
Embarking on the dynamic e-commerce landscape of Indonesia, data scraping emerges as a strategic imperative for businesses seeking a competitive edge. By harnessing the power of ethical scraping from Indonesian e-commerce websites, enterprises can gain unparalleled insights into market trends, consumer preferences, and competitor strategies. This approach allows businesses to refine pricing strategies, optimize product offerings, and enhance competitiveness in the rapidly evolving digital market. As Indonesia witnesses a surge in online shopping, data scraping becomes instrumental in understanding the intricacies of this vibrant marketplace. Navigating the diverse array of products, prices, and consumer behaviors, ethical scraping from Indonesian e-commerce websites presents businesses with actionable intelligence, fostering informed decision-making and strategic positioning in this burgeoning e-commerce ecosystem.
Founded in 2009, Tokopedia is Indonesia's leading e-commerce platform, facilitating online trade for millions of users. As one of the country's pioneering unicorns, Tokopedia connects buyers and sellers across diverse product categories. Offering a user-friendly platform, Tokopedia has become synonymous with convenience, enabling businesses and individuals to thrive in the digital marketplace. Acclaimed for its vast product range, secure transactions, and innovative services, Tokopedia has played a transformative role in shaping Indonesia's e-commerce landscape. In 2021, it merged with Gojek to form GoTo, solidifying its position as a powerhouse in Southeast Asia's tech and e-commerce ecosystem.
Scrape Tokopedia e-commerce data to gain valuable insights into market trends, product offerings, and competitor strategies, empowering businesses to make informed decisions and optimize their strategies in the dynamic Indonesian digital marketplace.
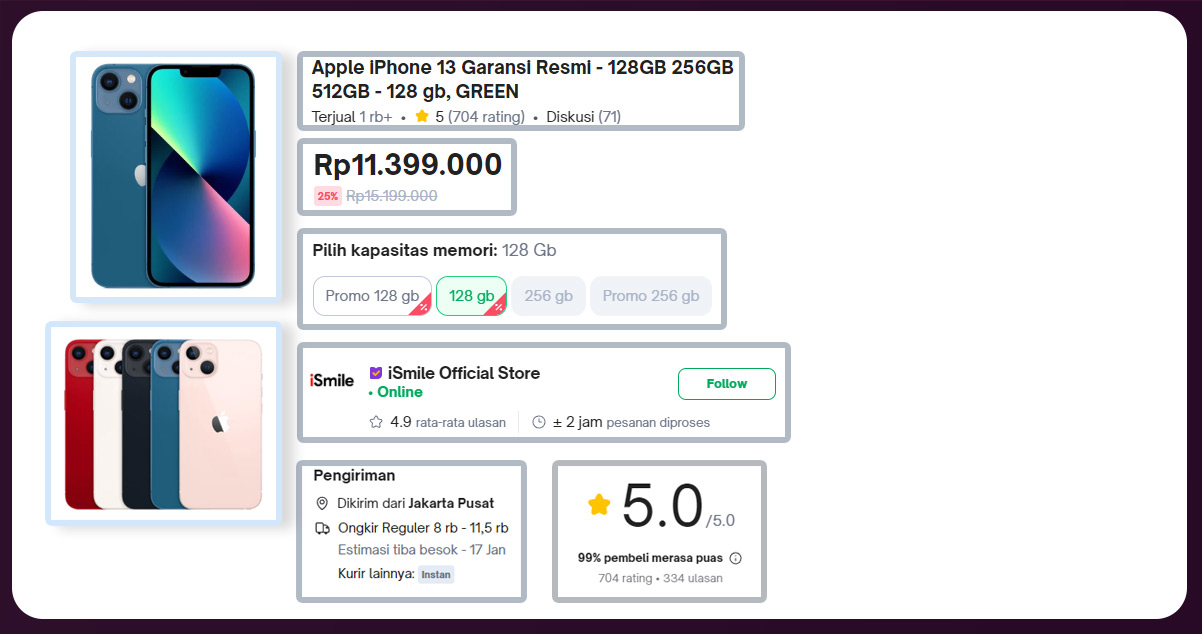

Competitive Insights: Gain a competitive edge by extracting data on competitor product offerings, pricing strategies, and promotional activities, allowing businesses to refine their strategies for differentiation and competitiveness.
Market Trends Analysis: Understand market trends and consumer preferences through scraped data, enabling businesses to adapt product portfolios and marketing approaches to align with the dynamic nature of the Indonesian e-commerce market.
Pricing Strategy Optimization: Optimize pricing strategies by monitoring real-time pricing data, ensuring businesses remain competitive and responsive to market fluctuations, ultimately maximizing revenue potential.
Inventory Management: Facilitate effective inventory management by tracking stock levels, identifying popular products, and minimizing the risk of stockouts, enhancing overall operational efficiency and customer satisfaction.
Customer Behavior Insights: You can collect customer behavior, preferences, and satisfactory information from reviews and ratings. It will enable businesses to tailor their products and services to meet consumer expectations more effectively.
Strategic Decision-Making: Inform strategic decision-making by providing actionable intelligence on product performance, market trends, and competitor activities, allowing businesses to make informed and data-driven choices for growth and market positioning.
Adaptive Marketing Strategies: Craft adaptive marketing strategies based on insights from scraped data, enabling businesses to target specific customer segments, personalize promotions, and enhance overall marketing effectiveness for increased customer engagement.
Businesses can significantly enhance their operations through e-commerce data scraping by harnessing valuable insights from the vast pool of online information. Companies can understand competitors' pricing strategies, product offerings, and market positioning by conducting thorough competitor analysis, allowing for informed decision-making and strategic differentiation. Real-time pricing data extracted through scraping enables businesses to optimize their pricing strategies dynamically, ensuring competitiveness while maximizing profitability. E-commerce data scraping services also facilitate the identification of market trends and emerging consumer preferences, enabling businesses to adapt their product portfolios and marketing strategies to stay relevant. Moreover, by analyzing customer behavior data, such as reviews, ratings, and purchasing patterns, businesses can tailor their products and services to meet consumer expectations, fostering customer loyalty. Efficient inventory management, personalized marketing campaigns, and data-driven decision-making are among the myriad ways e-commerce data scraper empowers businesses to navigate the complexities of the digital marketplace, ultimately enhancing operational efficiency and strategic agility.
The initial step involves determining the specific data for extraction. In this instance, the objective is to gather data related to sunscreen. Subsequently, an examination of the website structure is essential. Construct websites using markup languages like HTML, which defines their layout and content. The data extraction process is executed by scrutinizing the HTML structure of the webpage comprehensively. For this example, we will begin by accessing Tokopedia's webpage via the URL: https://www.tokopedia.com.
Search for the facial sunscreen. It is available as Facetology Sunscreen.
Next, we can inspect the HTML structure by utilizing the "Inspect Element" feature and focusing on the product cards. Upon examination, it becomes apparent that the product card is by a class called css-qa82pd. Within this card, crucial information about the product is nested. By identifying and understanding these HTML elements, we can pinpoint the data we need for scraping, such as product details, pricing, and other relevant information associated with the facial sunscreen category on Tokopedia's website.
We are particularly interested in extracting the product name, price, city, and image URL. Let's examine the HTML elements corresponding to these specific data points to accomplish this. By inspecting the HTML structure, we can identify the relevant tags and classes associated with the product name, price, city information, and image URL. This step is crucial for accurately configuring the web scraping process to target and retrieve the desired data fields from the Tokopedia website.
Once the HTML structure of the page is available, the next step is to script the data retrieval process. Since Tokopedia employs a JavaScript framework for its website, we will utilize Selenium, a browser automation library. Begin by installing Selenium, following the instructions in the link, and setting up a Python virtual environment for the project. For browser automation, we'll use Firefox.
Create a file named scraper.py to house the Scraper class. Within this class, establish a property named driver responsible for interacting with the browser via Selenium Webdriver. The Webdriver class facilitates communication with the browser, allowing commands to open specific pages. To instantiate a Webdriver object connected to the Firefox browser, invoke the static function Firefox() from the Webdriver class. It establishes a session for seamless interaction with the browser during the scraping process.
Subsequently, let's create a get_data() function within the Scraper class to initiate the data retrieval process from the website. To do this, we require a URL from the Tokopedia website. This function will encapsulate the logic for interacting with the webpage, extracting relevant data based on the HTML structure identified earlier, and facilitating the scraping process using Selenium's Webdriver capabilities. Ensure the URL is accurate and corresponds to the Tokopedia page containing the desired shoe product data.
Initiate the URL retrieval process by instructing the driver to navigate to the specified webpage using the driver.get("URL") function. This Selenium command directs the browser, controlled by the Webdriver, to open the designated URL, facilitating the subsequent data extraction process from the Tokopedia website.
Create a page counter variable and a list to store the extracted data. This counter will be instrumental in navigating through the pages displaying the products on the Tokopedia website, while the list will serve as a repository for the scraped data. This systematic approach allows for organized data storage and subsequent analysis.
To retrieve data from each of the first 09 pages, employ a loop instructing the driver to scroll down the webpage until the end. Given the observation that the page has approximately 5500 pixels, implement a scrolling mechanism in increments of 400 pixels for each iteration. To avoid putting excessive load on the server simultaneously, introduce a brief pause of 0.1 seconds between iterations. This approach ensures a systematic and considerate scraping process, allowing the server to handle the requests effectively.
Following the scrolling iteration, retrieve the card elements from the page. Iterate over each card element, extract the relevant data such as the name, price, city, and image information, and append this to the data variable. This systematic process ensures that data from each card on the page is available, facilitating the comprehensive scraping of shoe product information from the Tokopedia website.
Upon obtaining all the data from a page, advance to the next page by instructing the driver to click the following page button. Upon inspecting the HTML of the page, identify the class associated with the page button, which in this case is css-1ix4b60-unf-pagination-item. Utilize the counter variable to specify which button to click, allowing sequential navigation through the pages during the scraping process. It ensures a systematic and organized approach to collecting data from multiple pages on the Tokopedia website.
Conclude the get_data() function by returning the collected data as the function's return value. This final step ensures that the scraped data is accessible and can be further processed or analyzed.
For the complete code, you can refer to the following:
Certainly! Here's the code for your "main.py" file to check the functionality of the Scraper class:
Upon executing the script, a Firefox browser window will automatically open, and the browser will navigate through the pages as directed by the Selenium driver in the code. The results of the scraping process will be displayed on the terminal, providing a comprehensive overview of the data extracted from the Tokopedia website. This seamless integration of browser automation and data extraction demonstrates the effectiveness of the implemented scraping functionality in fetching valuable information. Adjustments to the code may be necessary based on the specific structure and elements of the Tokopedia website.
Feel free to get in touch with iWeb Data Scraping for comprehensive information! Whether you seek web scraping service or mobile app data scraping, our team can assist you. Contact us today to explore your requirements and discover how our data scraping solutions can provide you with efficiency and reliability tailored to your unique needs.