Getting enough knowledge in a specific business domain is a main mantra for any business to stay aligned with its competitors. News is the best means to learn what’s happening worldwide. Especially for data engineers, news articles are a great way to collect enough data. More data means more insights. But, collecting news, reading, and gaining enough news knowledge is challenging and takes a lot of time. It is impossible to collect data manually. So, fast and quick knowledge in the news industry requires scraping news sites. It plays a vital role in getting essential updates about business in a short time.
This article explains everything you need about news scraping and how to scrape the content quickly and effectively..
It is a term used for scraping news content from news sites available on public online media. It means extracting press releases and updates automatically from news websites. As these sites comprise lots of meaningful public data, reviews on newly launched products, and several keys and announcements for business, hence, are effective for any business success.
News aggregation helps to collect important content to attract and grow your target audience and turn your platform into a go-to news outlet. Rather than competing with other brands and sites, the news aggregator will provide them with additional exposure.
There are several benefits of scraping news. A few of them are listed below:
The news scraping services aggregate the most highly relevant news content from the website. It lets users avoid the hassles of searching articles, relevant reports, interviews, and more and making them all in one place.
Before you scrape news content from popular news sites, keep in mind the following considerations:
At iWeb Data Scraping, we provide news website data scraping services from several sites, including Yahoo News, MSN, etc
In this article, we will create the best news scraper to scrape the latest news articles from various newspapers and store them as text. Hence, we will go through the following two steps to perform an in-depth analysis.
When we go to any specific URL using a web browser, the particular webpage is a combination of three technologies:
Python consists of several packages that help in scraping information from a webpage. Here, we will use BeautifulSoup for web scraping.
Install the library packages using the following command.
! pip install beautifulsoup4We will also use the requests module to help provide BeautifulSoup with the page’s HTML code. Please install it using the following command.
! pip install requestsSo, to provide BeautifulSoup with HTML code, we will require a requests module.
Next, install urllib using the following command.
! pip install urlliburllib is Python’s URL handling module. It helps in fetching URLs.
Now, we will import all the necessary libraries
Import BeautifulSoup on your IDE using the following command.
from bs4 import BeautifulSoupThis library helps get the HTML structure of the desired page and provides functions to access specific elements and extract relevant information.
Now, import urllib using the following command.
import urllib.request, sys, timeTo import requests, type the following:
import requestThis module sends the HTTP requests to a web server using Python.
Import pandas using the following.
import pandas as pdWe will use this library to make DataFrame.
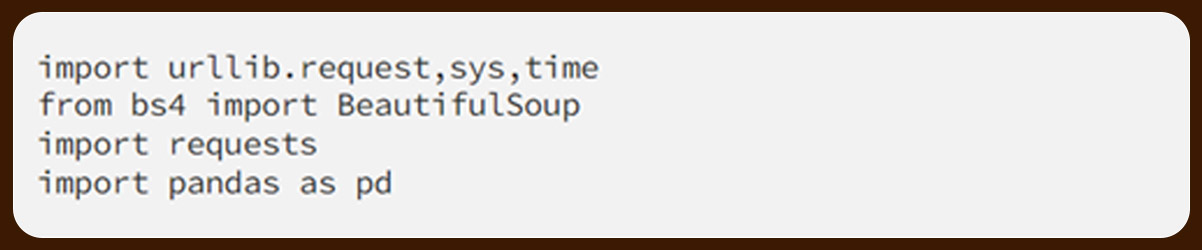
Now, make a simple get request by just fetching a page.
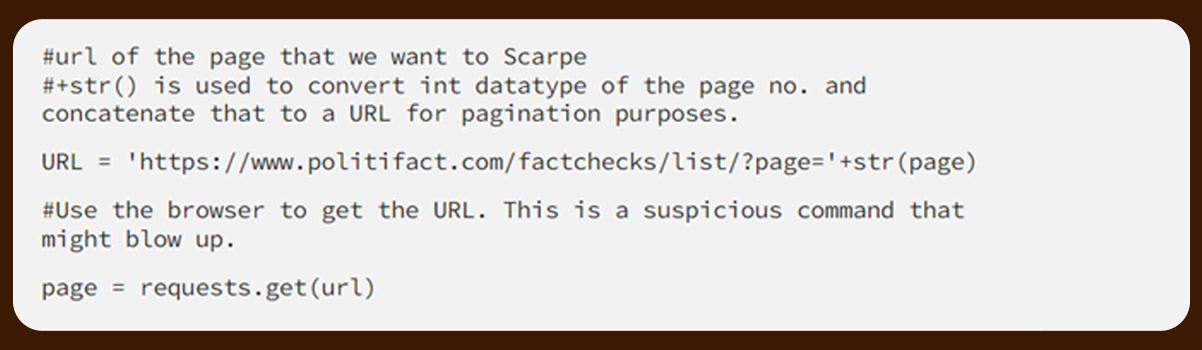
We will consider the requests.get(url) in a try-except block.
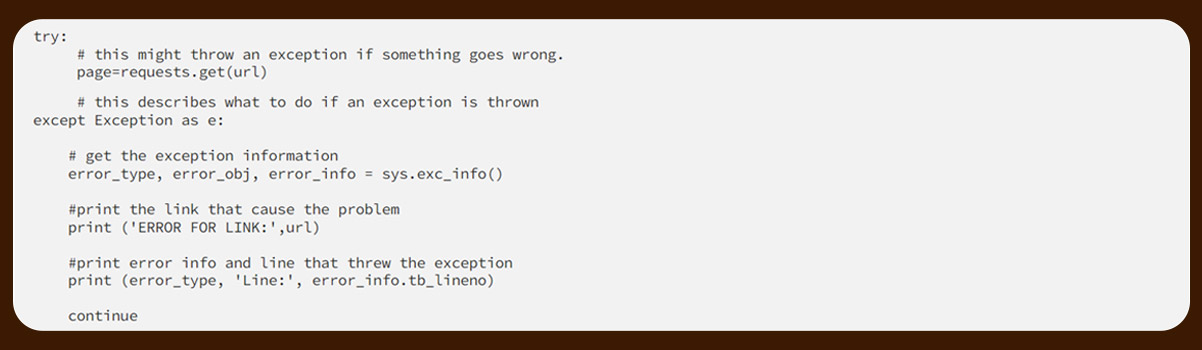
We will also use the ‘for’ loop for pagination.
See the response code that the server sent back.
page.status_codeOutput
Status of Response object
200The HTTP 200 OK status response code shows that the requests have succeeded.
Now, access the complete response as text.
page.textOutput
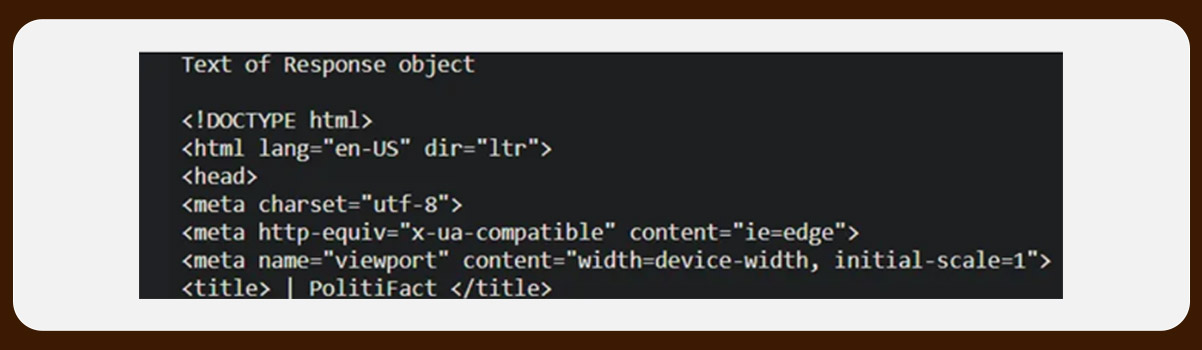
It will return the HTML content of a response object in Unicode.
Look for the specific substring for the test within the response.
if "Politifact" in page.text:
print("Yes, Scarpe it")Check for the response’s content type.
print (page.headers.get("content-type", "unknown"))Output
response's Content Type
text/html; charset=utf-8We will call the sleep(2) function with a value of 2 seconds.
time.sleep(2)It’s time to parse HTML content to extract the desired value.
(a) Using Regular Expression
import re # put this at the top of the file
print (re.findall(r'\$[0–9,.]+', page.text))Output
['$294', '$9', '$5.8'](b) Using BeautifulSoup
soup = BeautifulSoup (page.text, "html.parser")The below command will look for all tags - < li > with specific attribute ‘o-listicle__item.’
links-soup.find_all('li',attrs={'class':'o-listicle__item'})To understand the above code, inspect the webpage. It will appear like this.
As we need the news section of a particular page, we will go to that article section by choosing the inspect element option. It will highlight the particular web page section and its HTML source.
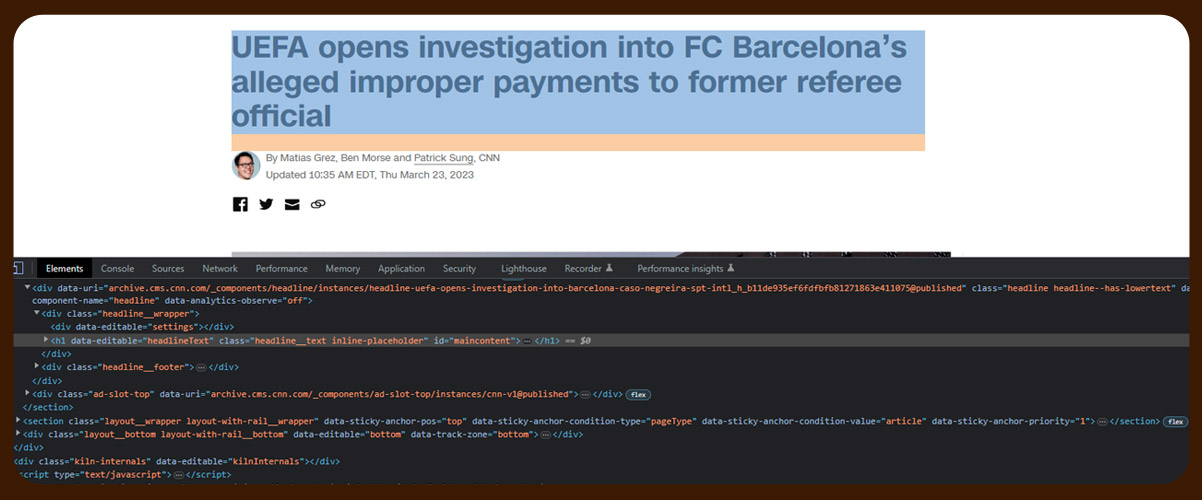
We will continue with our code.
print(len(links))This command will extract the number of news articles on a given page.
Look for all anchor tags on the page.
links = soup.find_all("a")It will find a division tag under < li >. Here ‘j’ is an iterable variable.
Statement = j.find("div",attrs={'class':'m-statement__quote'})Text.strip() function will return text within this tag and strip any extra spaces.
Statement j.find("div", attrs={'class':'m-
statement__quote'}).text.strip()We have scraped our first attribute. In the same division, we will look for the anchor tag and return with the value of the hypertext link.
Link=j.find("div", attrs={'class':'m-statement__quote'}).find('a') ['href'].strip()To get the Data attribute, we will inspect the web page first.
Date j.find('div', attrs={'class':'m-
statement__body'}).find('footer').text[-14:-1].strip()Source j.find('div', attrs={'class':'m-
statement__author'}).find('a').get('title').strip()Next, we are using ‘alt’ as an attribute to get()
Let’s combine all concepts and fetch details for five different attributes of my Dataset.
frame.append([Statement, Link, Date, Source, Label])upper frame.extend(frame)For visualizing, use pandas DataFrame.

Write a CSV file and save it to your machine


For more information, get in touch with iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile app data scraping requirements.