
Public news data can be highly beneficial to stay ahead of the competition. For companies whose sole business isn’t collecting or analyzing news data, it becomes cumbersome to read and analyze articles from numerous popular news sites worldwide. This action will, however, consume enough time and effort. In such cases, news scraping plays a pivotal role.
This article will give a brief insight into everything you need to know about scraping news content from popular sites. It includes its benefits and how to use Python for scraping news. But, before everything, let’s first understand what news scraping is.
News scraping is a subset of web scraping that aims to target public online media sites. It automatically extracts news updates and releases from articles and popular news websites. It also extracts general news data from the news result tab on SERPs or steadfast news aggregation platforms.
Web scraping, also known as web data extraction, is automated data retrieval from any website.
Look at the news data from a business point of view. You will understand that news websites comprise uncountable important public data ranging from newly released product reviews to the company’s financial results coverage and several other important announcements. These popular news sites also cover multiple topics and industries like fashion, finance, technology, health, science, politics, and many more.
Some of the significant pros of news scraping include the following:
Risk identification and mitigation: When using digital technology with real-time data from multiple sources can help ease any risk-causing scenarios and deliver the most effective solution to a problem. Scraping news from real-time public data can identify and mitigate risks. Scraped news data can enhance the company’s ability to predict, anticipate, and observe threats more precisely, quickly, and accurately.
Updated, verified, and reliable information: Almost all popular news sites strive to maintain their credibility with their coverage of evolving news. Their fact-checking departments and libraries constantly work to verify every aspect of their updates. Hence, scraping news content enable companies to avail accurate, updated, and reliable data.
Enhance Operations: Companies can be affected by several external factors. Hence, scraping public news websites is essential to remain updated on constantly emerging trends. This acts as a medium to improve operations to influence emerging trends and reject unfavorable ones.
Boosts Compliance: Several news websites cover a broad aspect of topics related to regulations that are passed already or are still waiting for enactment. In some cases, several news articles also give a detailed overview of laws implications and expert interviews. However, scraping public news and collecting the data will help companies prepare for their impact, enhancing compliance.
Scraped news can offer better insights on real-time updates related to multiple topics and issues. This data is used in the following ways:
Reputation monitoring : As per the study revealed by Weber Shandwick in 2020, companies that have strong reputation has high customer loyalty, enhanced partner & supplier relationship, high employee retention, better stock market, competitive advantage, and lots more. However, nearly 77% of the company’s brand value is dependent upon the company’s reputation.
Media coverage can be positive or negative. It all depends upon the customer’s opinion. Any bad publicity can ruin the brand’s image and affect its reputation. However, nearly 87% of companies believe that customer perception is significant. And hence, review monitoring and online reputation management are the major processes for any company.
Scraping news will enable companies to track and analyze every aspect of published news and its reputation.
Gather competitive intelligence: The business world is nothing without competition. And this generates the need for competitive intelligence. Several news articles publish topics like rebranding initiatives, product launches, financial results, etc. Scraping news from these websites will give specific business-oriented data and a brief insight into competitors’ moves.
Determine industry trends: Several factors can impact business operations. Businesses can implement the same strategies to stay ahead of industry trends. However, companies must develop something that can help track and monitor trends and rising issues. Public news articles are the best option. The information here relies on the progress of a particular industry. Scraping the news content from these websites will help discover emerging industry trends and increase competitiveness. Web scraping articles possess data about competitors.
Obtain fresh ideas: Several news websites contain articles with valuable input from industry experts. Such articles can help businesses to boost their ideation process. For companies looking for growth, such data can be the best source to gain new opportunities.
Enhancing content strategy: Certain news websites don’t include only media outlets but have PR and newswires sites too. Scraping such news sites will show how to improve communication and news strategy.
Regarding news scraping, Python is the preferred means to get started. It involves two significant steps – Webpage downloading and HTML parsing.
Requests are the most important library that downloads webpages. This installs using the pip command on Windows. You should run the following command.
pip3 install requests
Generate a new Python file and enter the following code.
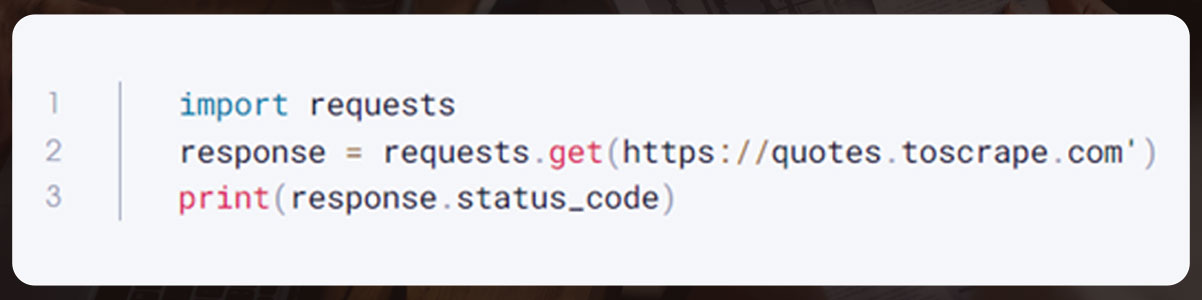
This will print the HTTP status code. Access the HTML of the page using the text attribute of the response object.
print(response.text) # Prints the entire HTML of the webpage.
The returned HTM L is a string parsed into a Python object. Now, install BeautifulSoup using the pip command.
pip3 install lxml beautifulsoup4
Import it, and you will obtain the following.
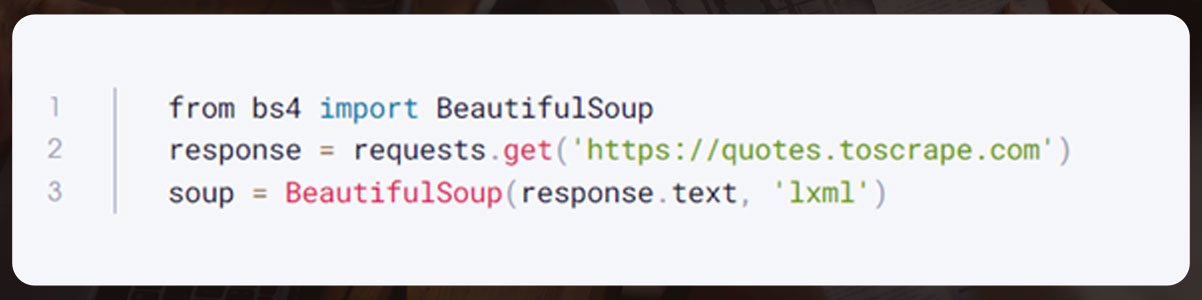
To locate the HTML element, use find()
title=soup.find('title')
The text can be extracted using the get_text() method.
print(title.get_text()) # Prints page title.
If needed, use other attributes like id, class, etc.
soup.find('small', itemprop="author")
To use a class attribute, use class _ because it is a reserved keyword.
headlines=soup.find_all(itemprop="text")
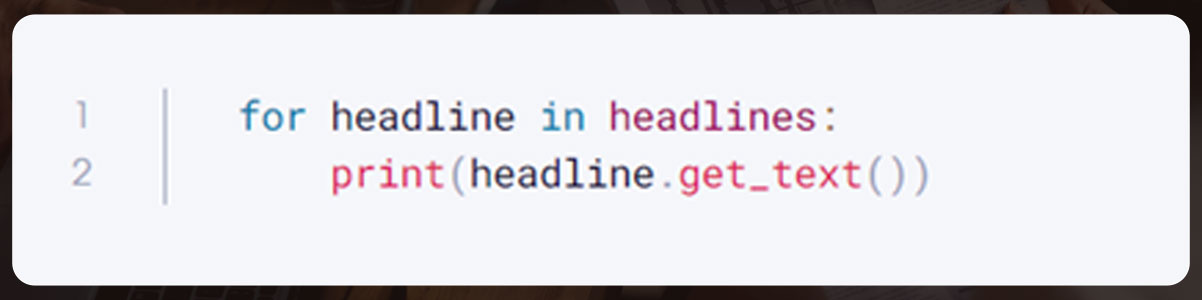
However, to find more than one element, use find_all()
headlines=soup.find_all(itemprop="text")
The object headline is a list of a tag. To extract it, use for loop.
Thus, web scraping from news sites makes extracting real-time and accurate data easy and fast. And when used ethically and in the right way, a company can enjoy tremendous benefits.
CTA: For more information, contact iWeb Data Scraping now! You can also reach us for all your web scraping service and mobile app data scrapingrequirements.