How to Scrape Dynamic Websites Using Python?

We all might have heard of the term "Dynamic Website." But how many of us understand the meaning? Before getting in-depth into how to scrape dynamic websites using Python, we will first discuss dynamic websites and their importance.
About Dynamic Website
A dynamic website is a website that displays dynamically generated content in response to user interactions. Compared to static websites that display the same content to every visitor, dynamic websites can personalize every content based on user search preferences, input, or data from databases or any other external sources.
The main programming languages that dynamic websites use are Python, PHP, ASP.NET, and Ruby. All these languages are required to generate HTML pages on the server. These websites can respond to several user actions, including forms submission, page element interactions, clicking buttons, etc. It can easily connect to databases to store & retrieve data and enables the functionalities like Content Management Systems, e-commerce platforms, user registrations, etc.
Importance of Scraping a Dynamic Website
There are many reasons why dynamic website data scraping is essential. Some of them are listed below.
Access to Real-Time Data: Dynamic websites often display updated information that may not be readily available via other means. By scraping a dynamic website, you can retrieve and use the latest data for various purposes, including market research, competitive analysis, or tracking changes in industries.
Competitive Intelligence: Seeking professional help from dynamic website scraping services can help you collect valuable insights about your competitors. Monitor their product listings, pricing, promotions, and customer reviews to gain a competitive edge and make informed business decisions.
Research & Analysis: Dynamic websites are a pool of information that can be valuable for research and analysis. By scraping and collecting data from various sources, you can identify trends and patterns, make informed decisions, perform market research, etc.
Lead Generation: Scraping dynamic web pages: can guide you in lead generation by extracting contact information, customer reviews, or other vital data about target audiences. This Data is helpful for marketing campaigns, sales prospecting, and more.
Content Aggregation: Dynamic websites has the potential to generate a massive amount of content, including news articles, blog posts, or social media updates. Dynamic web scraping allows you to aggregate and merge this content from multiple sources, making it easier for your website to analyze, summarize, or reuse.
Monitoring and Tracking: Dynamic web page scraping with Python: will help you track real-time changes, updates, or events. It will help you to take quick necessary actions if required. Monitoring price fluctuations, stock availability, news updates, etc., are helpful.
Important Libraries and Techniques Required for Dynamic Websites Scraping with Python
A combination of libraries and techniques is essential to scrape content from dynamic websites. We have given a brief detailing of the critical approach to follow:
Inspecting a Website: Analyze the network requests and the website's structure using the web browser's developer tools. Look whether there are any AJAX requests, APIs, or dynamic content that you need to interact with.
Libraries Selection: Choose a scraping library: Several Python libraries, including BeautifulSoup, Scrapy, and Selenium, can help with web scraping.
BeautifulSoup: This library can parse and navigate HTML/XML documents.
Scrapy: This robust framework can perform advanced web scraping.
Selenium: It automates browser interactions.
Installing Necessary Libraries: You must install more based on your selected library. For example, you may need to install Selenium WebDriver or other browser-specific drivers.
Fetch the web page Using Scraping Library: First, fetch the initial HTML content of the webpage. Use BeautifulSoup or Scrapy to send HTTP requests and retrieve the HTML response.
Inspecting the dynamic content: If it is within the HTML response, you can extract it using BeautifulSoup or Scrapy.
Webpage Loading: Use the WebDriver to load the webpage and wait for any necessary elements to appear.
Dynamic Content Extraction: As soon as the dynamic content has loaded, use BeautifulSoup to parse the updated HTML and extract the desired data.
Handling Pagination: If the dynamic website has pagination, implement logic to repeat through the pages and scrape the data from each page.
Storing or processing the scraped data: After extracting the data, you can store it in a desired format, e.g., CSV, JSON, XML, Excel, etc., as per your requirements.
Steps Involved to Scrape Dynamic Websites Using Selenium
The first step to scrape dynamic websites with Python is to build a new Python project. For this, you need to create a directory data_scraping_project. This directory will accumulate all the data and the source code files. Within this directory lies two sub-directories: 1. Scripts and 2. Data. Scraping comprises all Python scripts that aggregate data from a dynamic website. At the same time, Data collects all the extracted data from the dynamic websites.
Python Packages Installation
After creating the directory, install the Selenium, Webdriver Manager, and Pandas libraries. You can install Selenium Python Package by running the below pip command.
pip install selenium
Now, run the pip command to install the web driver manager.
pip install webdriver-manager
Run the below command for Pandas installation.
pip install pandas
This blog will scrape Programming with Mosh, a YouTube channel, and Hacker News.
List of Data Fields
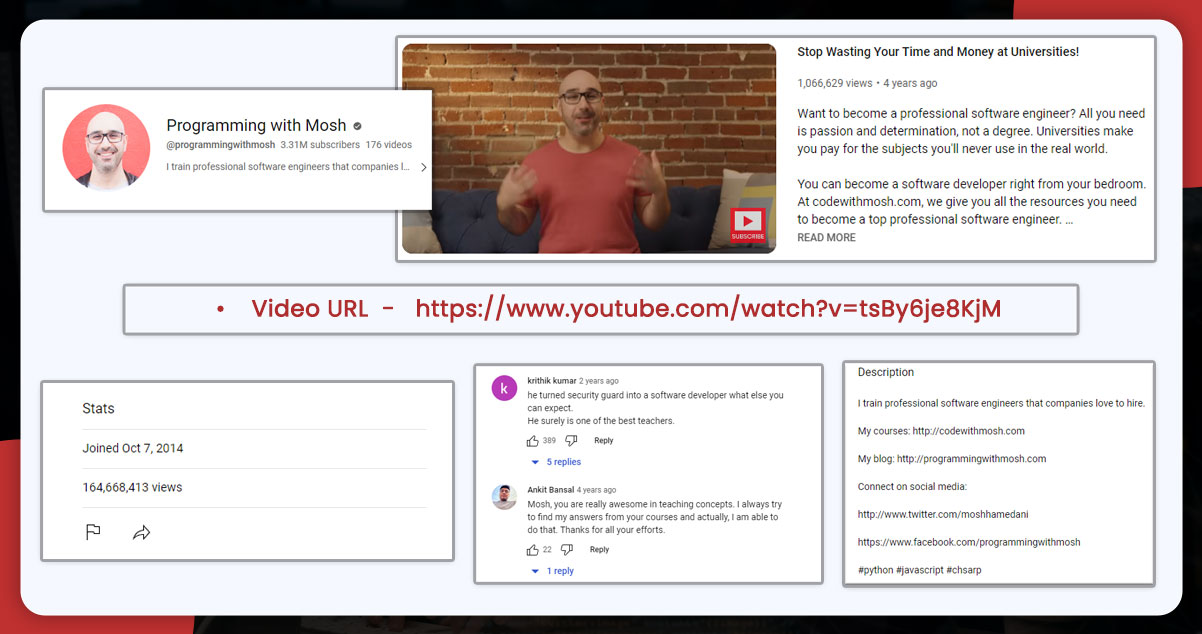
- Video Title
- Video URL
- Image URL
- Number of Views
- Video Publishing Time
- Comments
- Article Title
- Article Link
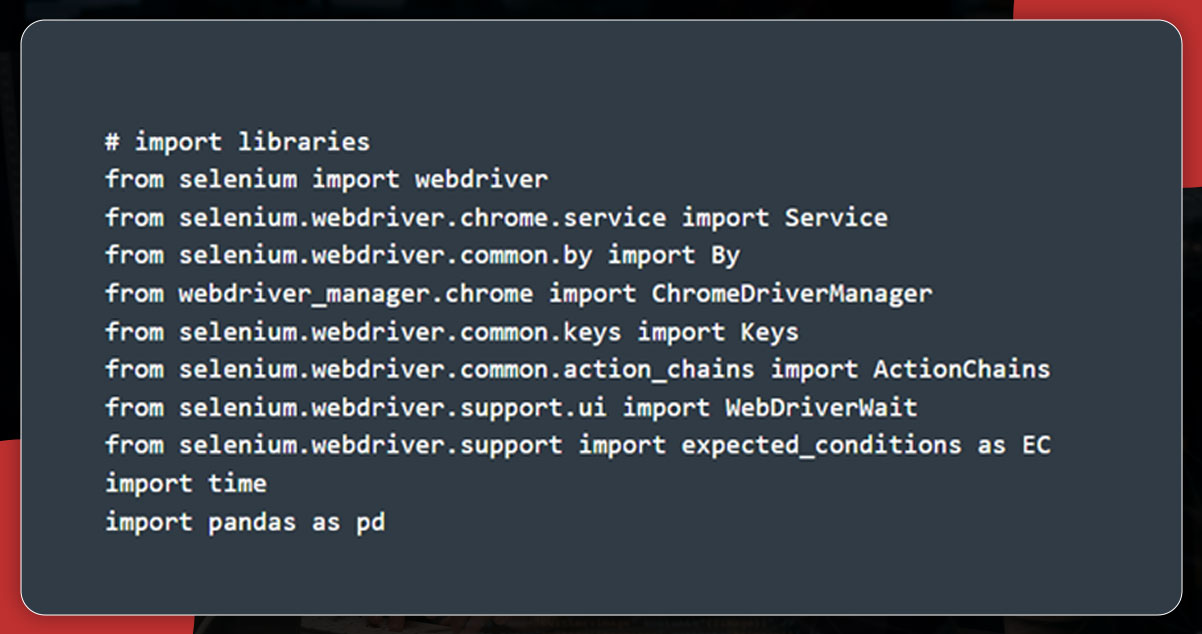
Import Python Packages
The first step is importing the Python packages.
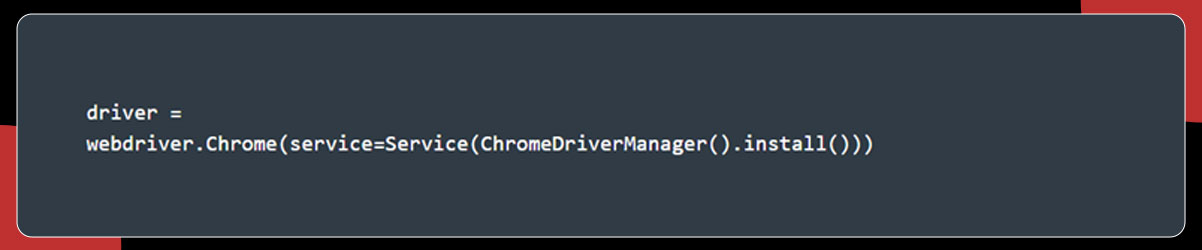
Webdriver Incorporation
To incorporate Webdriver, choose the browser. Here, we are using Chrome. To display the HTML code, go to the webpage and right-click. Then, select the option Inspect Element.
Run the below code to install a binary driver.
Data Scraping Using Selenium
First, define the YouTube URL in a simple Python form for scraping using Selenium. It will allow you to collect data from the specific YouTube URL.
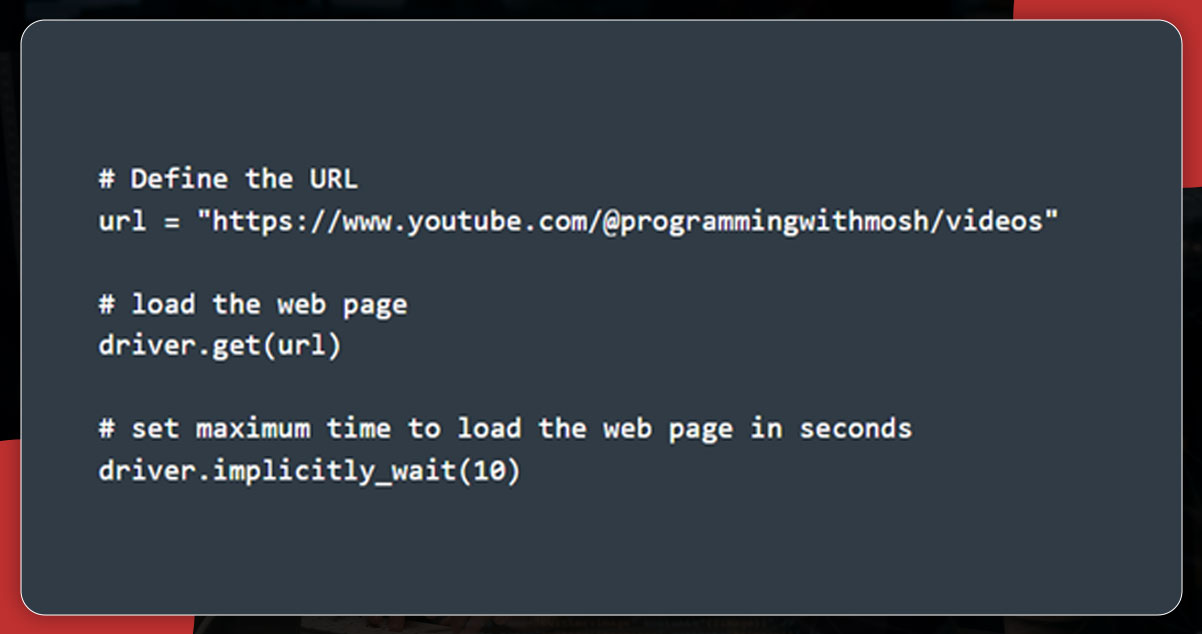
You can see an automatic loading of the YouTube link in the Chrome browser. At the same time, mention 10 secs to ensure the complete loading of the webpage.
Data Scraping Using ID and Tags
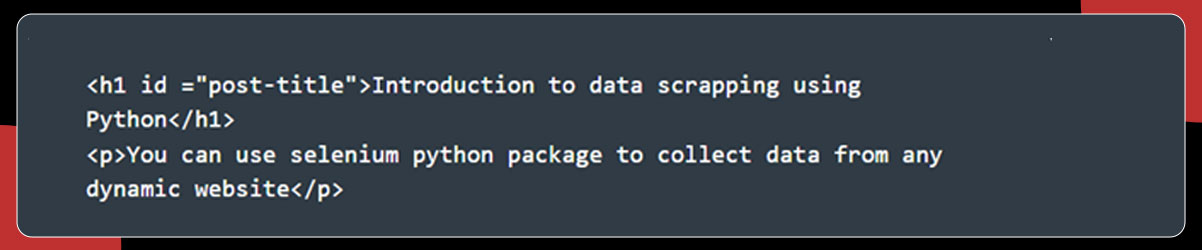
You can use the ID element for scraping purposes, i.e., post-title or h1 & p tags.
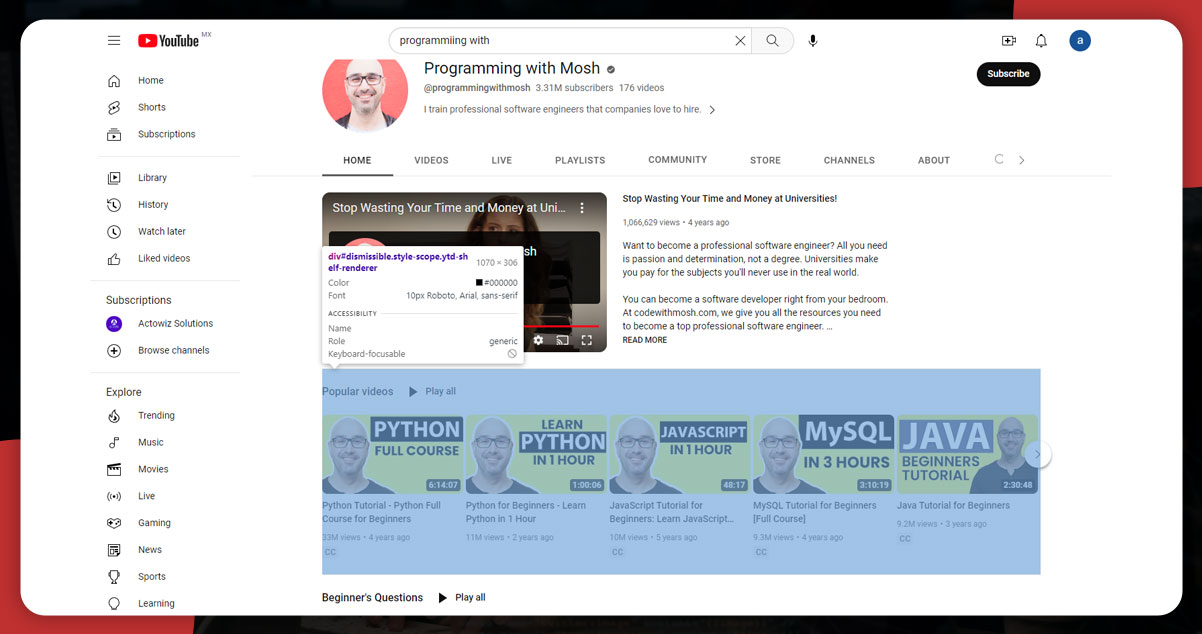
For scraping YouTube URL data, open the link in a web browser, right-click, and inspect. It will provide you with the id and the video list available on the channel.
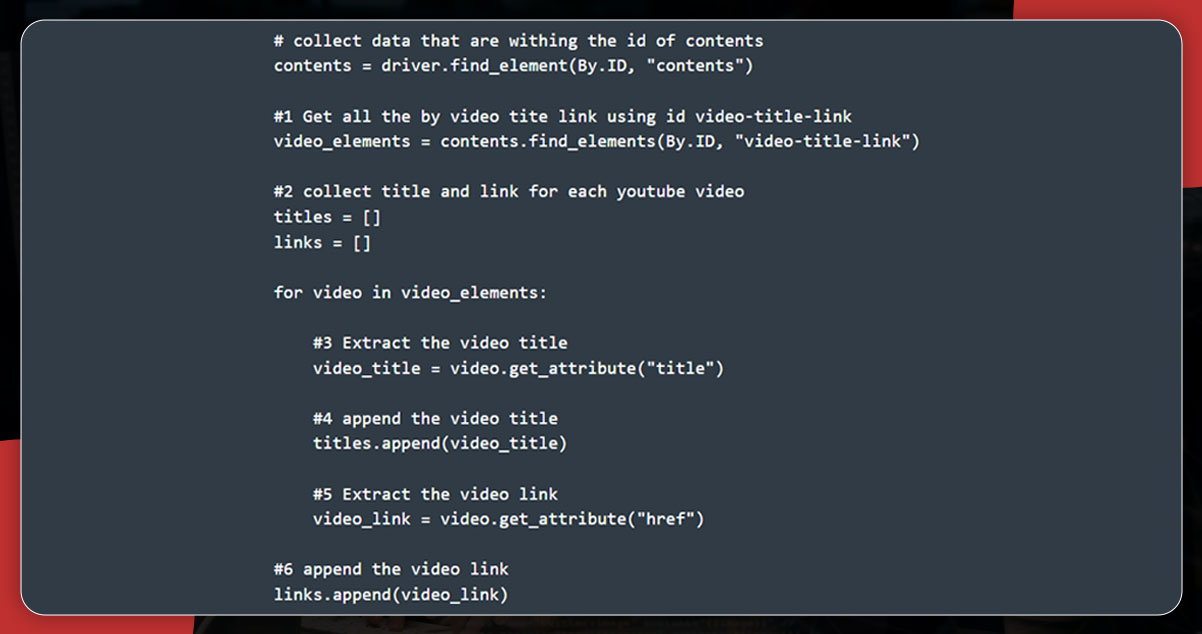
Using Webdriver, scrape data that lies within the ID. We will use the find_element() Selenium process and then pass the first argument (.ID) and ID as the second.
Now, collect the title and link of the video via the video-title-link attribute.
Here, all the titles and links of the video lie within two Python lists – links and titles.
The next step is scraping the image link by finding all the HTML elements using find_elements() and sending the first argument (.TAG_NAME and the name of the tag as the second one.
second one.
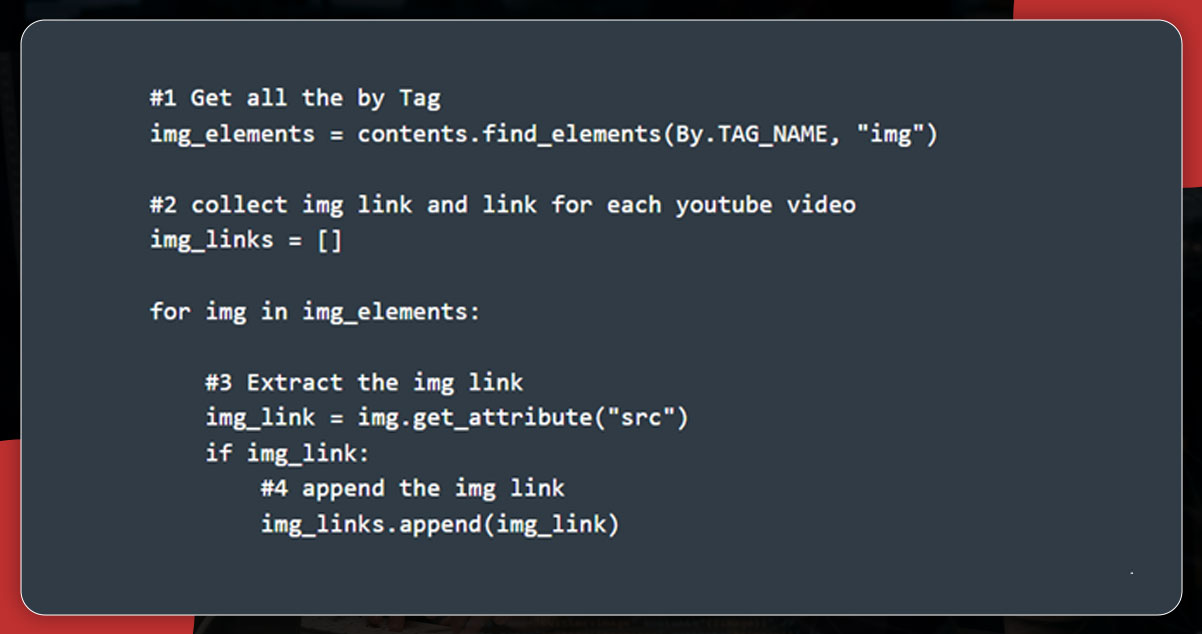
The above code will collect all the HTML elements having an img tag name. For appending the image link, it will create a list with the help of get_attribute() and then pass src as an argument.
If you want to extract several views and published time, collect all HTML elements with metadata-line and then all data within the span tag.
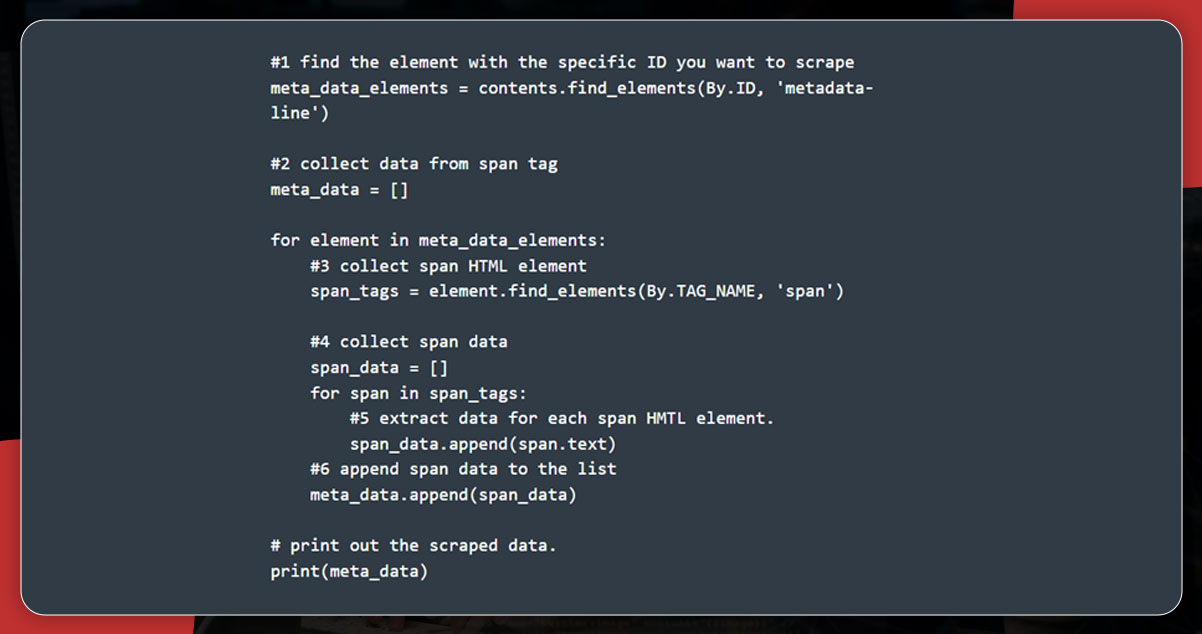
The output of the data from span HTML will appear like this:

After then, develop two Python lists to save the views number and published timings.
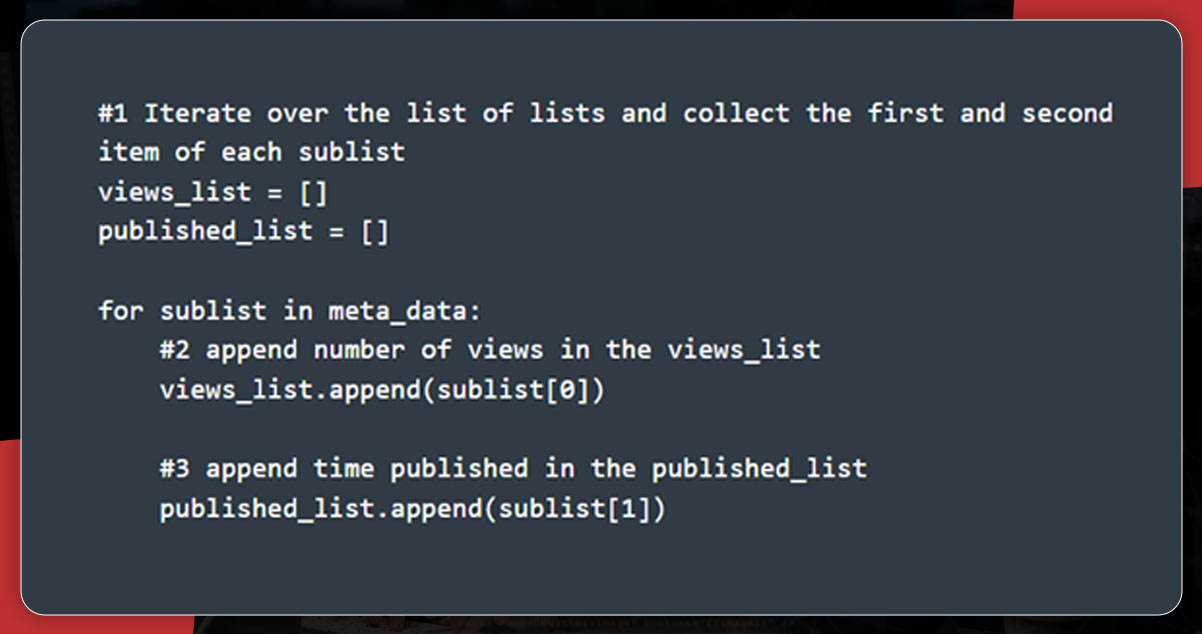
Now, it’s time to save the data into pandas data frame from lists, including links, titles, view_lists, img_links, and published_list
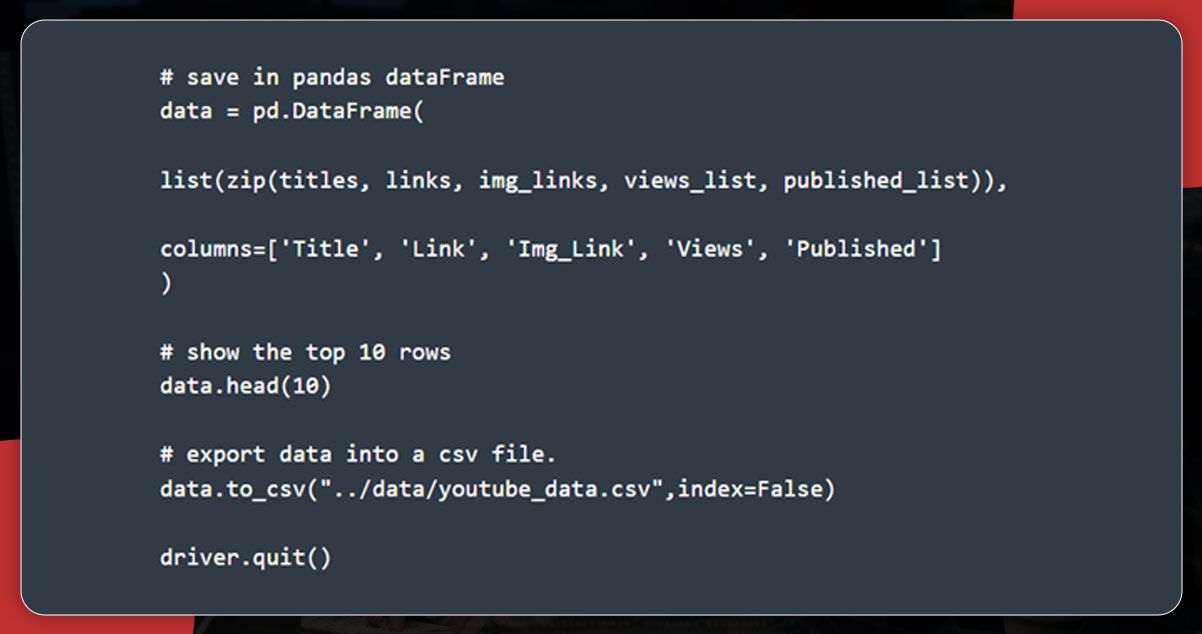
The output will be like this:

Export this data from pandas to a CSV file (youtube_data.csv) with the help of to_csv().
Data Scraping Using CSS Selector
Extracting data using CSS Selector is also easy. It applies to the target elements per their tag name, ID, class, etc.

In the above code, use CSS selector to locate the HTML element having tag name div and class name inline-code. Use it to scrape comments.
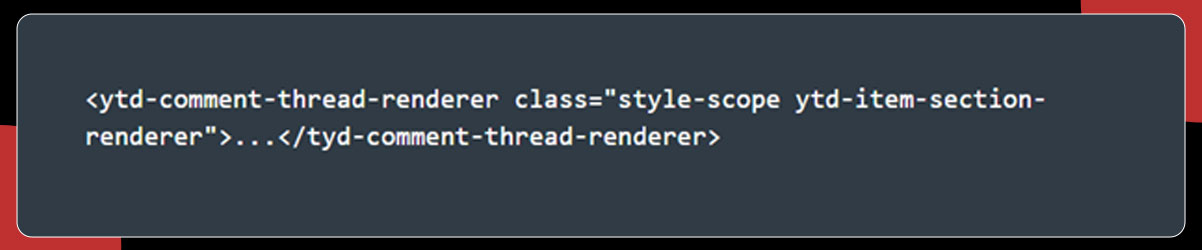
The YouTube comments lie within the below-mentioned tag and class name:
Like the previous importing procedure, import all the required libraries and use the code below to start the process.
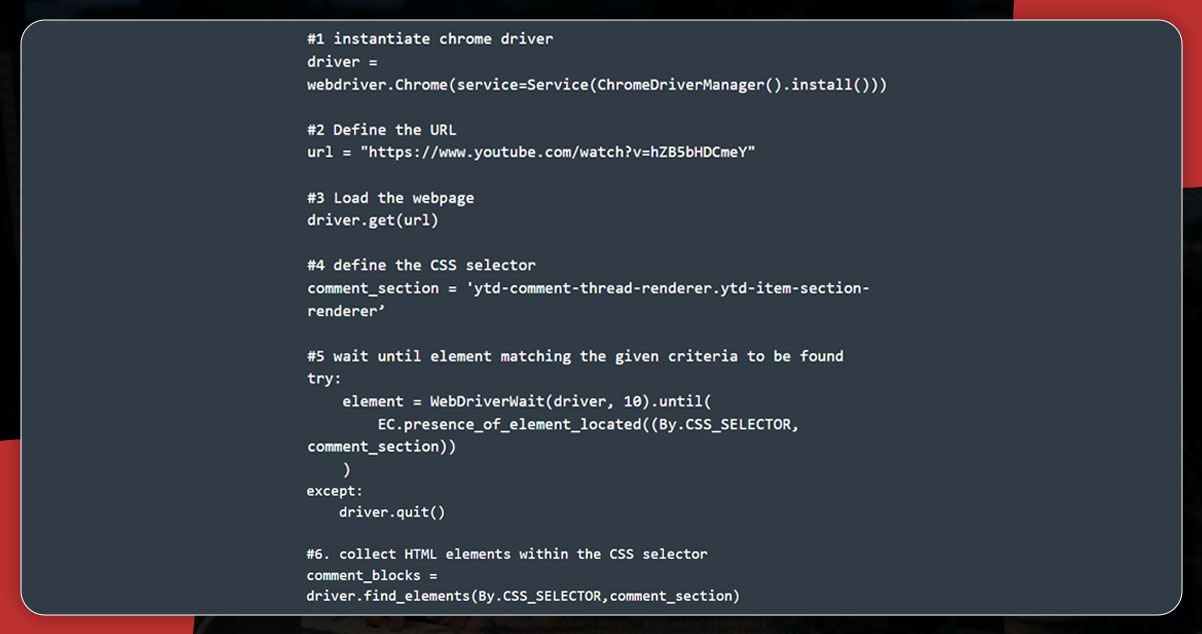
All the HTML elements comments are collected via CSS selector known as
ytd-comment-thread-renderer.ytd-item-section-renderer and get saved in the comment_blocks
Next, use the author-text ID to scrape the author’s name and the content-text to scrape the comment text.
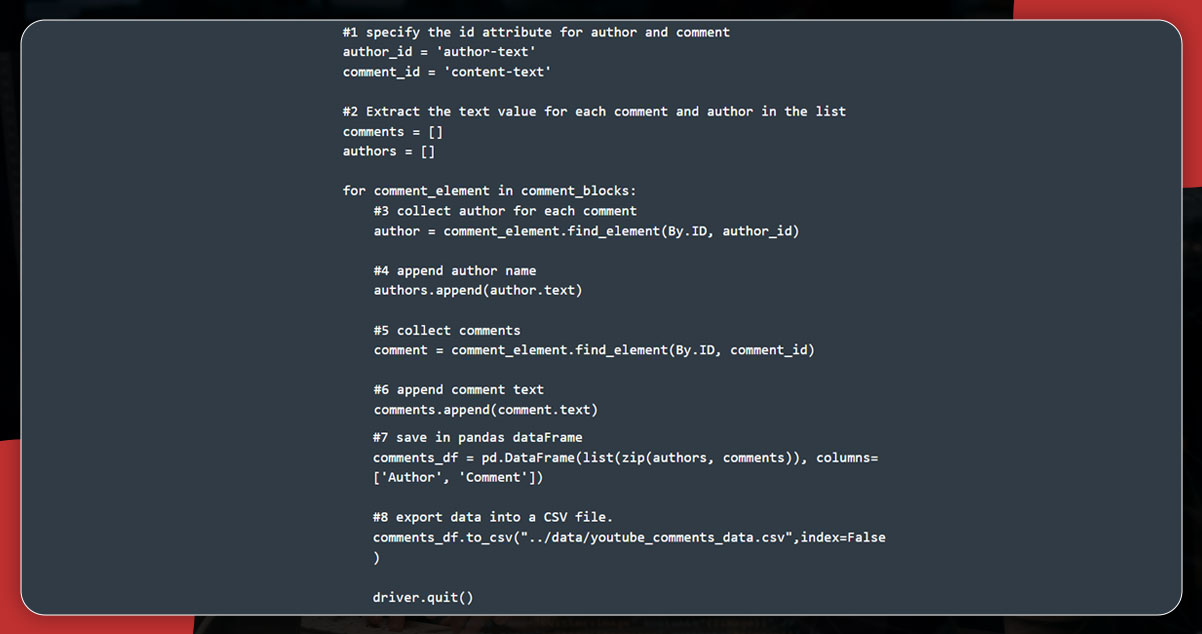
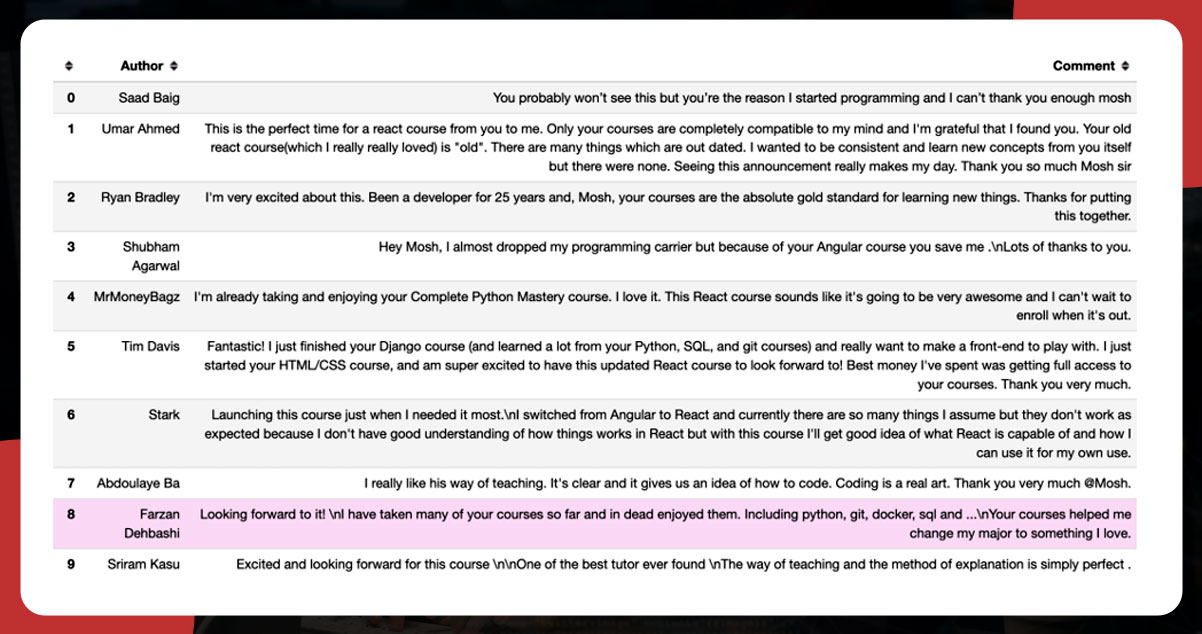
Finally, save the data into a pandas Data frame and export it to a CSV file. The output will appear like this:
Data Scraping Using Class Name
Here, we will collect articles' titles and links from Hacker News using the class name. For this, we will use find_element() and then pass through.CLASS_NAME as the first argument, and class name as the second argument.
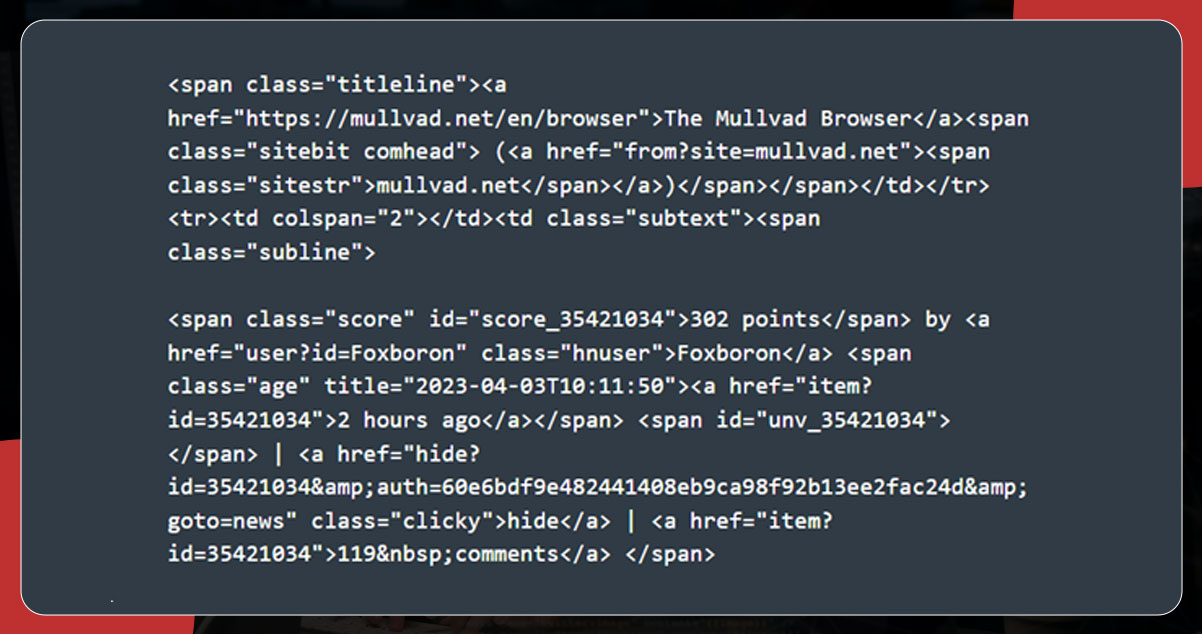
Now, import all the essential packages and add the following code to extract the title and link.
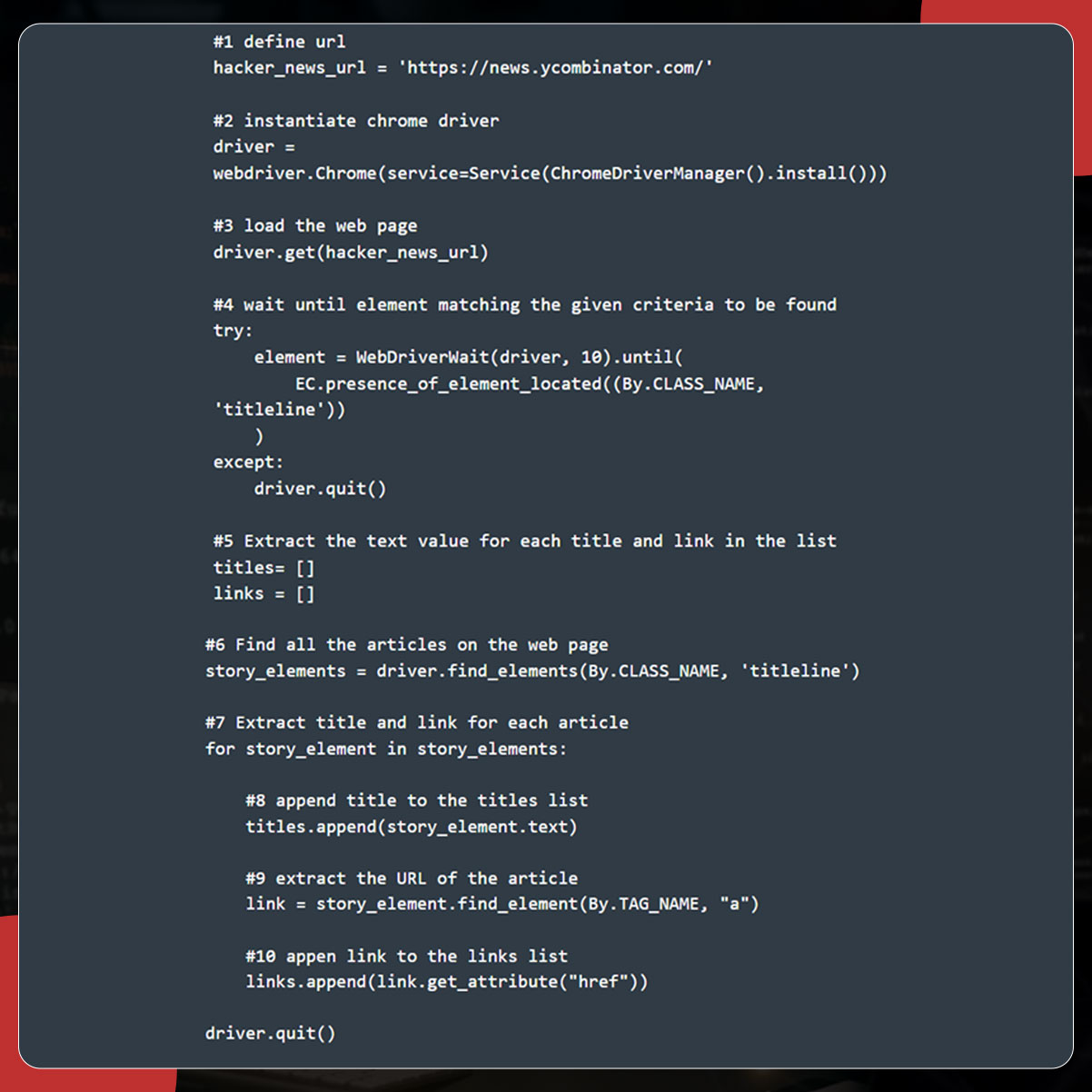
Next, export the data using to_csv().
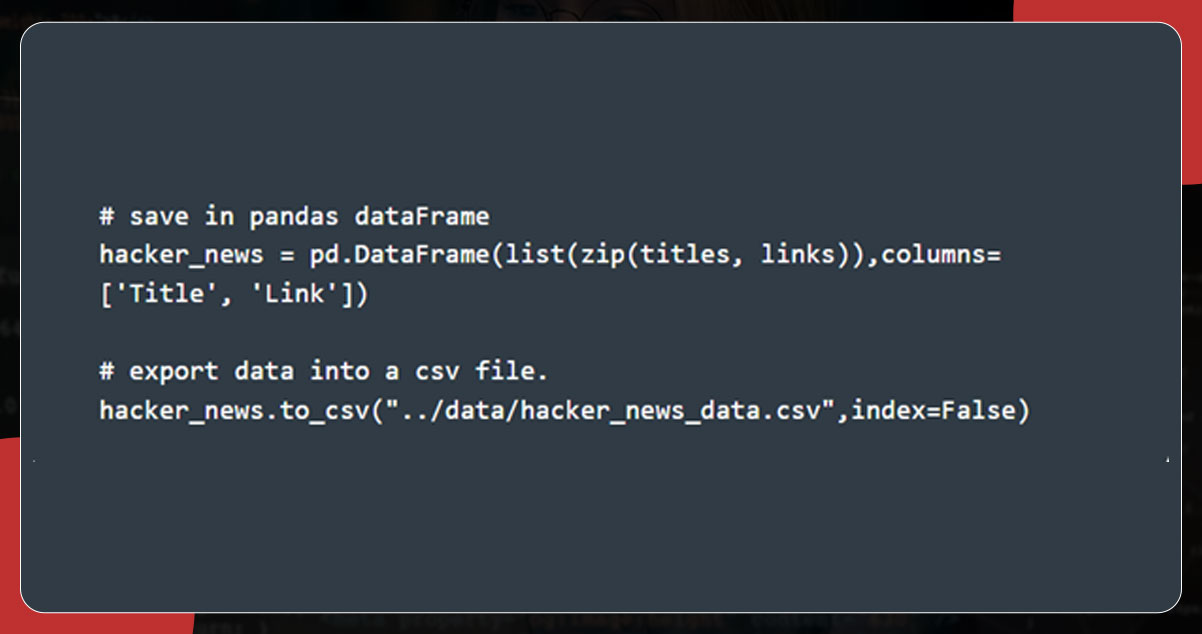
The output will be:

Handling the Infinite Scrolling
Certain dynamic web pages keep loading additional content when you scroll the page. In such a case, instruct Selenium to scroll to the bottom page, wait till the pages are loaded, and scrape the entire data. Use the below script for the scrolling function.
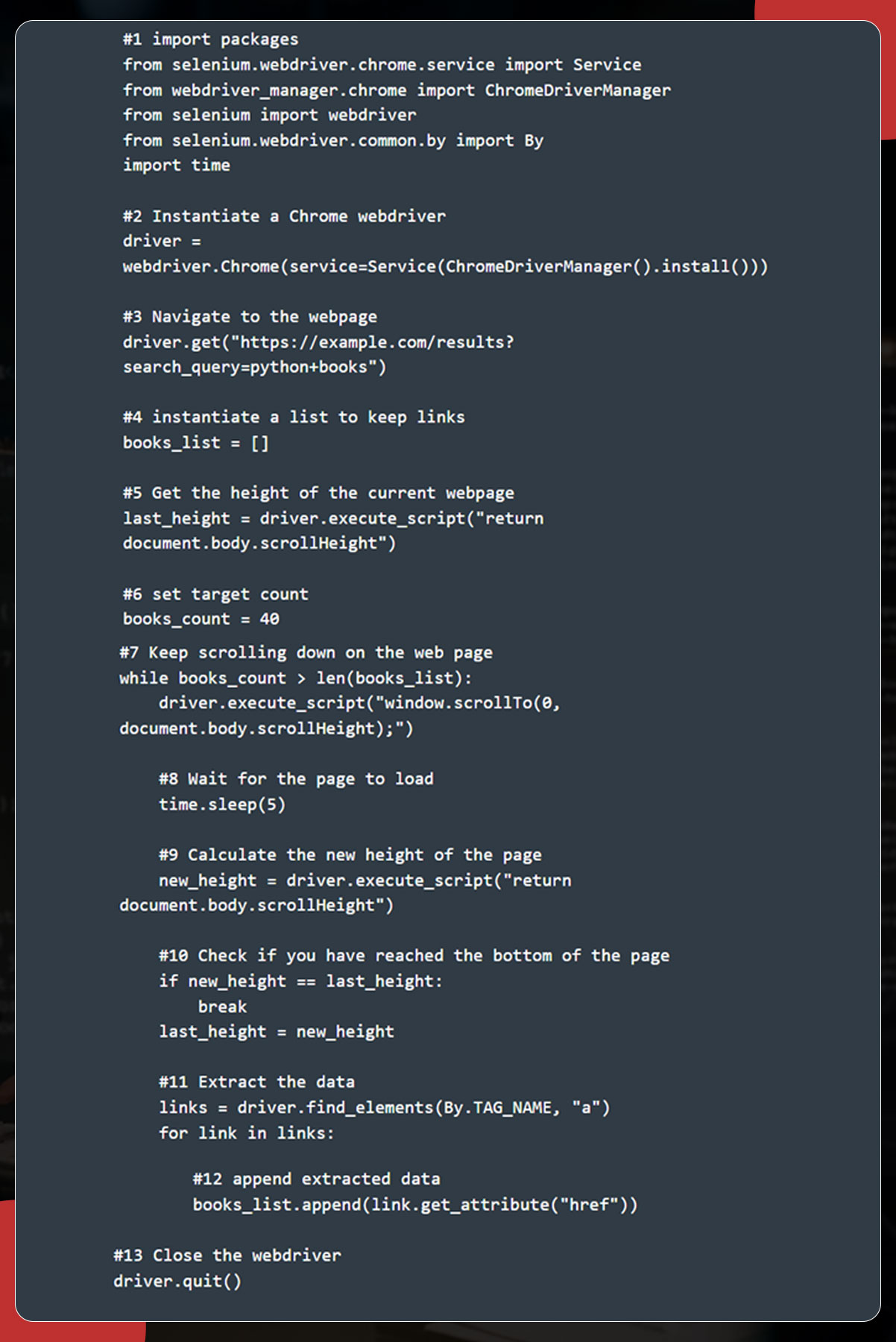
You will obtain the current page height by using the return document.body.scrolHeight script and then set the number of .links you want to scrape. The scrolling will continue until the book_count variables are more significant than the book_list length.
For more information, get in touch with iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile app data scraping requirements.