Job postings’ scraping has become crucial because everyone nowadays wants data extraction relevant to jobs. We look for great opportunities, the best companies recruiting people, and a handsome salary.
There are several websites and social networks that post jobs every day and offer employment. However, some highly ranked job posting sites are LinkedIn, Facebook, Indeed, etc. According to a recent survey, currently, there are 17 million online job postings. Out of that, getting an appropriate job as per your demand can be very challenging.
There are multiple ways to make use of job data. And here comes the role of web scraping. This is job data extraction. It will gather job listings from all relevant industries and present you with a structured form that best suits your needs. It includes:
Listed below are some of the benefits:
Find the Desired Salary: Salary is the prime factor that makes any employee work harder. Employees only ask for what the employers are willing to pay and only ask for what the industry is ready to offer. Similarly, employers also want to keep their costs less and ensure not to let go of talented staff because of salary issues. Job data scraping will help you understand what other companies offer and make the right decisions.
Relevant Data: Collecting relevant and updated information specific to the industry trends is the most crucial aspect for any business. Over time, work requirements, salaries, and corporate policies keep changing. Hence, staying updated is imperative. This is true for online job boards too.
Stay Competitive: Reliability is the key to success. The prime goal for any online job board is to acquire enough job postings to draw the attention of new visitors and retain the old ones. Being organized and consistent with data provided by HR agencies will ensure that employers trust you. Hence, they will return to you for more relevant profiles. And to achieve this, effective job boards and company profiles data extraction is required.
Job boards are the sites that help to connect employers with job seekers. Employers can easily post their jobs and invite applications from eligible job seekers. The employers find the right talent, while employees get the right opportunity per their needs. The prime asset of any job board website is the number of quality jobs that it displays. This data can make the job boards rich and valuable for users. And this is why scraping job board data is essential.
For job boards looking to grow, it becomes hectic and time-consuming to deal with the day-to-day operation of the business. Hence, seeking professional help from job data scraping services company ensures that the process is completely automated.
The service providers will gather information from industry reports, employee profiles, and job descriptions related to job postings. Job board and company profiles scraping services offer you the most updated data to investigate and post on your website, making your content more valuable, pertinent, and updated for employers and job seekers..
Web scraping jobs aggregate massive job posting data from across the web in one single place. Crawlers then crawl and extract data from the source websites containing job posting data. These scraped feeds get displayed on a job board, making it worthwhile for job search. They regularly crawl, ensuring that newer listings get noticed.

Job web scrapers collect data from thousands of sites that contain job listings. Job boards then use these data on their sites, redirecting the visitors to the original site when clicked. It removes all the pain associated with crawling, scraping, monitoring, and refining data from job posting sites and delivers them in a ready-to-use format to the job boards.
iWeb Data scraped the web for job boards and company profiles. The two most important python libraries we used for scraping the web were Requests and BeautifulSoup. The HTTP uses the Requests library to send a request to a web page. It returns a response with all web page data. Then, BeautifulSoup scrapes HTTP and returns a responsive object. Sometimes, the HTML source of the web page uses Selenium. However, web scraping only sometimes uses Selenium, but when you cannot get an HTML source, you require it.
Step 1: If you aren’t having Requests and BeautifulSoup installed, first install them using the command pip
pip install request
pip install beautifulsoup 4
After installing the libraries, import them as follows:
import request
from selenium import web driver
import time
import pd pandas
bs4 import BeautifulSoup
Step 2: Reviewing Web Page and Scraping HTML content
Now, inspect the web page that you want to scrape. Let’s take the example of Naukri.com. The resulting URL will appear like this:
URL:https://www.naukri.com/financial analysts jobs?k=financial%15analysts&l=mumbai
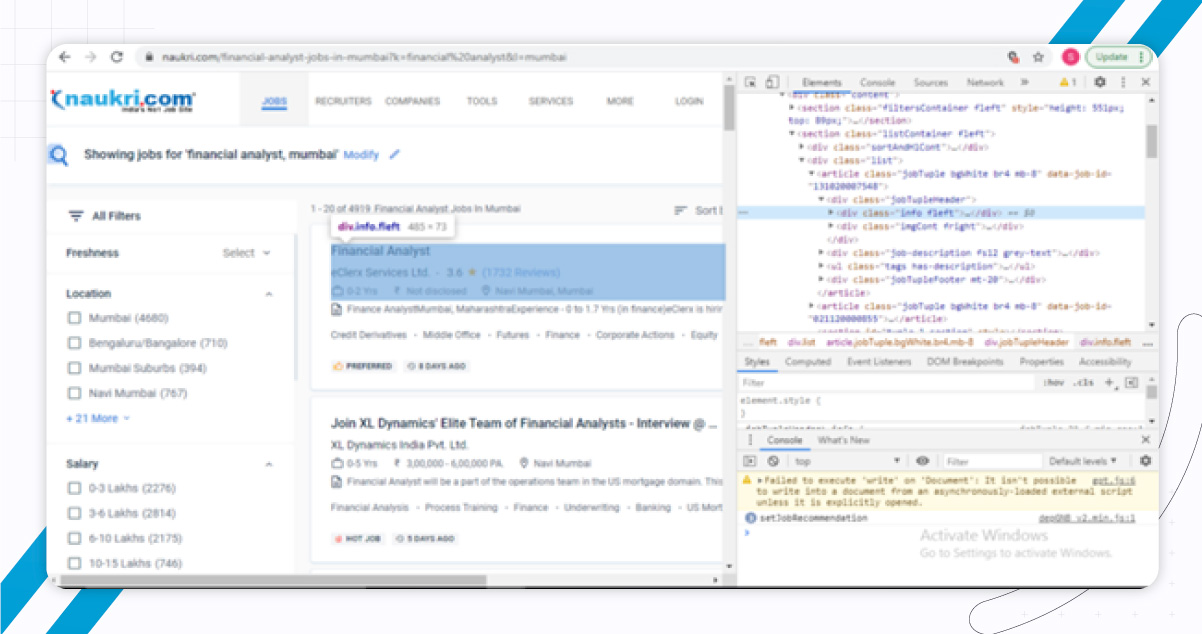
Now, you first need to mention the URL and then direct HTTP to the web page:
URL:https://www.naukri.com/financial analysts jobs?k=financial%15analyst&l=mumbai
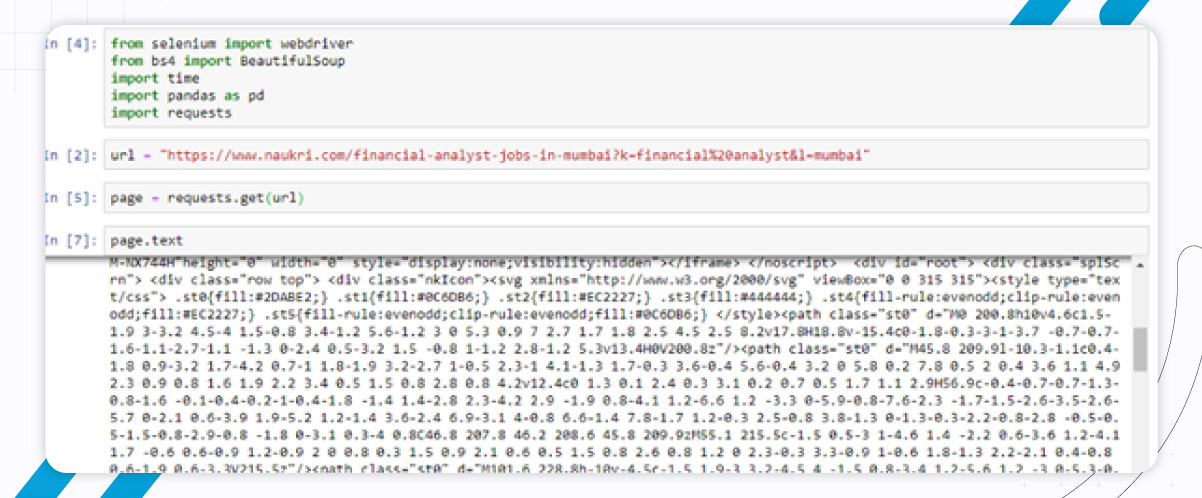
page = request.get
page .texts
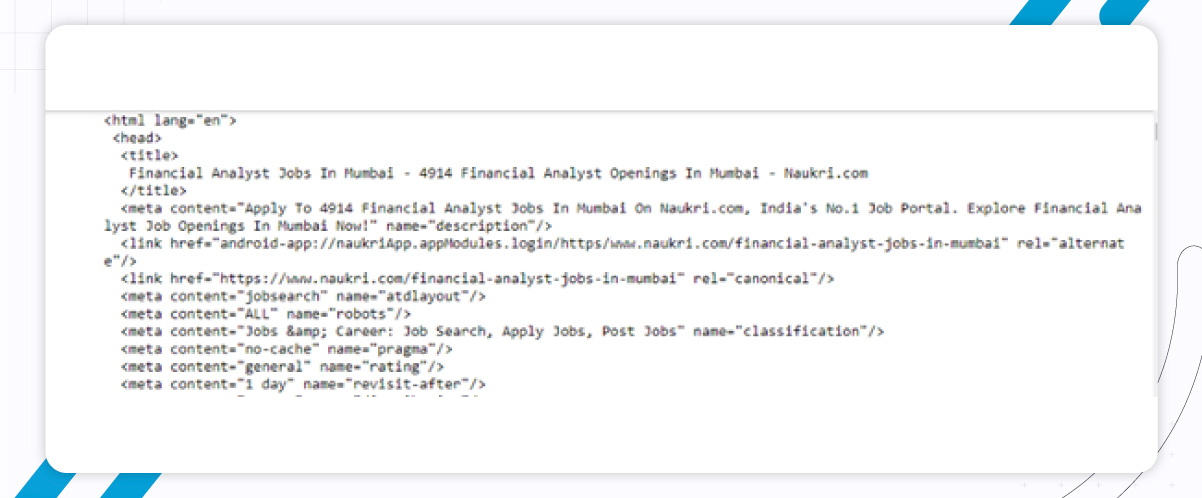
The response object doesn’t have an HTML tag. It looks like the following:
So, to achieve the HTML source, we used Python’s Selenium library. Here, we used Chrome web driver.
driver = web driver Chrome (D:\\Selenium\\chrome driver.exe)
driver. get(URL)
time .sleep
soup = BeautifulSoup (driver.page_source)
print (soup. prettify)
driver. close ()
After reaching the web page, we used the BeautifulSoup function of the bs4 library to scrape the page source.
Step 3: Extracting Data from HTML Tags: Here, we will extract data for the Company, URL, and Title. To store these fields, we first created an empty data frame.
df = pd. DataFrame(column=[“Title” “URL” “Company’’])
If you closely view this, you will find that all job cards have their respective < article > tags nested within < div > tag. So, using BeautifulSoup, we will find all tags within this <> tag. It will help to find the basics of HTML.
result = soup.find (class_=‘lists’)
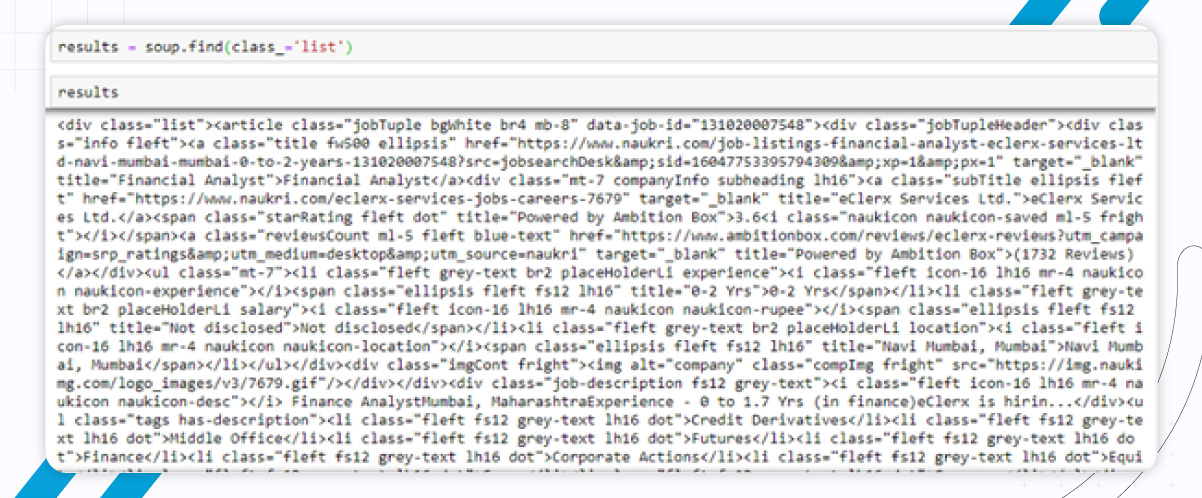
Now, job_elems = results .find_all (‘article’,class_=’jobTuple bg White br4 mb-8') will return a python list to extract data from each tag.
In the below image, you will see an anchor tag with the link to apply for the job and the job title.
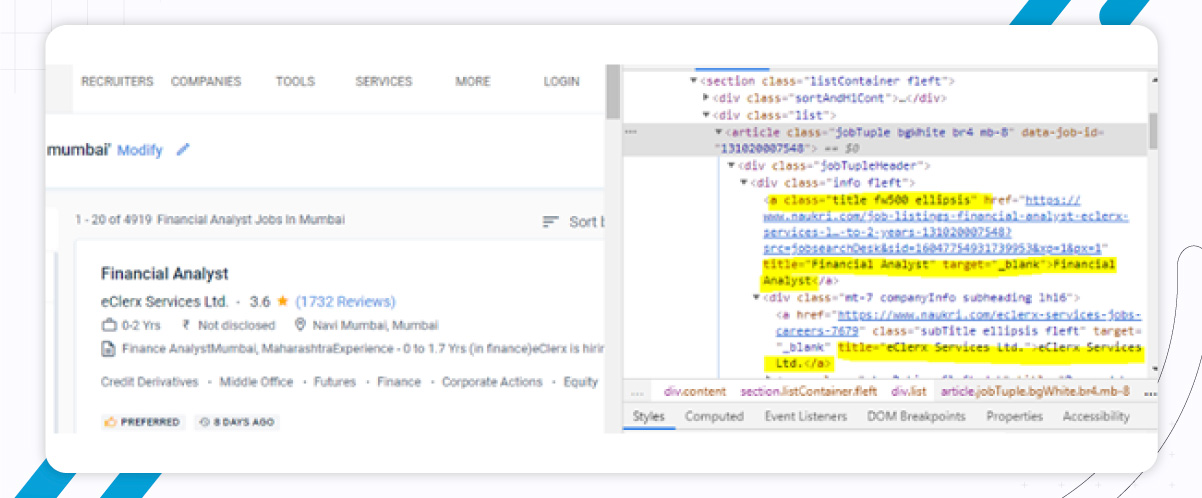
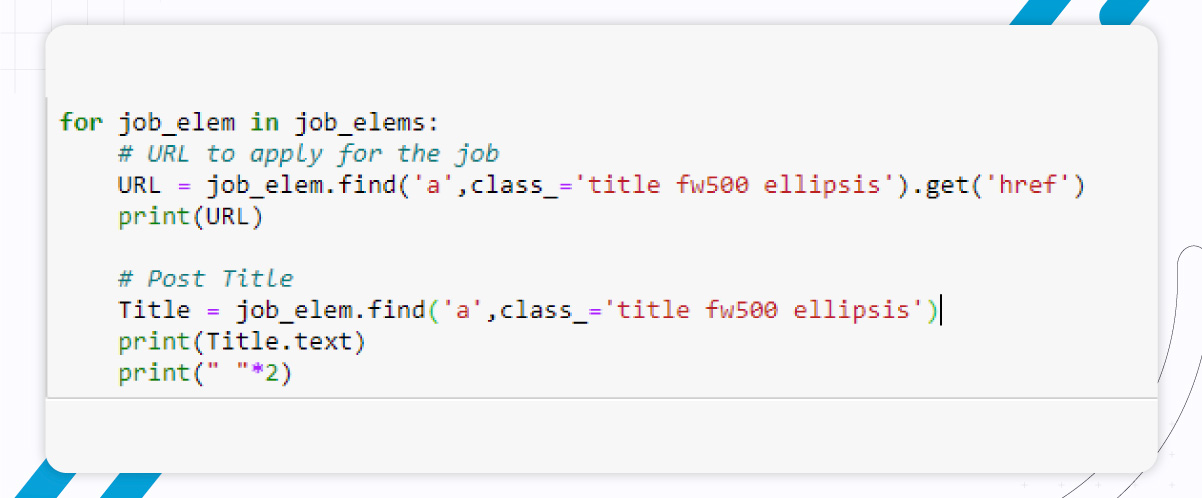
You can then extract the URL for applying the job and job title using the get(‘href’) function for the URL and .text for the Title.
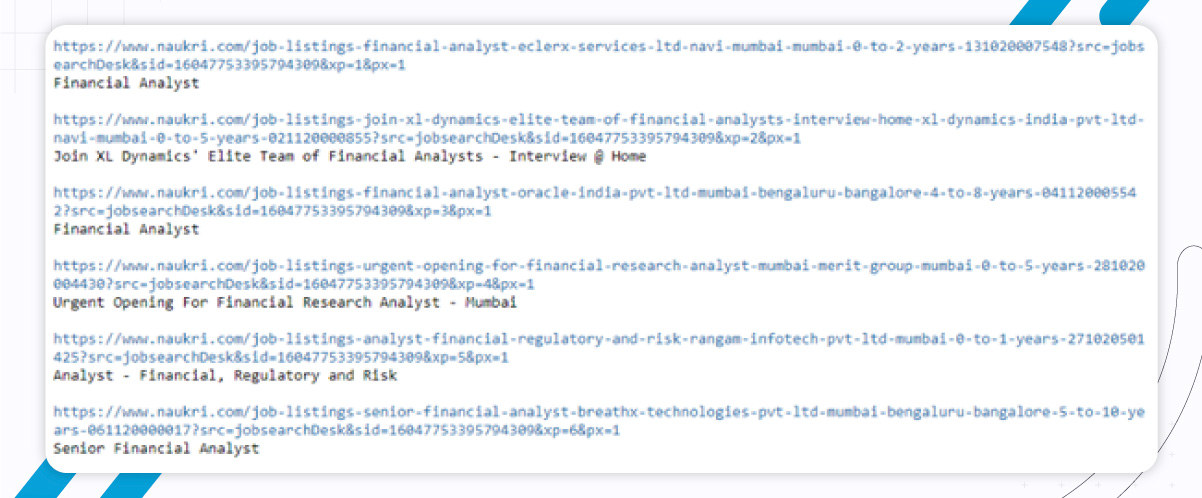
So, finally, the extracted data will appear like this.
You should be mindful of website resources while scraping the sites. Keep your requests to as minimum as possible. Make sure to send a few requests at a time. This may cause load on web servers.
For more information, contact iWeb Data now! You can also reach us for all your web scraping service and mobile data scraping requirements.