
Nordstrom is an American retail giant offering diverse products, including jewelry, shoes, cosmetics, clothing, fragrances, handbags, wedding furnishings, and home goods. Nordstrom's stores also feature in-house cafes, espresso bars, and restaurants, providing customers with a unique shopping experience.
Within Nordstrom, you can find the latest trends in men's, women's, and children's clothing, along with various accessories, all at competitive prices. The products are with detailed descriptions and pricing information. We specialize in providing top-notch Nordstrom Product Data Scraping Services, allowing you to extract data from Nordstrom's website efficiently.
As of 2021, Nordstrom operates 358 stores, with an average of approximately 40 stores in each U.S. state. The company's reach extends to around 90 countries and boasts a dedicated workforce of about 72,500 employees. 2018, Nordstrom held 193 trademarks, highlighting its commitment to brand excellence. As of 2020, Nordstrom's annual revenue is an impressive $10.357 billion.
Nordstrom is a prominent U.S. fashion retail industry leader, complemented by its globally renowned e-commerce platform. Due to its extensive and high-quality data offerings, Nordstrom is a coveted target for web scraping, especially within the fashion sector. The primary goal of scraping online fashion websites for product data or conducting online apparel site data scraping is to evaluate and understand the top players in the online fashion industry.
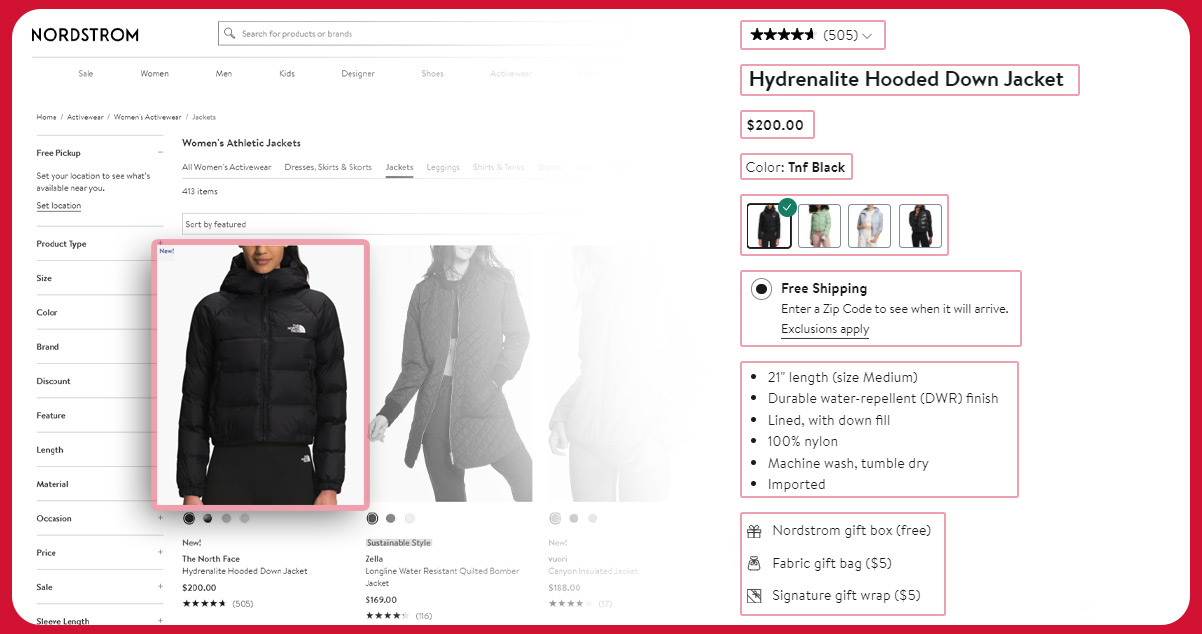
This tutorial will explore how to perform web scraping on Nordstrom using Python. We will delve into two key aspects:
We will utilize well-known Python web scraping tools, namely httpx, and parsel, to achieve this. Our approach to parsing the data will involve employing hidden web data techniques.
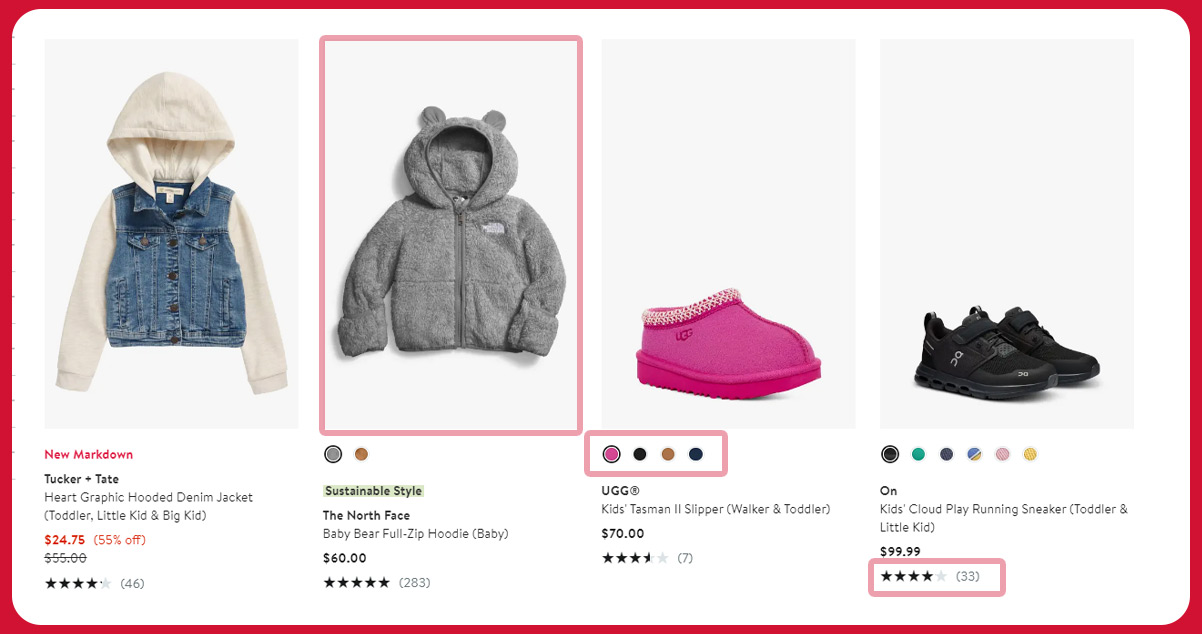
Business intelligence provides insights into the current market landscape, including product availability, pricing, color variations, dimensions, and additional services.
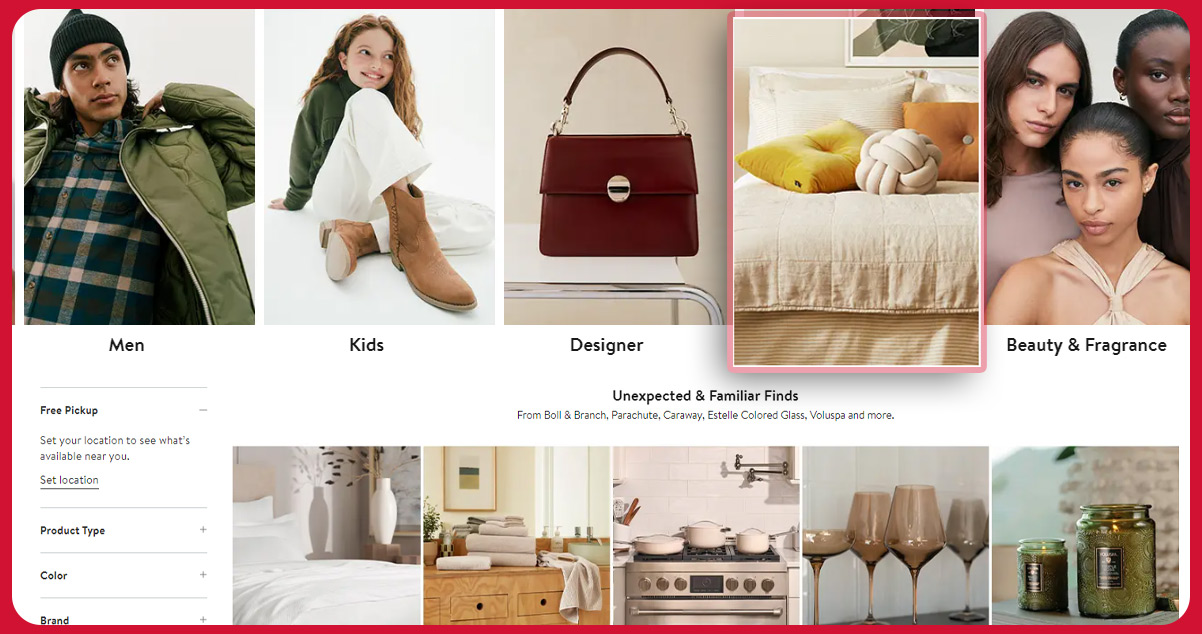
Scraping Nordstrom fashion product data offers numerous advantages for businesses and individuals alike. Firstly, Nordstrom is a prominent player in the fashion industry, known for its vast and diverse product range, making it an invaluable data source for market research and trend analysis. Scrape Nordstrom product data to gain access to rich and up-to-date product information, including details like prices, sizes, colors, and customer reviews. This data can be leveraged for competitive analysis, helping you understand how your offerings compare to Nordstrom and other competitors in the market. Nordstrom's e-commerce platform also operates worldwide, providing a global perspective on fashion trends and consumer preferences. Whether you're a retailer looking to fine-tune your product offerings or a fashion enthusiast seeking the latest trends, Nordstrom data scraping services can provide valuable insights and data to drive informed decisions and stay ahead in the fashion industry.

In this article, our primary focus will be extracting fashion websites' product data and product reviews through a specialized approach known as hidden web data scraping. Our methodology involves collecting HTML pages and subsequently extracting concealed JSON datasets, followed by their parsing with specific tools:
To scrape Nordstrom fashion product data using Python, you can install all these essential packages seamlessly using Python's 'pip' console command.
To initiate the product data scraping process for a single product, we will begin by examining an example product page, such as:
nordstrom.com/s/nike-phoenix-fleece-crewneck-sweatshirt/
Instead of parsing the HTML data through conventional CSS selectors or XPath, our approach leverages Nordstrom's usage of the React JavaScript framework to drive their website. It allows us to extract the dataset directly from the page source using e-commerce scraper, simplifying the data extraction process.

When extracting data through hidden web data scraping, our Nordstrom scraper will follow a structured process as outlined below:
In Python, the code for this scraper will resemble the following:

We've obtained the entire product dataset from Nordstrom with just a few lines of Python code. However, this dataset can be extensive, potentially posing challenges regarding ingestion into our data pipeline for analytics or storage.
Our next step is to utilize JMESPath for data reduction, focusing on the most essential values, such as pricing, images, and variant data.
JMESPath serves as a JSON query language, and since Python dictionaries are equivalent to JSON objects, we can seamlessly incorporate JMESPath into our Nordstrom data parsing process.
We will harness JMESPath's data-reshaping capabilities, allowing us to specify an essential map for streamlining and reducing the dataset. For instance:
This versatile tool empowers us to restructure the scraped datasets effortlessly. Therefore, let's employ JMESPath to reshape the Nordstrom product dataset we've just extracted:

While it may seem intricate, our approach involves mapping the original dataset keys to new keys using JMESPath. It allows our scraper to generate well-organized product datasets that integrate into our data pipelines.
Now that we can efficiently scrape individual Nordstrom products, the next step is identifying the product URLs for scraping. While it's possible to input the URLs of desired products manually, we will focus on scraping product categories or conducting searches to scale up our scraper.
To accomplish this, we will continue utilizing the hidden data scraping method, as each category or search result page contains a concealed dataset with product preview information (such as price, title, image, etc.) and links to product pages.
As an illustration, let's examine one of Nordstrom's search pages:
nordstrom.com/sr?origin=keywordsearch&keyword=indigo
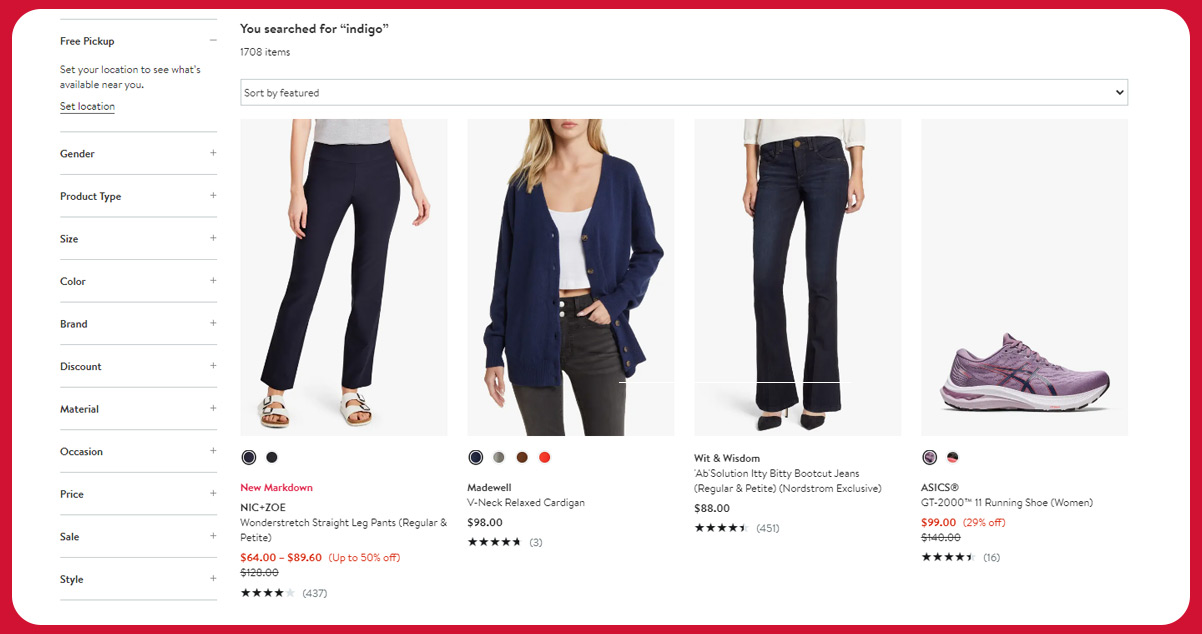
To effectively scrape pagination on search or category pages, we'll employ a method similar to what we used for scraping product pages:
Let's examine how this process occurs in Python:

With Nordstrom price monitoring, you can stay updated with real-time pricing reports from Nordstrom. Leveraging Nordstrom's data extraction capabilities, you can efficiently gather a wide range of information, including product descriptions, names, IDs, SKUs, images, options, features, and more.
We offer tailored solutions for Nordstrom data scraping, employing proprietary software designed for each customer's unique needs. Our expert Nordstrom price monitoring services cater to the specific requirements of your business.
Scraping retail website product prices provides a comprehensive list of various retail stores. Our Nordstrom web scraping services facilitate web browsing through various software programs. Many organizations are leveraging these product store price database scraping services for web research, price comparisons, and other data-related objectives, enhancing their web data collection efforts.
For further details, contact iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile app data scraping needs.