
In today's data-centric era, where gathering and analyzing information is paramount for success, web-scraping retail data has become an indispensable asset for businesses and individuals. It offers the means to extract valuable data from websites, equipping users with invaluable insights, a competitive edge, and the ability to make well-informed decisions.
This article will explore using Python for web scraping, explicitly focusing on extracting product details from Costco's website. Our primary area of interest will revolve around the "Electronics" category, particularly emphasizing the "Audio/Video" subcategory. We aim to harvest essential information such as product name, brand, color, item ID, category, connection type, price, model, and product descriptions for each electronic device.
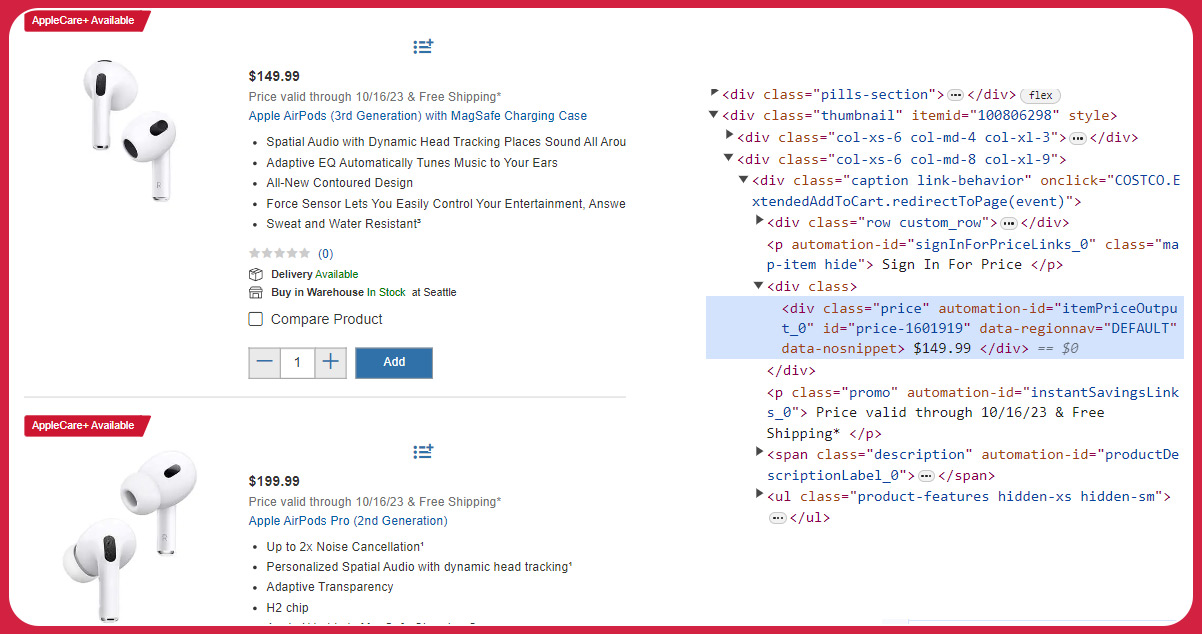
An API, which stands for Application Programming Interface, is a bridge that facilitates data exchange between different software applications. In the context of Costco, their API contains and manages various types of data, such as product information, that are typically visible in a User Interface. The API allows you to extract and integrate this data into your software, creating a seamless connection.
APIs are crucial in enabling efficient and secure data sharing, especially when dealing with large volumes of information. They provide a reliable means for different sources to exchange data while maintaining data integrity and security.
Costco's API interacts with the Costco store locations API, offering access to updated inventory details, product information, and location-specific data. This functionality enhances the utility of Costco's website for data collection purposes. Leveraging Costco API scraping is advantageous in maintaining competitiveness within your specific market due to its competitive pricing.
There are several advantages to extracting data from the Costco API, which can benefit retailers competing with Costco and smaller businesses seeking to compete effectively in their respective markets. Here are a few key examples:
Inventory Tracking
Costco's extensive network of over 500 locations in the United States and its membership deals make the store a popular choice for many consumers. Monitoring Costco's inventory through web scraping can provide valuable insights into local demand for specific products or services. By connecting to the API of nearby Costco locations, small businesses can access data that is relevant to their areas.
For instance, if you observe that Costco is frequently running out of a product you specialize in, you can strategically promote your product and pricing through localized online advertisements, taking advantage of shortages at major retailers when consumers are open to exploring alternative options.
Identifying Competitive Price Points
Price is a crucial factor for many consumers, and one of the main benefits of a Costco membership is access to reduced prices and bulk purchase deals. Other significant retailers often employ similar pricing strategies. Scraping product prices from Costco allows you to gain insight into the average industry pricing. Combining Costco product data with data from other retailers enables you to develop a comprehensive understanding of the broader market, making it easier to identify your competitive position.
Once you've pinpointed the ideal price point relative to your competitors, you can initiate marketing efforts highlighting this price point and the unique product details, leveraging insights generated from web scraping.
Consumer Sentiment Analysis
Like many other websites, Costco offers space for customer reviews and ratings. It provides a valuable resource for assessing whether a product meets specific needs and how it compares to competing models. Scraping these reviews simplifies the process of identifying recurring patterns in customer feedback. For example, if a significant number of customers consistently mention the high quality of a product's material, you can begin to establish a consensus.
While it's possible to analyze these reviews manually, Costco Scraper makes it more efficient to compare and analyze the data side by side. For competitors, consumer sentiment data offers the opportunity to draw inspiration from the aspects of Costco's product design that consumers love or to develop products that address customers' issues with existing offerings.
While you should ultimately define your organizational goals independently of major retailers, you must be aware of the value they provide to consumers when formulating your marketing strategies and positioning your product or brand as a compelling alternative.
It is essential to set up the required libraries and dependencies to scrape Costco product data using Python. Our scraping tool is Python, complemented by two widely-used web scraping libraries: Beautiful Soup and Selenium. Beautiful Soup excels at parsing HTML and XML documents, while Selenium automates web browsers for testing and data extraction.
After installing these libraries, our initial step involves scrutinizing the website's structure to pinpoint the data elements for extraction. It entails thoroughly examining the website's HTML code and identifying specific tags and attributes that house the data of interest.
With this knowledge in hand, we will proceed to craft our Python code for web scraping. Our approach will entail utilizing Beautiful Soup for data extraction and employing Selenium to automate browser interactions for effective web scraping. Once the script is complete, save the harvested data in a CSV format for convenient analysis.

Pandas: Pandas serve as a versatile library for data manipulation and analysis, making it an ideal choice to handle data scraped from websites. It is instrumental in converting data from a dictionary into a more manageable DataFrame format, tailored for efficient data manipulation and analysis. Additionally, Pandas facilitates the conversion of the DataFrame into a CSV format, ensuring the data is readily accessible and usable in various software applications.
Lxml: Lxml, on the other hand, is a robust library designed for processing XML and HTML documents. It can parse the HTML or XML content of web pages. In this context, 'lxml' is paired with 'et,' which stands for Element Tree, a module within the 'lxml' library. This combination streamlines the navigation and exploration of the web page's structured tree, offering an efficient means to work with XML and HTML documents.
Beautiful Soup: Beautiful Soup, another essential library, simplifies the web scraping process by allowing the parsing of HTML and XML content. It excels at extracting desired data from web pages. In this application, BeautifulSoup can parse the HTML content obtained from the webpage, streamlining the data extraction process.
Selenium: Selenium, a library in its own right, specializes in automating web browsers. It is indispensable for automating interactions with web pages, such as clicking buttons and filling out forms.
The Selenium library and the webdriver module empower users to automate interactions with webpages effectively. By creating a web driver instance and navigating to specific URLs, Selenium with webdriver enables the retrieval of webpage source code, which can subsequently be parsed and analyzed.

When working with Selenium, a crucial step is instantiating a web driver. A web driver represents a class tailored to engage with specific web browsers such as Chrome, Firefox, or Edge. In the provided code snippet, we're creating an instance of the Chrome web driver through webdriver.Chrome(). This line empowers us to take command of the Chrome browser, mimicking user interactions with web pages.
This web driver equips us to navigate diverse web pages, interact with page elements, complete forms, and initiate button clicks while seamlessly extracting the required data. With the capabilities of Selenium and web drivers, you can elevate your web scraping endeavors, streamlining data collection tasks and automating them with finesse.
With a foundational grasp of web scraping and our chosen tools, it's time to delve into the code. In this segment, our focus shifts to a detailed examination of the functions established for the web scraping procedure. The use of functions is instrumental in structuring the code, ensuring its reusability, and simplifying maintenance. This approach enhances code comprehensibility, ease of debugging, and adaptability.
In the following sections, we will elucidate the role of each function in our codebase and how it contributes to the holistic web scraping process.

We've crafted a function named "extract_content" that operates with a solitary input— the URL. This function harnesses the Selenium library to guide us to the specified URL, capture the page source, and transform it into a BeautifulSoup object. The lxml parser converts this object into an Element Tree object through "et.HTML()". The ensuing DOM object empowers us to efficiently navigate and explore the web page's tree-like structure, facilitating extracting the requisite information from the page.
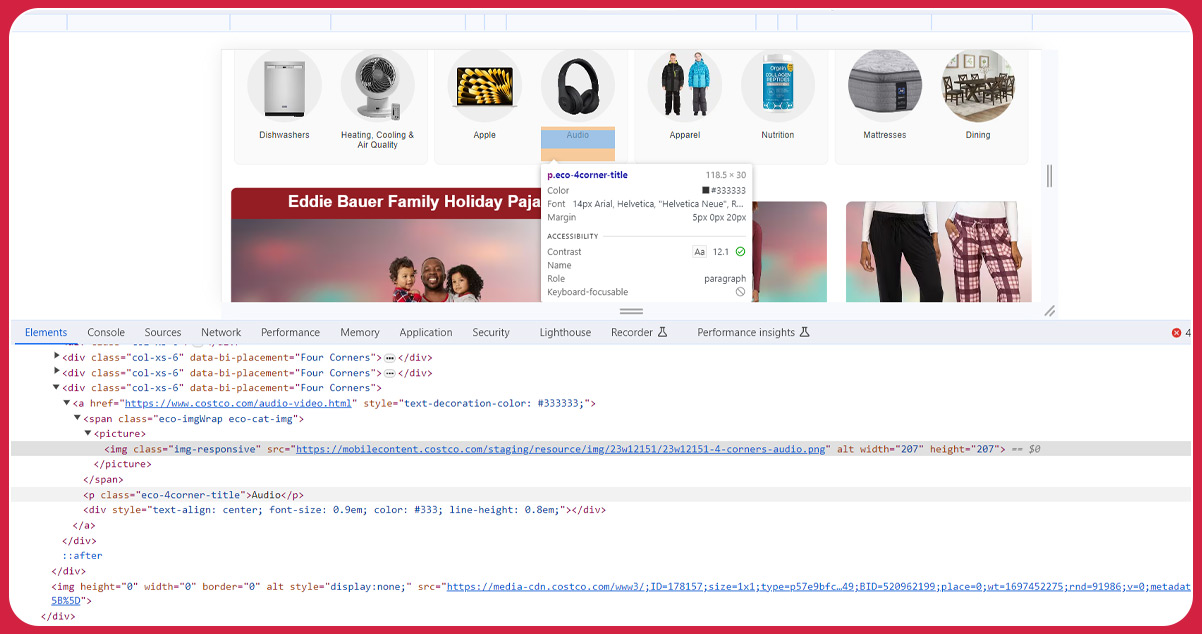
This function employs the "find_element()" method in conjunction with "By.XPATH" to pinpoint the "Audio/Video" category link within the Costco electronics website. Subsequently, the "click()" method initiates navigation to this designated page. This function streamlines the process of visiting a particular link on the website by simulating a user click, thus enabling us to extract the contents of the ensuing page efficiently.

Following navigation to the Audio/Video category, this function can harvest links related to the four displayed subcategories, thus facilitating subsequent scraping of these individual pages. The function relies on the "xpath()" method associated with the DOM object, which effectively identifies all elements conforming to a specified xpath expression. In this context, configure the xpath expression to select all "href" attributes of "a" elements nested within elements characterized by the "categoryclist_v2" class.

Now that we've acquired the four subcategory links, our next step is initiating the scraping process for all the product links within these categories.

This function leverages the previously defined "category_links()" and "extract_content()" functions to navigate to each subcategory page and collect the links to all products within these subcategories. It employs the "xpath()" method of the content object to select all product links based on a specific xpath expression. This expression targets all "href" attributes of "a" elements, nested within elements identified by the automation-id "productList" and possessing "href" attributes ending with ".html."
Scrape Costco data to collect product names. Given the acquired product links, we will scrape essential product attributes. This function utilizes a try-except block to manage potential errors gracefully during the feature extraction process.

Within the try block, the function employs the "xpath()" method of the DOM object to capture the text from the element tagged with the "product-title" class. If the product name is unavailable, the function gracefully assigns the value "Product name is not available" to the 'product_name' column within the "data" data frame corresponding to the current product.
Let's discuss the function responsible for extracting the product's brand information.

In this function, the "xpath()" method of the DOM object can capture the text associated with the element featuring the "itemprop" attribute as "brand." If, for any reason, the brand name is unavailable, the function thoughtfully designates the 'brand' column with the value "Brand is not available."
Let's delve into the function responsible for extracting the product's price.

Within this function, the "xpath()" method of the DOM object is applied to capture the text from the element marked with the automation-id "productPriceOutput." In cases where the price information is not accessible, the function thoughtfully designates the 'price' column with the value "Price is not available."
Now, let's explore the function for retrieving the product's item ID.

In this function, the "xpath()" method of the DOM object helps capture the text linked to the element identified by the "id" attribute as "item-no." In scenarios where the product ID isn't accessible, the function judiciously designates the 'item_id' column with the value "Item ID is unavailable."
Let's delve into the function of extracting the product's description.

In this function, the "xpath()" method of the DOM object is applied to retrieve the text associated with the element having the automation-id "productDetailsOutput." When the product description is absent, the function prudently designates the 'description' column with the "Description is unavailable."
Now, let's move on to the function designed for extracting the product's model information.


In this function, the "xpath()" method of the DOM object is employed to capture the text associated with the first div element, which serves as the following sibling of the element containing the text "Connection Type." In cases where information about the product's connection type is missing, the function considerately assigns the 'connection_type' column with the value "Connection type is not available."
Now, let's proceed to the function responsible for extracting the product's category type.

In this function, the "xpath()" method of the DOM object can capture the text from the 10th element featuring the "itemprop" attribute as "name." When information about the product's category is absent, the function thoughtfully designates the 'category' column with the "Category is not available."
Next, let's delve into extracting the product's color.

This function utilizes the "xpath()" method to extract the text from the first div element, which is the subsequent sibling of the element containing the text "Color." When information regarding the product's color is unavailable, the function considerately designates the 'color' column with the value "Color is not available."
Now, let's transition into the next phase—the commencement of the scraping process. Here, we consolidate our efforts by sequentially invoking each previously defined function to obtain the targeted data.

Our initial action involves directing the web driver to the Costco electronic categories page through the specified URL. Subsequently, we employ the "click_url()" function to navigate to the Audio/Video category and retrieve the HTML content of that particular page.

For storing the scraped data, we'll construct a dictionary that includes essential columns: 'product_url,' 'item_id,' 'brand,' 'product_name,' 'color,' 'model,' 'price,' 'connection_type,' 'category,' and 'description.' This dictionary will serve as the foundation for our data frame, aptly named 'data,' designed to house all the acquired data.

The script now invokes the "product_links(url_content)" function, which is responsible for extracting product links found within the four subcategories of the Audio/Video category. Integrate these collected links into the 'product_url' column of the data frame.

This code section iterates through each product within the 'data' data frame. It begins by extracting the product URL from the 'product_url' column and subsequently employs the "extract_content()" function to acquire the HTML content of the product page. Then, it calls the pre-defined functions to extract distinct attributes, including model, brand, connection type, price, color, item ID, category, description, and product name. Assign these extracted values to the respective columns within the data frame at the designated index. This process effectively scrapes all the required information for each product.

In this final code segment, the "data" frame, housing all the meticulously scraped product information, is exported to a CSV file christened 'costco_data.csv.' This streamlined exportation ensures the scraped data is readily accessible and amenable for subsequent analysis or utilization.
Conclusion: Our journey has equipped us with the know-how to effectively utilize Python and its web scraping libraries to extract product details from Costco's website, explicitly emphasizing the "Audio/Video" subcategory within the broader "Electronics" category. Our Costco data scraping services navigated through inspecting the website's structure, pinpointing the target elements, and scripting Python to automate the web scraping endeavor.
Mastery of these web scraping fundamentals empowers you to access a wealth of invaluable data applicable to various purposes, from market research to in-depth data analysis. With the prowess to extract and dissect data from diverse websites, the opportunities are boundless.
For further details, contact iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile app data scraping needs.