
Netflix, Inc. is an American production company & media and technology service provider headquartered in Los Gatos, California. The company’s primary business is the subscription-based streaming services that offer online streaming of film series and television, along with in-house production.
Marc Randolph and Reed Hastings in Scotts Valley, California, was the founder of this company in the year 1997.
The Netflix content differs by region and can even change over time. You can watch several award-winning Netflix originals, movies, TV shows, documentaries, and more.
Internet videos are continuously gaining tremendous popularity with the rising demand of the live video streaming market. Over 81% of online users prefer to view live video streaming. More than 62% of the public in the age group 18-34 watch live video streaming regularly Several people across the globe utilize Netflix, a top-rated entertainment service. This OTT platform allows watching unlimited movies and shows. Easily collect any episode’s names, ratings, cast, plans pricing, etc., by web scraping Netflix data. Netflix users can scrape information related to countless movies. But it is impossible to achieve manually. Hence, it would help to have a Netflix web scraper for a seamless scraping experience. Using this data., you can analyze what users are watching and what’s trending the most.
Scraping Netflix data has several challenges, as it sometimes temporarily bloc too many connections. At iWeb Data Scraping, we can optimize the scraper to improve accuracy.
Web scraping Netflix data uses Python, as this Programming language comprises a vast collection of libraries, making it more flexible than others.
First, create a folder and install all the required libraries during this procedure.
Here, we will install two libraries:
>>mkdir Netflix
>>pip install requests
>>pip install beautifulsoup4
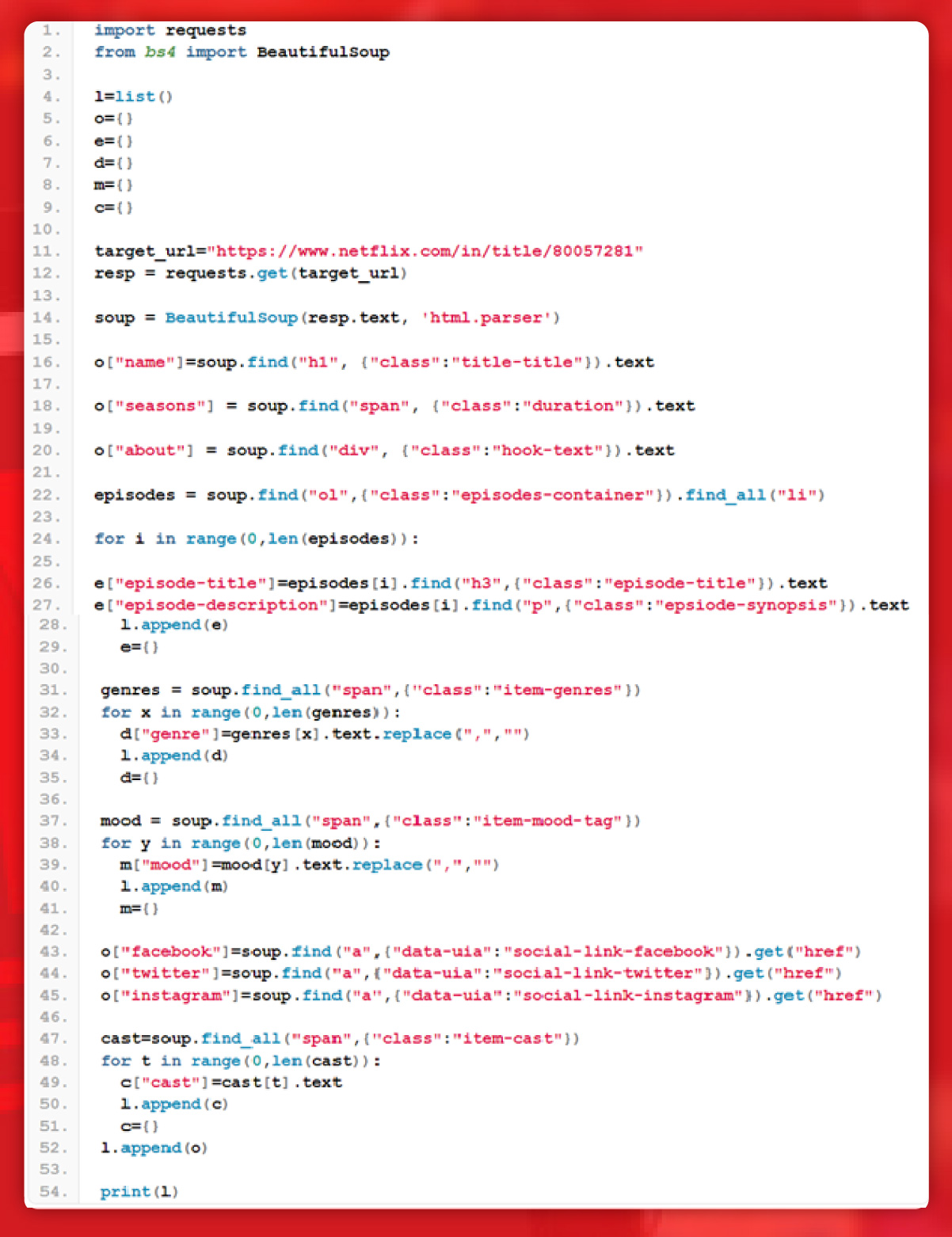
Within this folder, create a python file to write our code. We will scrape this Netflix page. Our data of interest will be:
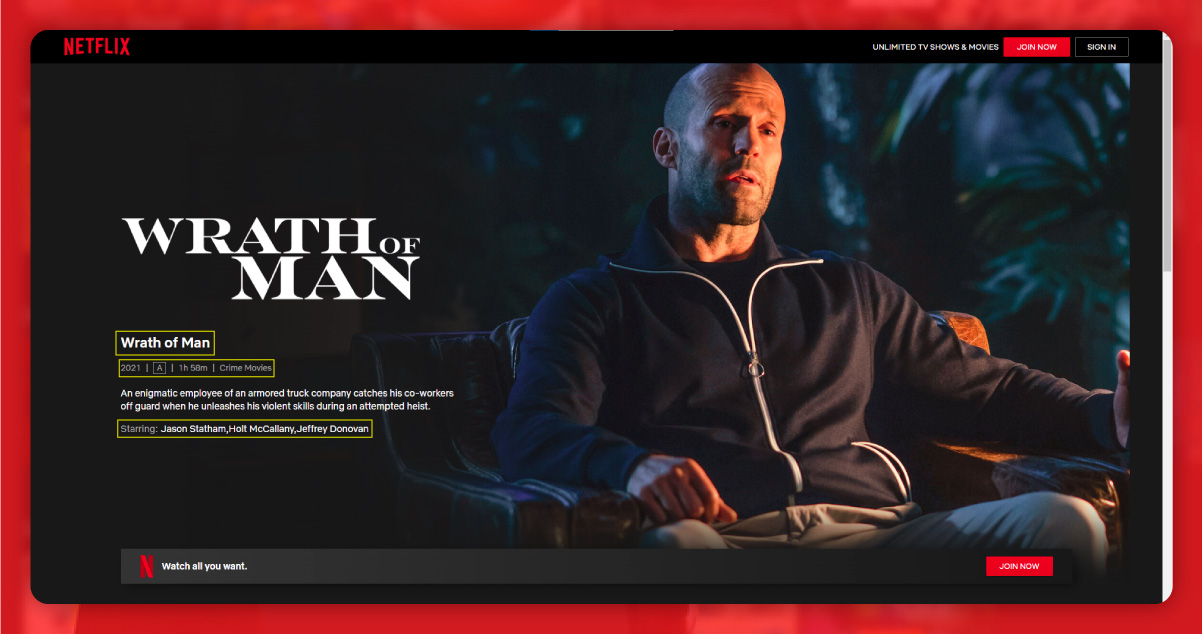
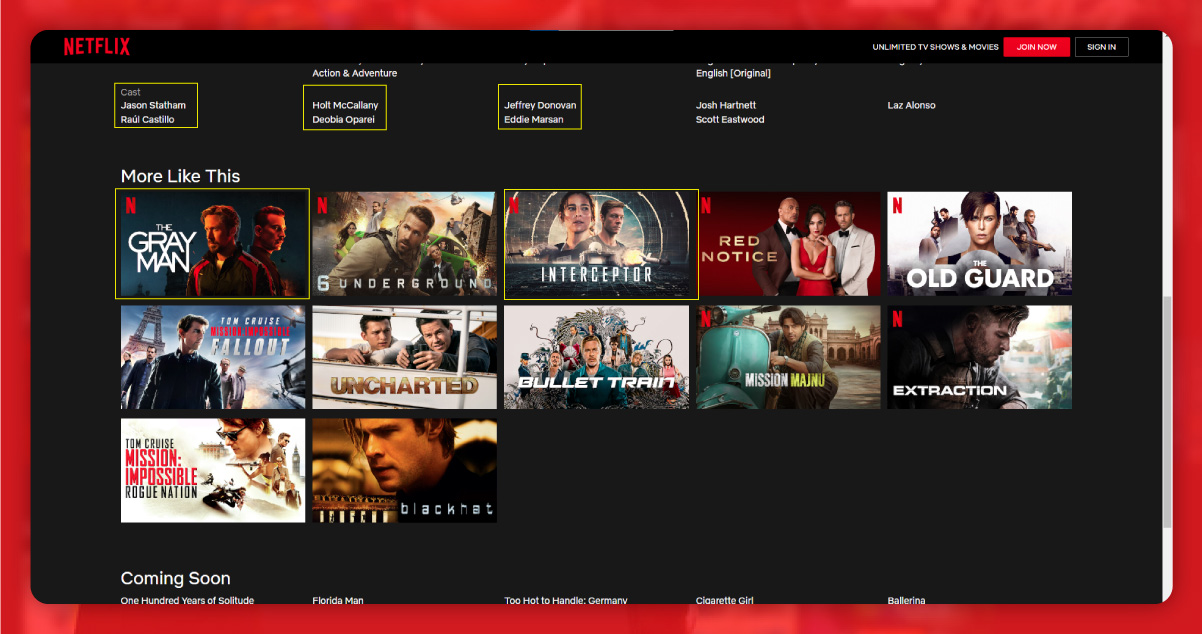
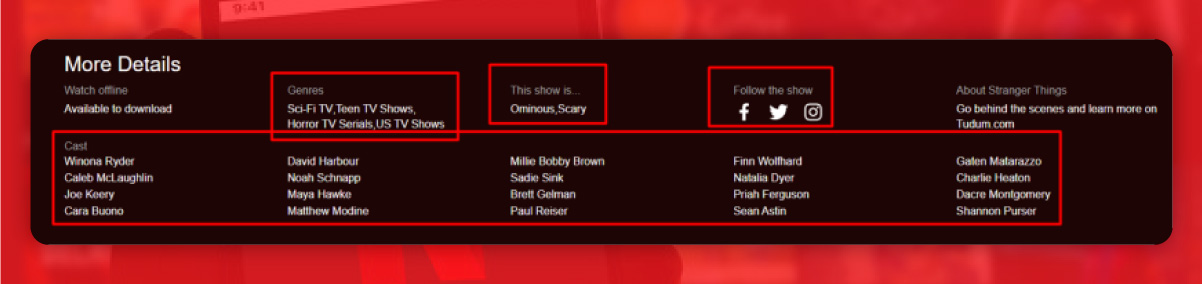
First, find the location of these elements.
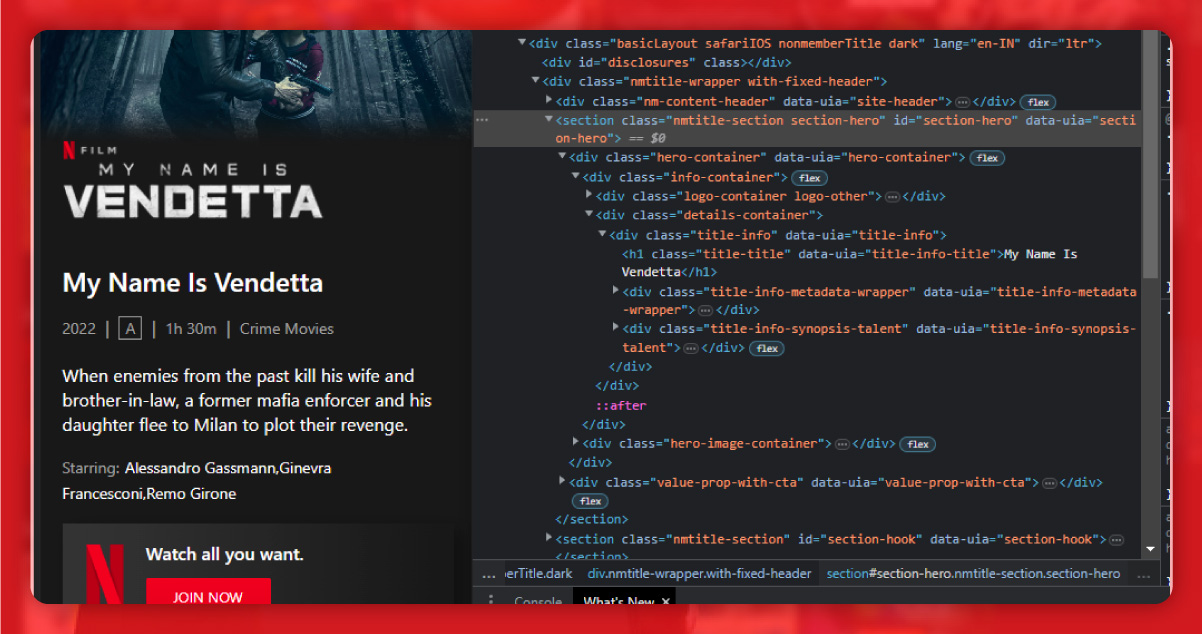
The title is available within the h1 tag of the class title.
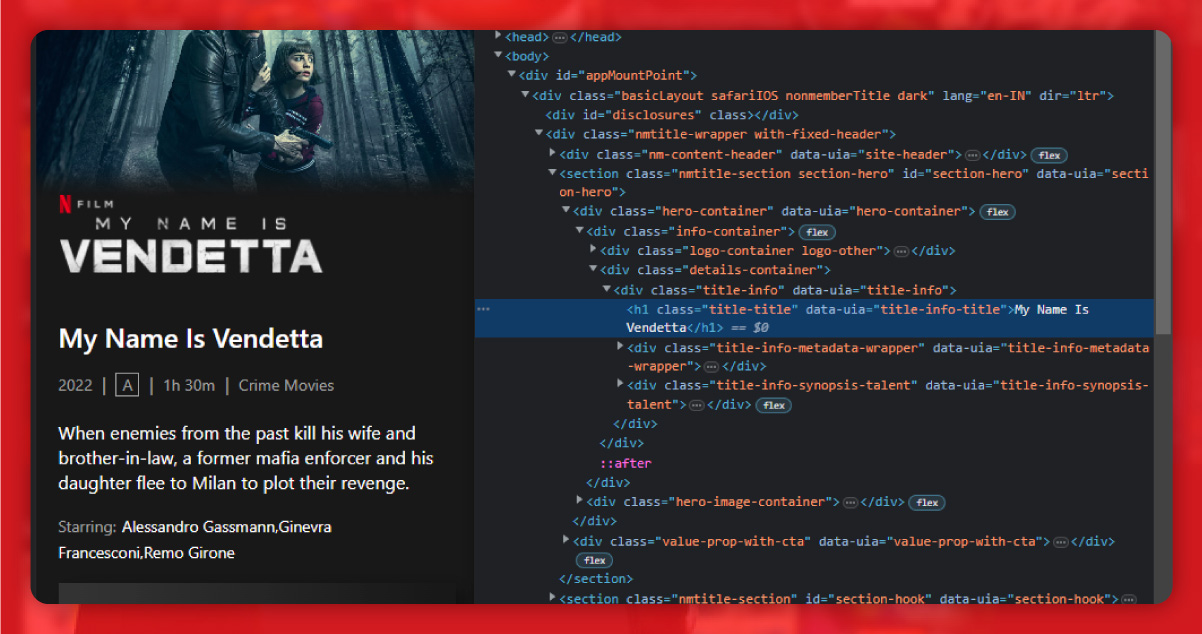
The number of seasons is within the span tag of the duration class.
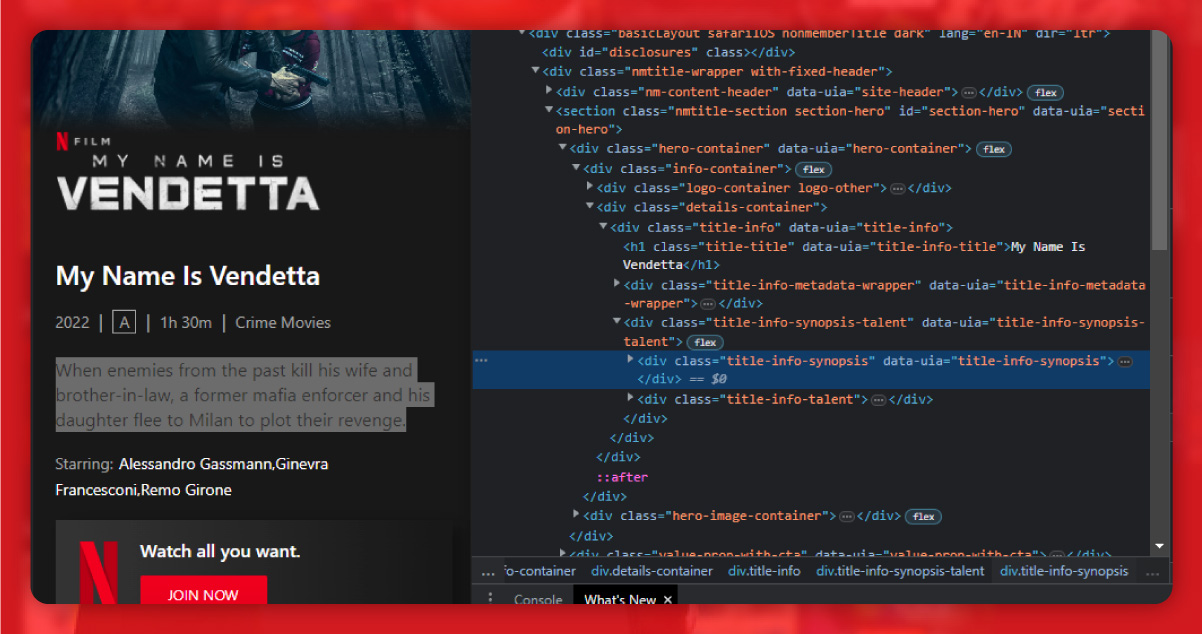
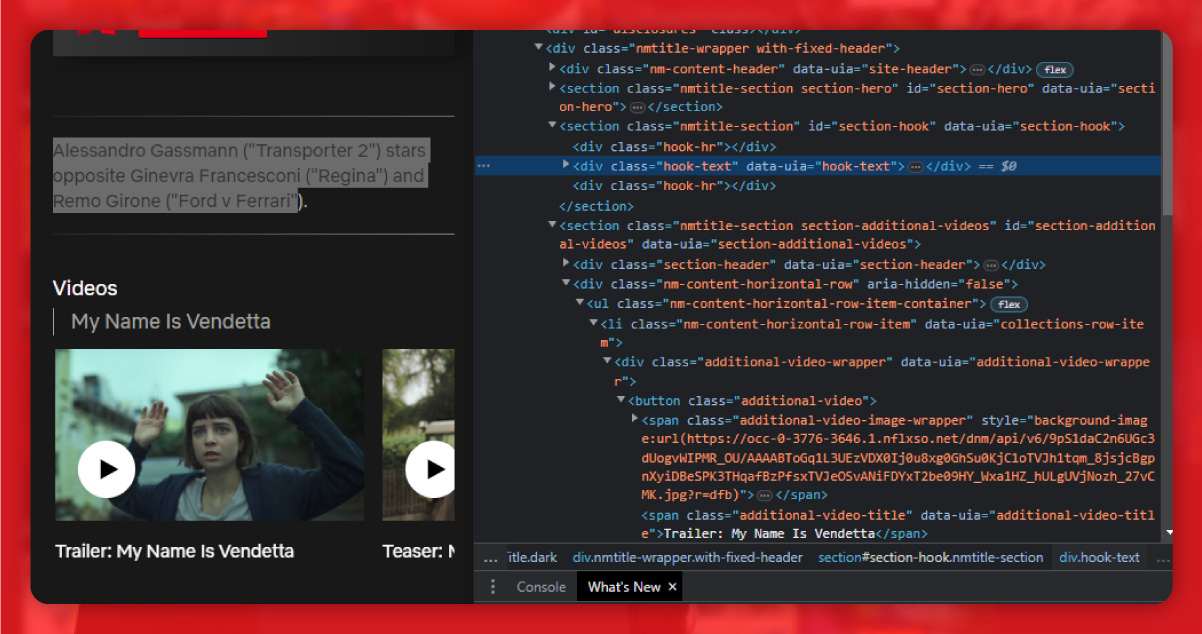
The about section is within the div tag of the class hook text.
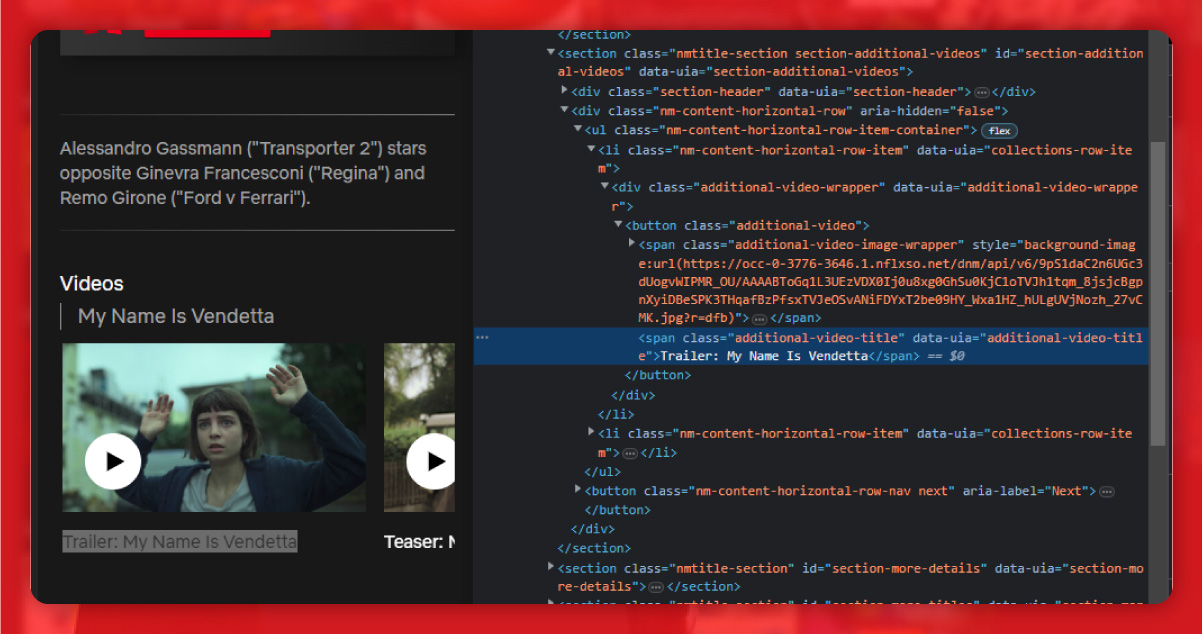
The episode title is available within the h3 tag with the class episode title.
The episode title is within the p tag with the class episode-synopsis
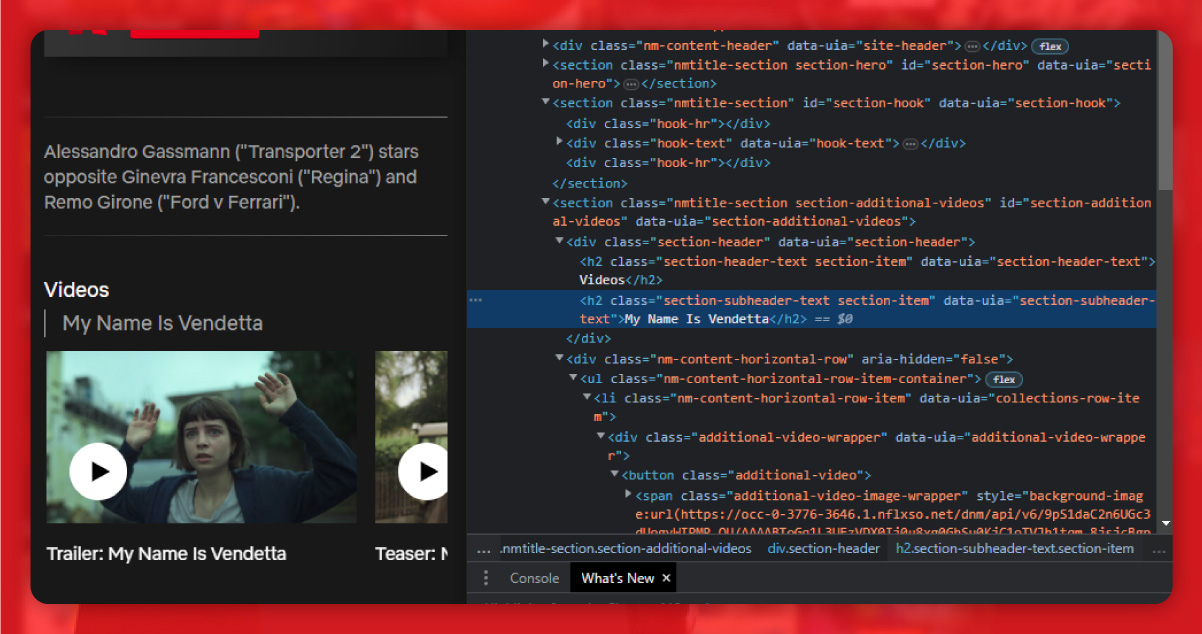
Genre is within span tag with the class item-genres.
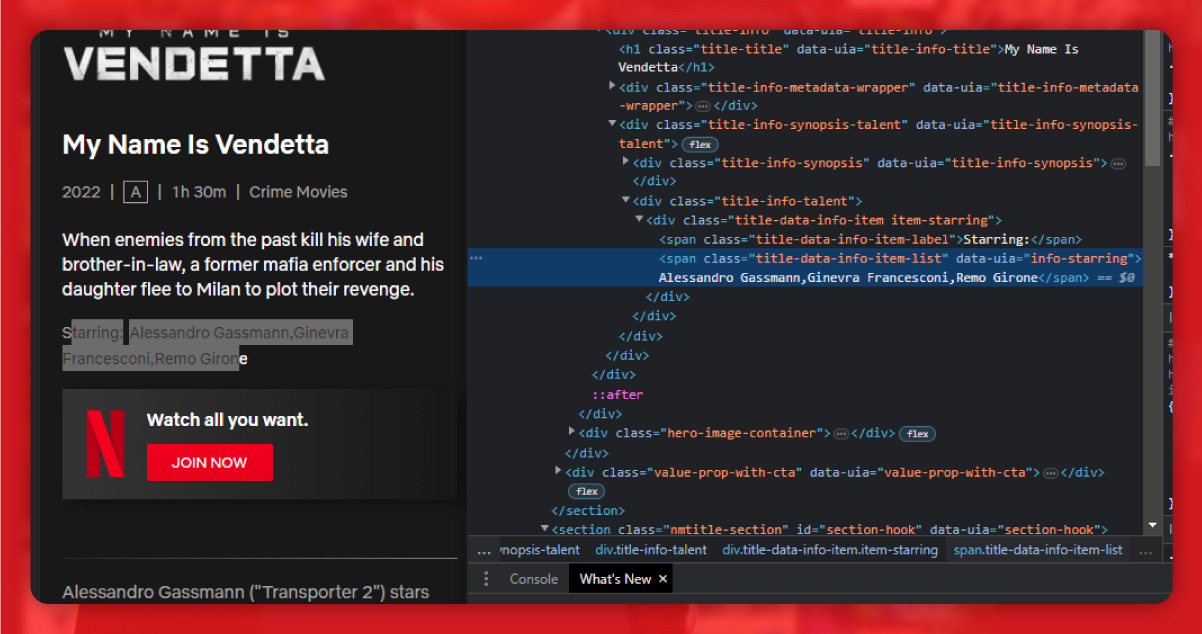
The category of the show is within the span tag with the class item-mood-tag

The social media links lie within a tag with the class name social-link
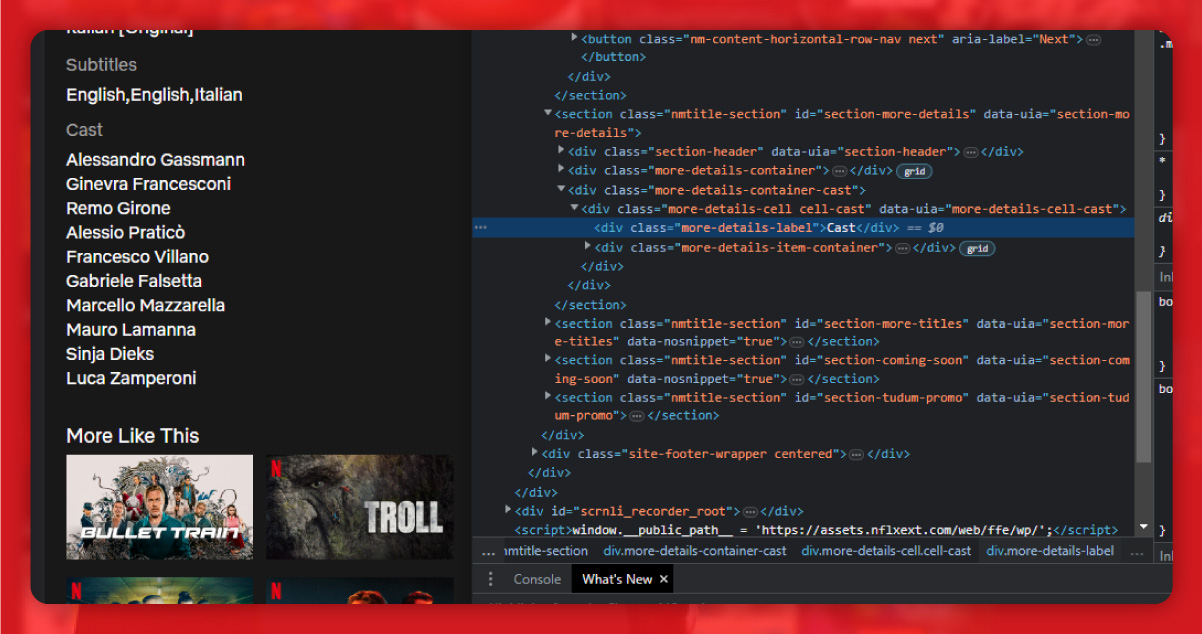
The cast lies within the span tag with the class item model.
Now, make a standard GET request to the target webpage.

Now from the above data, extract information using BeautifulSoup or BS4.

Here, we will extract all data properties using the exact HTML location.

Now, extract the episode details..

So, within the ol tag lies the complete data. So, first, we will find all ol tags and then all li tags. Then, extract the title and description using the loop.
Now, extract the genre.

Now, extract all data using a similar technique.
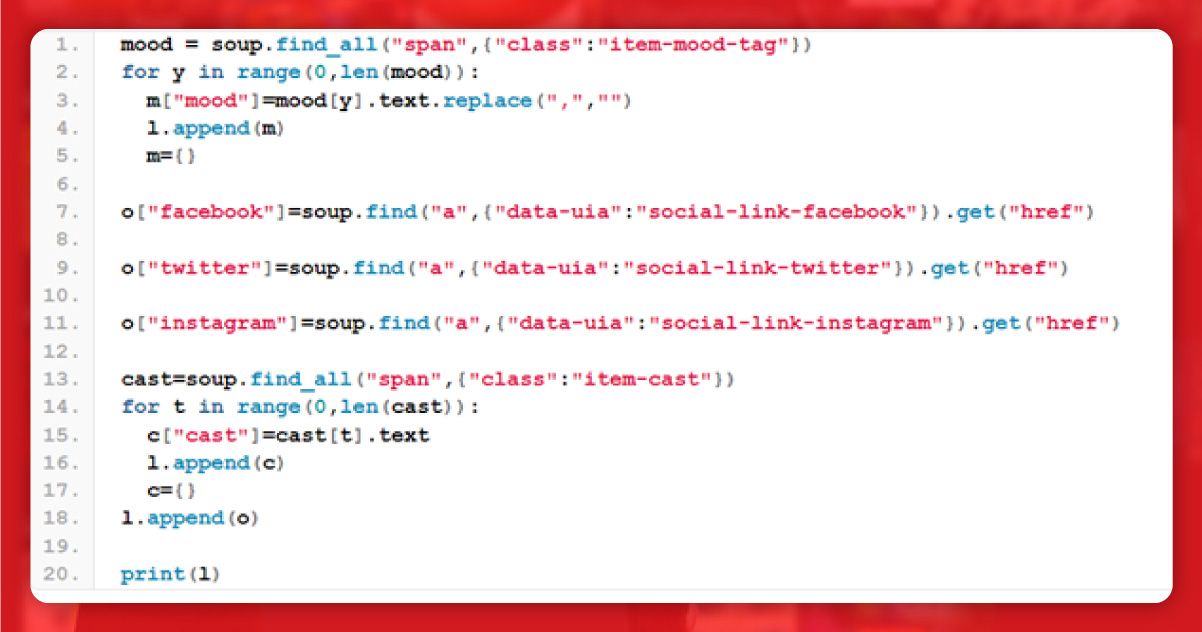
Now, get the complete code.

Conclusion: The above content explains a simple and easy way to scrape Netflix data. By changing the show title ID, you can easily scrape almost all the shows from Netflix. You can also use XPath to create an HTML tree for data extraction.
For more information, contact iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile app data scraping service requirements.