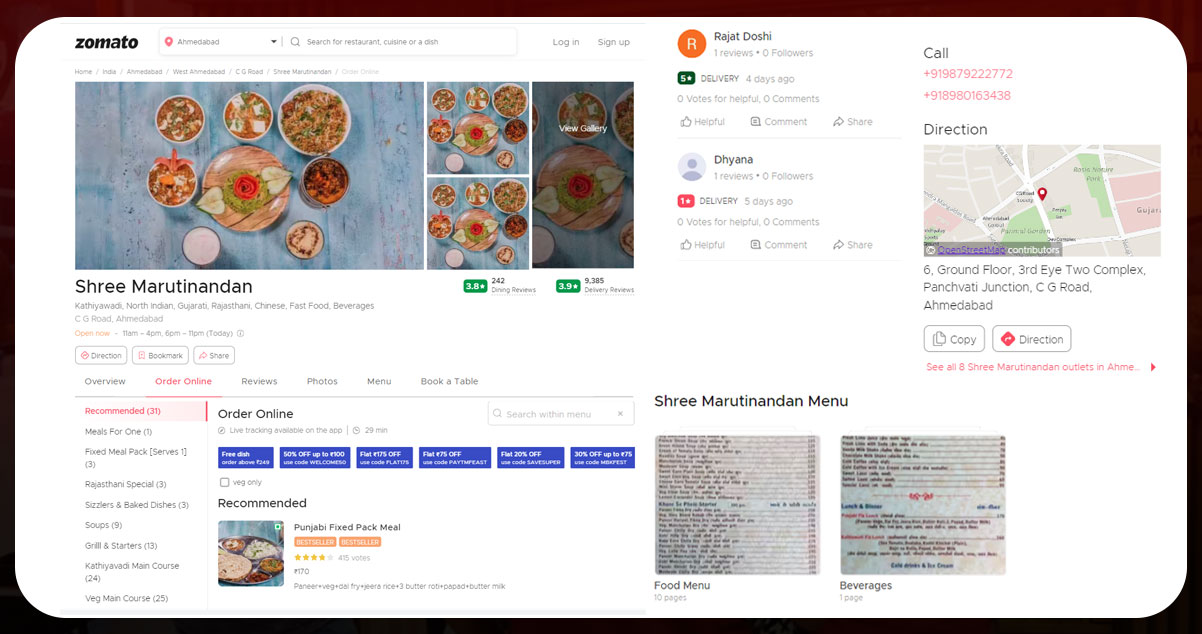
Here we have data from the top restaurant on Zomato. We will extract the restaurant’s name, address, cuisine type, etc. First, we have to look for the HTML tags that store this information.
Using a loop, we will extract restaurant information one by one. The above-mentioned code will find all HTML div tags that contain class equals to ‘col-s-8 col-l-1by3’. It will finally return the list of restaurant data.
In the above code, you can find t. It contains information related to restaurants, like addresses, names, cuisines, prices, reviews, etc. All information is enclosed with different tags. And the tags are available with tr.
The restaurant lists look like this:
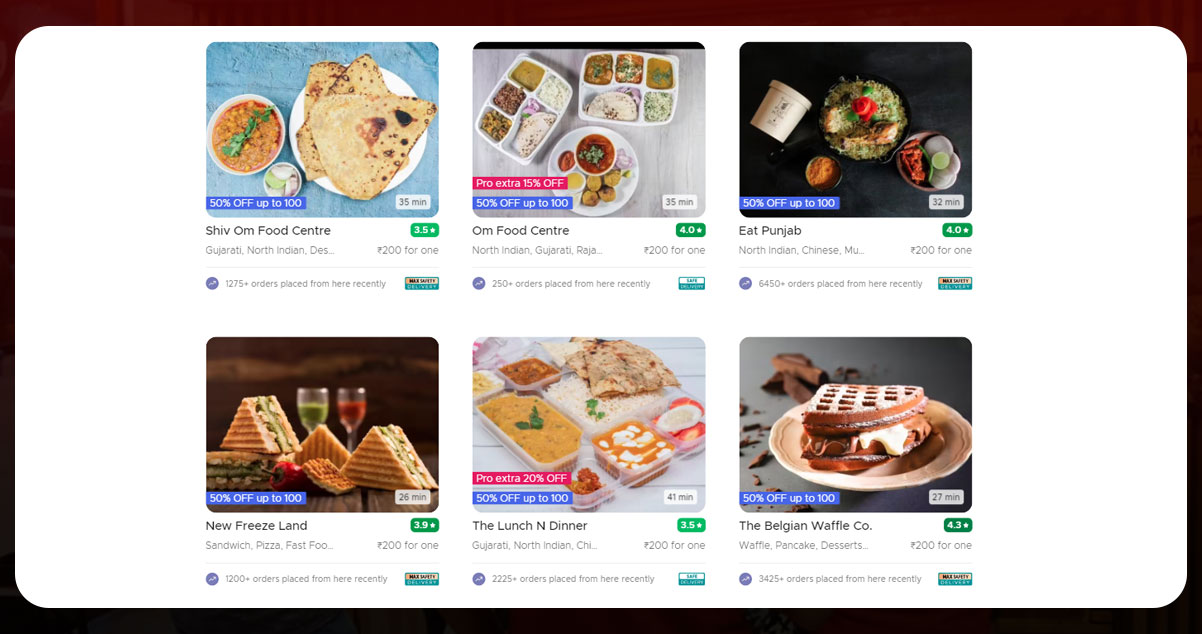
The information that we want to get is available in different formats. Using HTML content, we found that information is stored within a div tag.
Let’s scrape this information one by one using Data Frame.
You will get the output code like this.


Now, to get the data in a readable format, we will save it in CSV format.
Conclusion: From the above content, we have come to the conclusion that by using python code, you can request access to any website. And to extract the HTML content, use BeautifulSoup. After extracting the content, save it in a CSV format.
CTA: For more information, contact iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile app data scraping service requirements.