
The e-commerce industry increasingly relies on data, and scraping product information from major platforms like Amazon and other e-commerce websites is pivotal for competitive intelligence. With over 118 million listings, managing this vast amount of data is a formidable daily task. iWeb Data Scraping collaborates with numerous clients, aiding them in data extraction. However, for those considering establishing an in-house team for this purpose, this blog post provides insights into setting up and scaling such a team, addressing the intricacies and considerations involved in efficiently managing the extraction of valuable data from e-commerce giants like Amazon. Scrape Amazon and other e-commerce websites data to collect valuable information, such as product details, prices, customer reviews, and trends. By employing web scraping techniques, businesses can gather comprehensive data to analyze market dynamics, monitor competitor strategies, and make informed decisions. This process allows for the collection of real-time insights into product availability, pricing fluctuations, and consumer preferences.
In outlining the parameters for a data extraction endeavor, several assumptions shape understanding the scale, efforts, and challenges involved. The primary objective is to extract product information from a substantial cohort of 15 major e-commerce platforms, prominently featuring Amazon. The focus is on acquiring data from 15 to 20 subcategories within the expansive electronics category, contributing to an overall tally of approximately 444 distinct categories and subcategories. Refresh frequencies vary across subcategories, with differing requirements for daily, bi-daily, tri-daily, and weekly updates from a single website. The landscape relies on anti-scraping technologies on four designated websites. Additionally, the data volume exhibits dynamic fluctuations, ranging from 3 million to 6 million records daily, contingent on the specific day of the week, thereby introducing intricacies into the data extraction process.
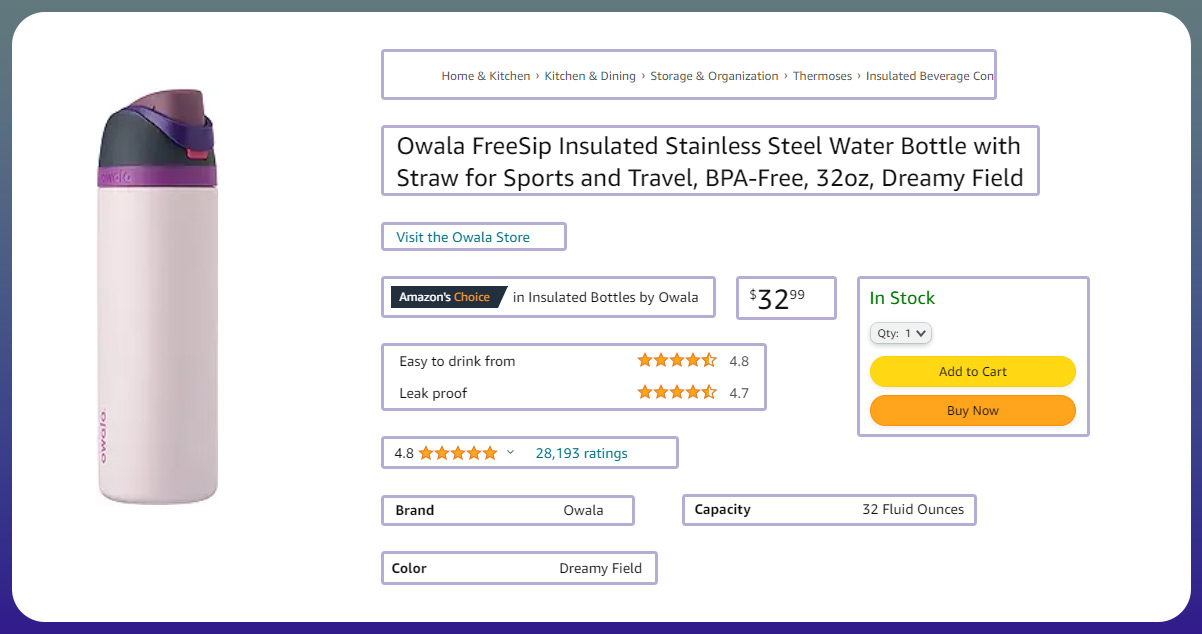
We must comprehend the data we are extracting, and for illustrative purposes, let's focus on Amazon. Identify the specific fields that are essential for e-commerce data extraction.
The refresh frequency varies across different subcategories, creating a nuanced extraction process. From one website, 10 out of 15 subcategories necessitate daily updates, five require data every two days, three mandate updates every three days, and two demand weekly data updates. Acknowledging that these frequencies might evolve based on shifting priorities within the business teams is crucial
In large-scale e-commerce data extraction projects with enterprise clients, unique requirements often arise to align with internal compliance guidelines or enhance operational efficiency. Common special requests include storing unparsed HTML data in storage systems like Dropbox or Amazon S3, integrating tools for progress monitoring (ranging from simple Slack notifications to complex BI pipeline integrations), and obtaining product page screenshots. Planning for such requirements, whether immediate or future, is essential, especially when storing data for subsequent analysis.
An often-overlooked aspect is the extraction of reviews, a critical element for enhancing brand equity and reputation analysis. Incorporating review extraction into project planning is vital, preventing budget overruns and ensuring a comprehensive understanding of customer sentiments.
Review extraction poses a distinctive challenge due to the potential volume. For instance, a product like the iPhone 5 could have 5,000 reviews, necessitating 5,000 individual requests. Consider this intensive process when estimating resources to ensure efficient handling.
The Amazon data extraction process utilizes a web scraper tailored to the website's structure. Essentially, a request is sent to the site, prompting the return of an HTML page. The subsequent step involves parsing the relevant information from this HTML source.
A web scraper uses frameworks like Python or Scrapy in a typical low-volume data extraction scenario to extract e-commerce data. It executes from the terminal and yields a straightforward conversion into a CSV file.
However, the dynamics change deals with immense volumes, such as extracting data for 5 million products daily using e-commerce data scraping services. The complexities of scaling up introduce considerations beyond the simplicity of smaller-scale processes, demanding a more robust and sophisticated approach to efficiently manage the heightened data extraction requirements.
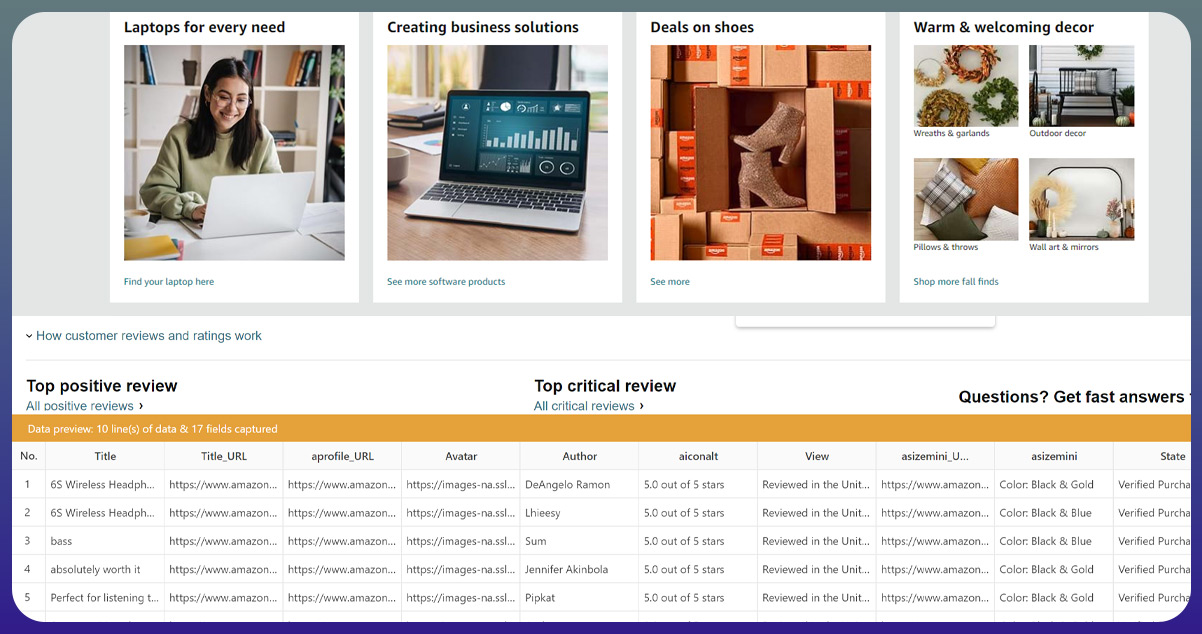
Pro Tip: In consulting projects where product data is pivotal, prioritizing data quality can be a differentiator, influencing the acceptance or rejection of a Proof of Concept (POC). Clarifying data quality guidelines and frameworks in proposals can set a project apart from competitors.
Large e-commerce websites like Amazon frequently undergo structural changes, site-wide or within specific categories. Scrapers require adjustments every few weeks to accommodate these alterations. The risk of data corruption arises if the website pattern changes during the crawling process. Implementing a pattern change detector for in-house teams helps detect changes promptly, allowing adjustments to resume scraping efficiently.

Efficiently storing data involves scalable, fault-tolerant databases with backup systems to ensure data accessibility in case of primary storage failures or security threats like ransomware.
Investing in a cloud-hosted platform becomes crucial for running scrapers reliably, especially when fetching data frequently. Cloud platforms like Amazon Web Services (AWS) or Google Cloud Platform (GCP) offer scalable solutions.
Integration with tools to navigate anti-scraping technologies is essential, with API connections to cloud-based platforms enhancing the scraper's ability to evade restrictions.
Automating data sharing with internal stakeholders can be achieved by integrating data storage with services like Amazon S3 or Azure, facilitating compatibility with analytics and data preparation tools.
Implementing DevOps practices streamlines application development, deployment, and monitoring, leveraging flexible tools from cloud platforms like AWS or GCP.
Managing changes in data structure, refresh frequency, or other aspects requires a process-driven approach. Using a single point of contact and a ticketing tool simplifies change management.
Organizing a team for a large-scale web scraping project involves various roles, including data scraping specialists, platform engineers, anti-scraping solution specialists, Q&A engineers, and team leads.
Adopting a "disagree and commit" philosophy helps navigate conflicting ideas within the team. Establishing clear steps, prioritizing company interests, outlining decision-making processes, building trust, and defining parameters contribute to effective conflict resolution.
Feel free to get in touch with iWeb Data Scraping for comprehensive information! Whether you seek web scraping service or mobile app data scraping, our team can assist you. Contact us today to explore your requirements and discover how our data scraping solutions can provide you with efficiency and reliability tailored to your unique needs.