
Web scraping is the process of automatically extracting data from websites. Achieve this through various methods, such as utilizing APIs or Python libraries like BeautifulSoup, Scrapy, and Selenium. Scrapy is particularly suitable for larger-scale scraping projects, while Selenium is primarily a web testing tool that helps with data extraction. This article will throw the limelight on the steps to scrape Amazon reviews with BeautifulSoup.
BeautifulSoup, a Python library, excels at parsing data from HTML and XML files and can be easily installed with the command "pip install bs4." We find BeautifulSoup to be straightforward and user-friendly. For example, we decided to extract Amazon reviews while hunting for a new cat tree for my feline companion, Bellini.
Let's take a glance at the cat tree available on Amazon:
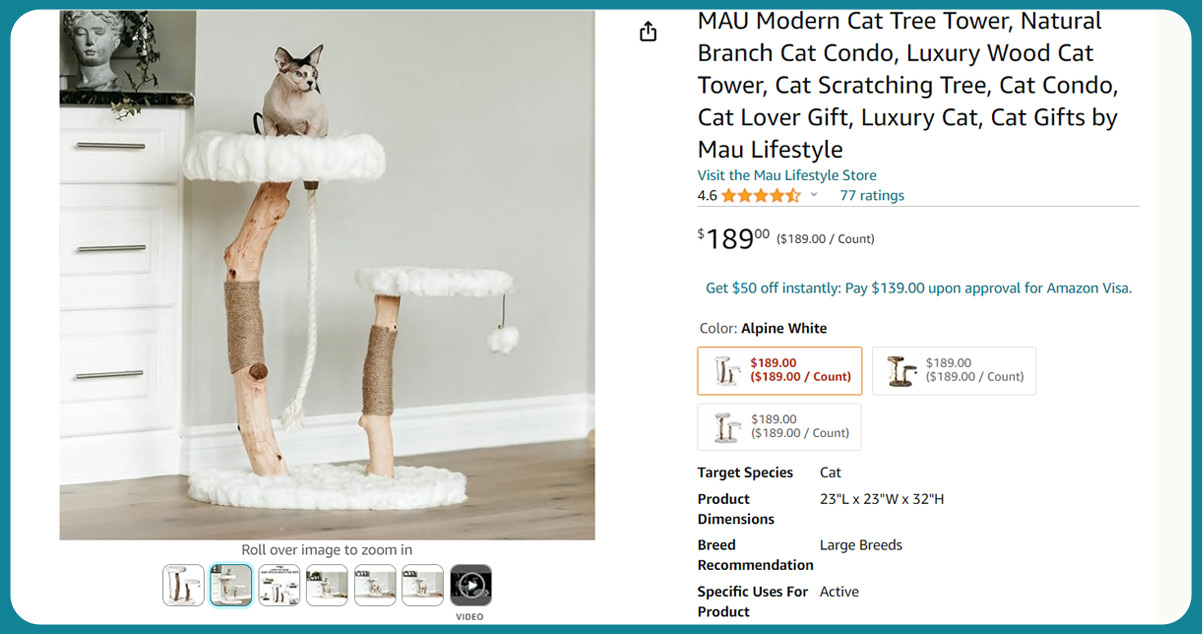
In this article, we'll guide you through the process of Python-based web scraping to extract individual Amazon reviews. We'll begin by focusing on one review at a time to ease into the process.
It's beneficial to begin by inspecting the Amazon webpage from which we intend to extract data to grasp the concept of BeautifulSoup and how it interacts with HTML tags.
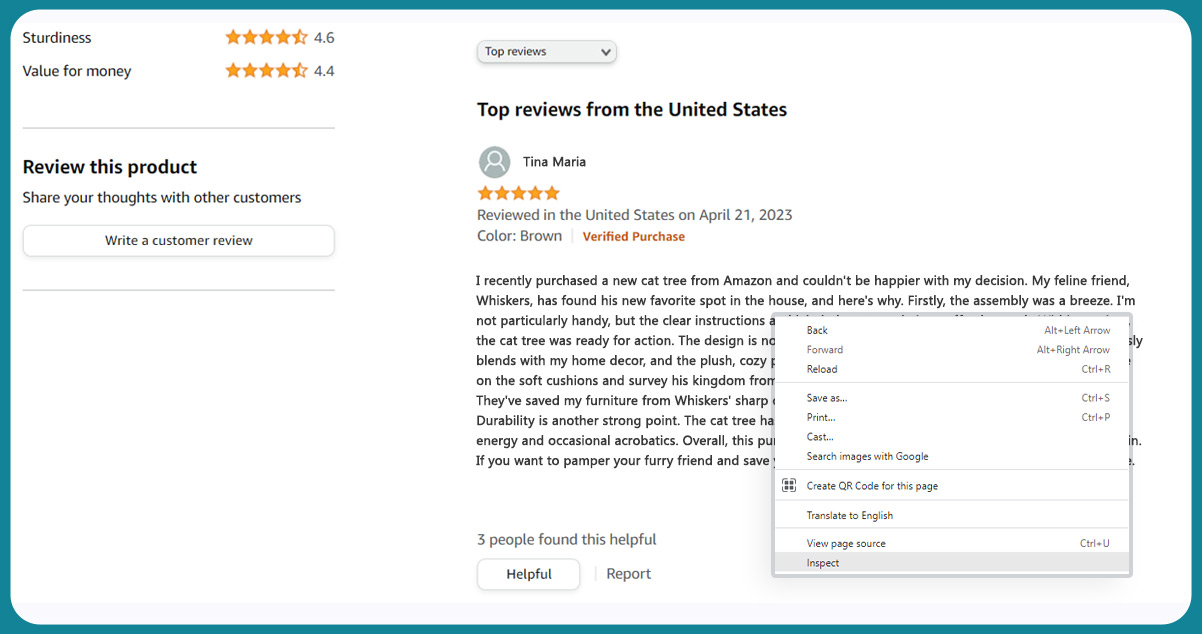
While Amazon reviews data scraping, right-click on the review to access the webpage's source code and select "Inspect." Alternatively, you can navigate to the HTML text by going to the "View" menu and then selecting "Developer" and "Developer Tools." Once you've clicked on "Inspect," the HTML structure of the webpage will appear on the right side, essentially breaking down the entire page.
What's particularly useful is that as you scroll over elements in the HTML text on the right side, you find highlighted corresponding sections on the left (the webpage itself). For instance, if you're interested in the product title, like "MAU Modern Cat Tree Tower, Natural Branch Cat Condo" with the h1 tag, it will be highlighted on the left side when you move over the h1 class on the right. This feature makes pinpointing the specific elements you want to scrape easier.
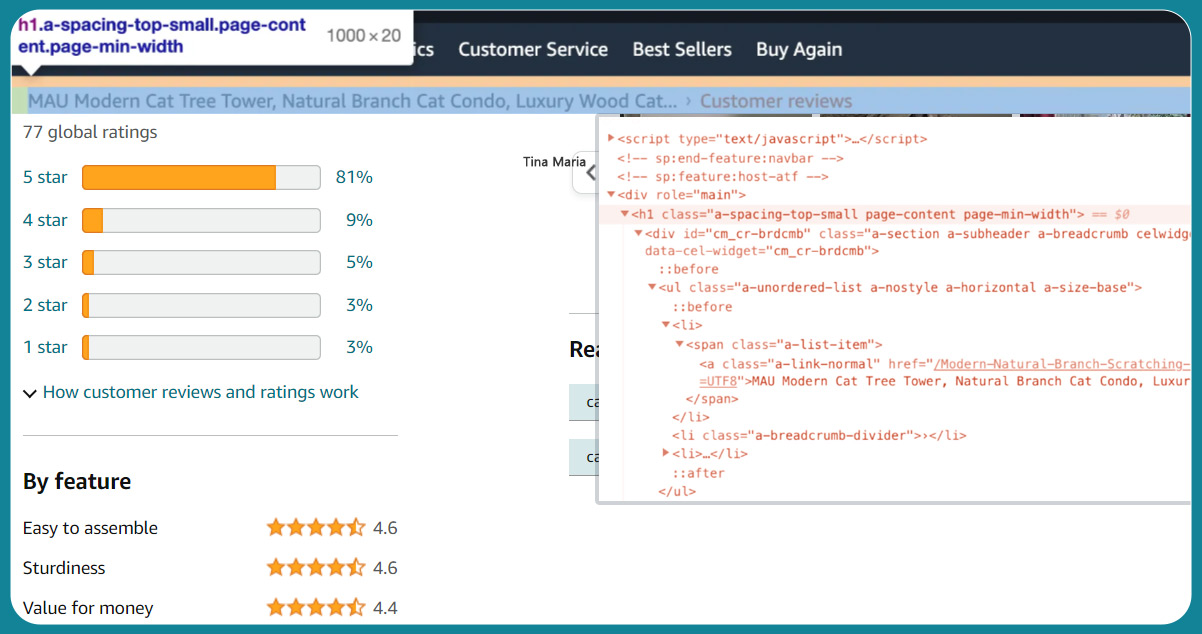
Now, onto the exciting part – Python and BeautifulSoup! To kick off our Python script for scraping e-commerce data, let's begin by importing the necessary libraries and defining the headers we'll use when reading the webpage:


We can use "urllib" and "urlopen" to open the desired URL effortlessly. We've crafted a handy helper function that fetches web data and converts it into HTML code using BeautifulSoup, specifying our intent to use the HTML parser:

With the assistance of my helper function, we can retrieve the page content in the form of HTML code and store it as a "soup":

Now that we've obtained the webpage content as HTML code, we'll begin by extracting the product title. Available as an h1 header, we'll locate the first h1 tag using the following method:

It's important to note that this retrieval yields a single BeautifulSoup element with both "id" and "class" attributes:

To obtain the actual header text and perform some data cleaning, we can utilize the .get_text() function. Here's how we can achieve that:

BeautifulSoup offers the convenience of fetching all elements with h1 tags through the .find_all() function:

Upon inspecting the type of all_headers, you'll notice that it's a "ResultSet":
type(all_headers)To extract text from each item within the ResultSet, we must iterate them individually. Below is an example demonstrating how to loop through each item and print its respective text:

Now that we have successfully retrieved our product title, we will scrape product reviews for the "MAU Modern Cat Tree Tower" using an e-commerce data scraper. The next step is to return to the webpage and inspect the HTML code to collect product reviews. It allows us to understand its structure, identify relevant tags, and pinpoint the necessary attributes for extraction.
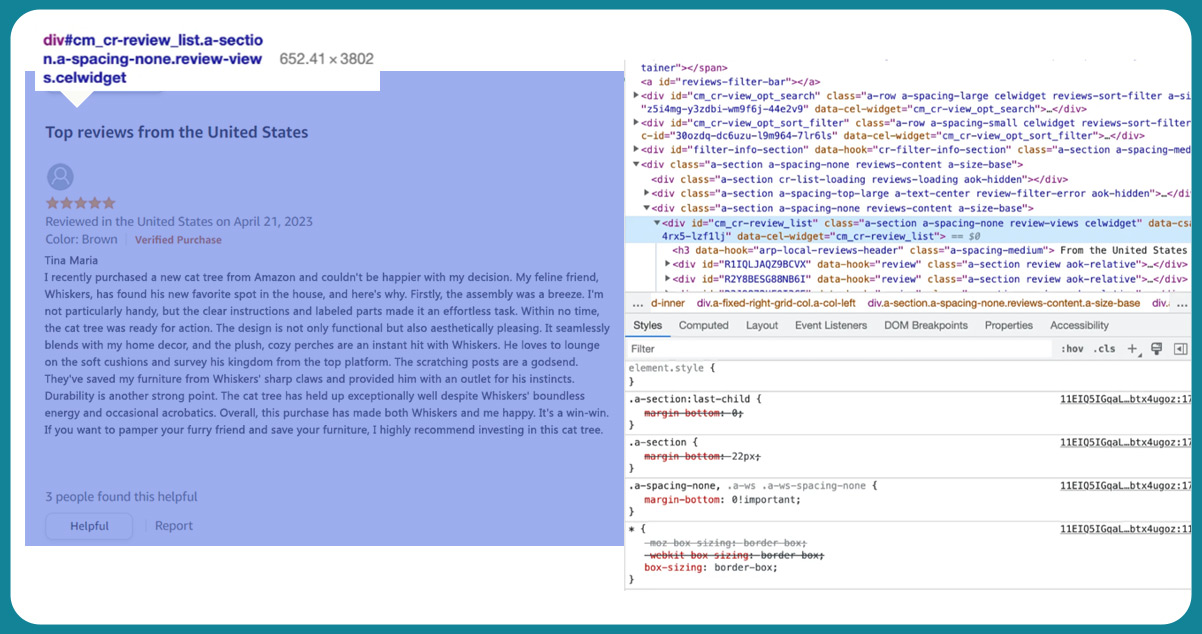
Upon inspecting the HTML text, we've identified an <div> element with the "id" attribute set to 'cm_cr review-list' and a "class" attribute as 'a-section a-spacing-none review-views cel widget.' It suggests that the review list is within this section. You can see it highlighted on the left side, indicating its presence on the webpage.
Scrolling down a bit further, we notice that each review possesses a unique "id" and a "data-hook" attribute named 'review.' While additional information is available, these attributes are all we require for our current purpose.

We can efficiently extract review information by utilizing the <div> tag and the "data-hook" attribute. We'll employ the .find_all() function once more, which will provide an iterable containing all the HTML associated with each review encapsulated within a <span> element featuring the 'review' as its "data-hook" attribute:

Upon examining our initial review, you can spot several familiar tags and attributes we observed on the webpage. We've highlighted the "id" attribute we encountered on the webpage. Keep in mind that this is the raw HTML code, so it may appear a bit unstructured:

However, focusing on the <span>tags within the first review makes the information appear neater and more organized. For instance, we can see the profile name "Tina Maria":

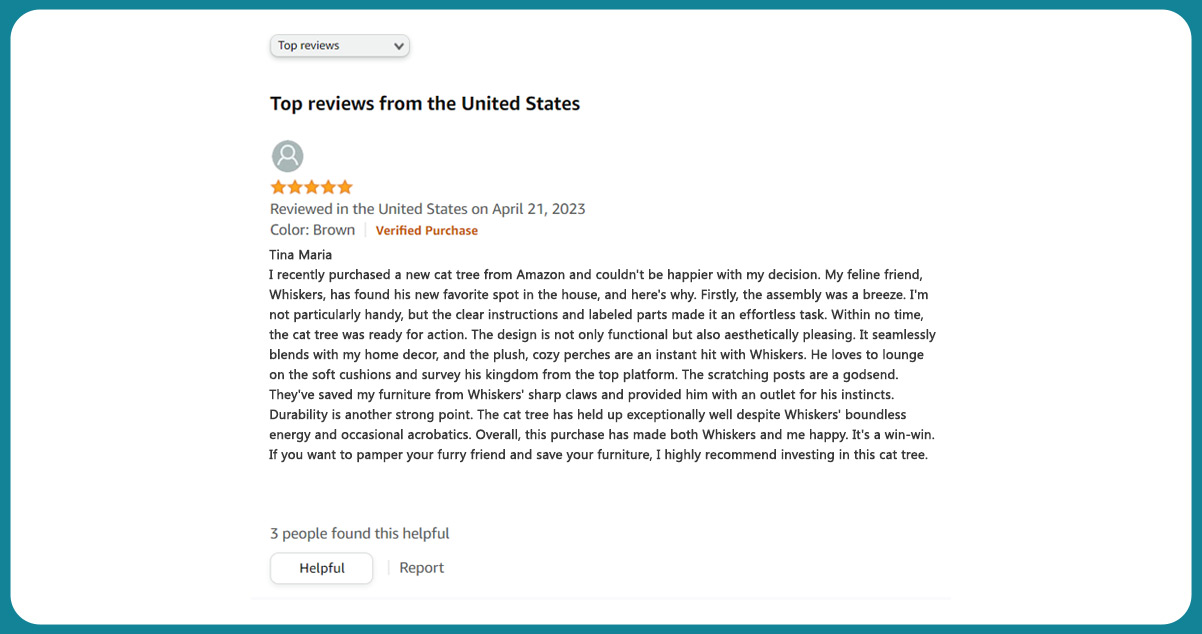

Amazon data scraping services need to identify the relevant tags to extract additional information from the review. For instance, to obtain the profile name, we utilize the <span> tag and search for elements with a "class" attribute named "a-profile-name":

To retrieve the number of stars assigned in the review, we can employ the following approach:

To extract the review content from the first review, you can still utilize the <span>element with the class attribute set to "review-text" and then apply the .get_text() method

To extract the review content for all reviews, you can loop through the list of reviews and use the "review-text" class attribute within the loop like this:

After performing some data cleaning, we now have a list of Amazon reviews that looks like this:

Indeed, once you grasp the HTML structure of a webpage through inspection, extracting information using BeautifulSoup becomes relatively straightforward.
However, it's crucial to acknowledge that every website has its unique structure and layout. Consequently, how this website employs HTML tags and attributes will likely differ from another website. Scrapping a different website, you won't encounter the same HTML elements, tags, and attributes, as demonstrated in this example. Therefore, it's essential to carefully align the attributes with the specific information you intend to extract, accounting for these variations in website structure.
Conclusion: In this concise post, we've covered the process of scraping Amazon customer reviews using BeautifulSoup in Python. If you're new to web scraping, we trust that this guide has been informative and beneficial as you embark on your web scraping journey! To extract the review content from the first review, you can still utilize the <span> element with the class attribute set to "review-text" and then apply the .get_text() method
For further details, contact iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile app data scraping needs.