
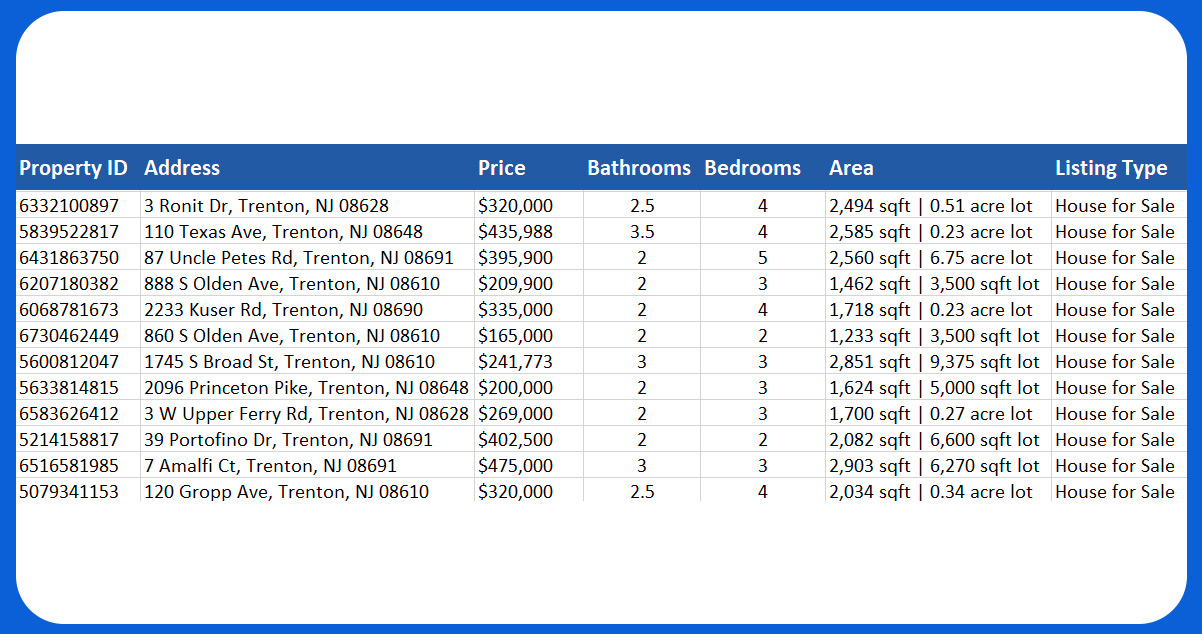
Real estate data scraping is a game-changer for property professionals, investors, and analysts. It allows for the automated extraction of vast property-related information, including listings, prices, location data, and historical trends. With this wealth of data, you can make informed decisions on property investments, market trends, and pricing strategies. Whether you're a real estate agent looking to find the best deals or an investor seeking opportunities, real estate data scraping is an invaluable tool to stay ahead in this dynamic industry.
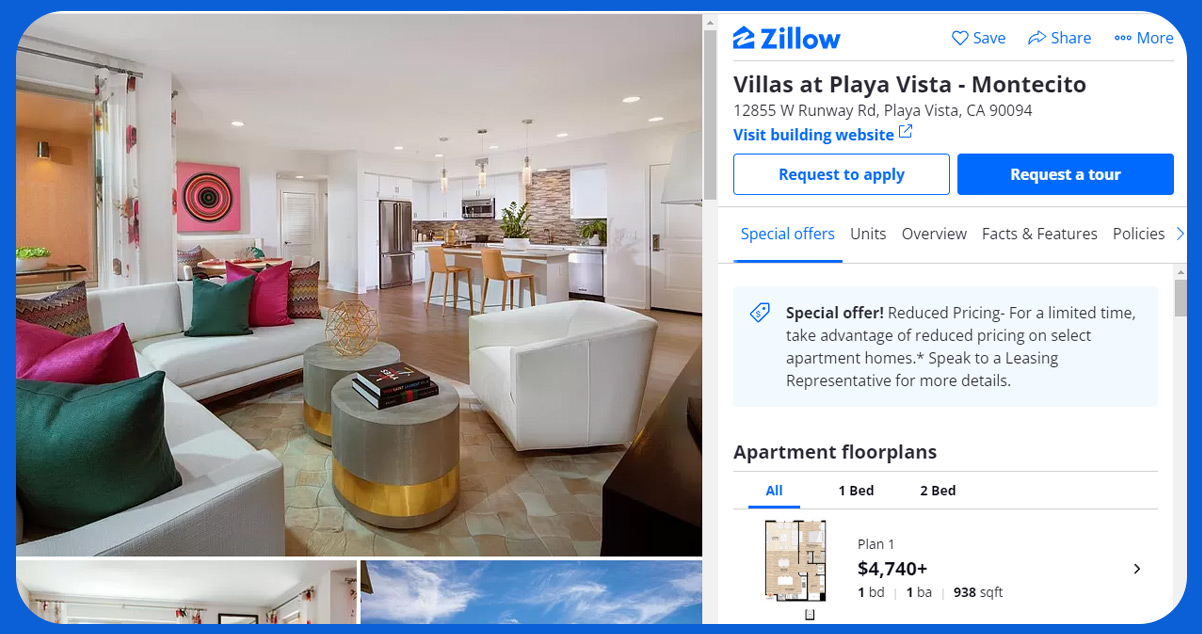
Zillow is a renowned online real estate platform that provides various accurate estate-related services. It offers tools for searching and listing properties, estimating property values, and connecting buyers and sellers. Zillow is known for its extensive database of property listings, including homes for sale and rent. The platform also offers valuable data and insights, making it a go-to resource for those looking to buy, sell, or invest in real estate. Whether you're a homeowner, a real estate professional, or an investor, Zillow plays a significant role in simplifying the real estate journey. Scrape Zillow real estate data to access comprehensive property listings, market insights, and pricing trends, empowering informed decisions for homebuyers, sellers, and investors alike.
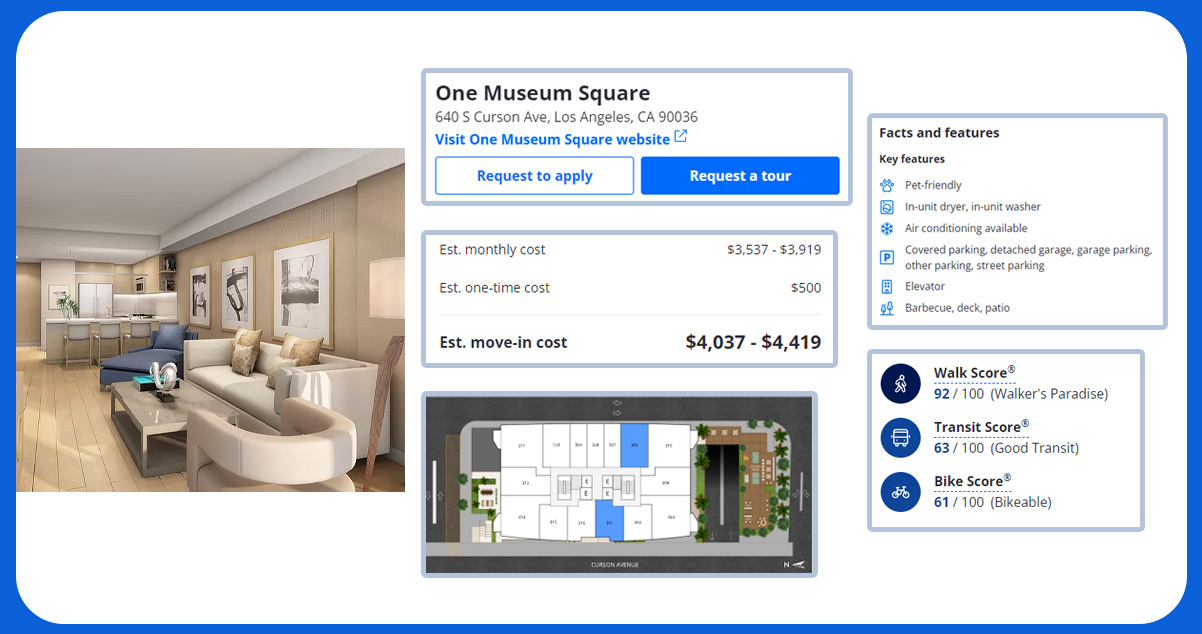

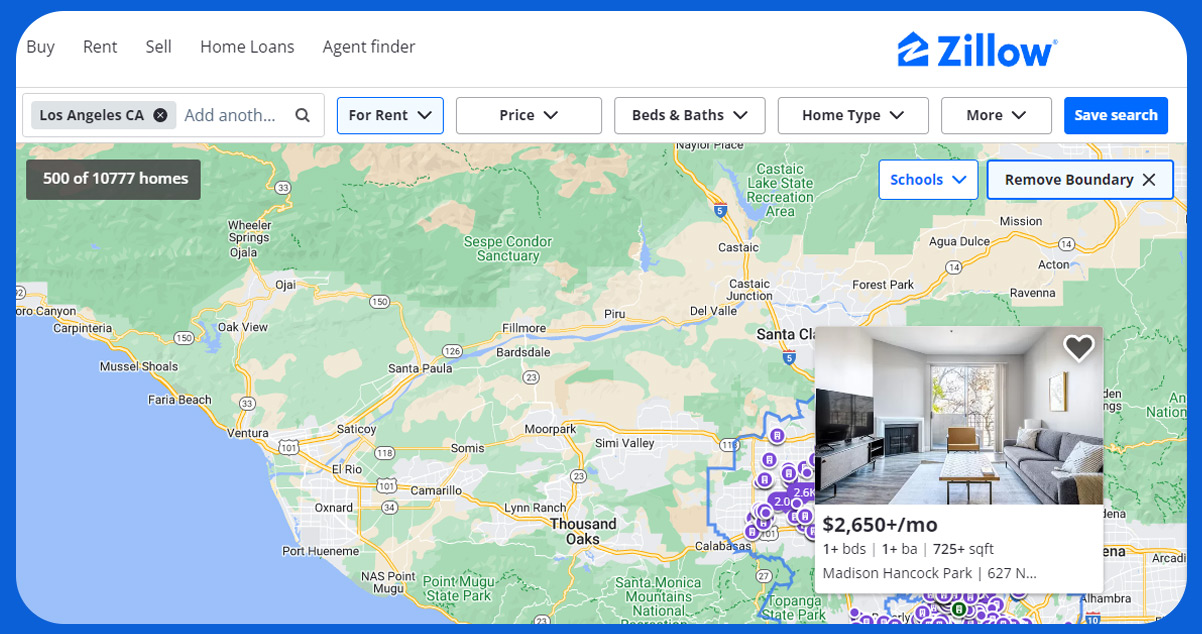
Achieving success in real estate website scraping comes with its share of challenges. Here are common obstacles to be aware of:
Sophisticated Dynamic Layouts: Real estate websites often feature complex and dynamic web layouts, making it challenging for web scrapers to adapt and extract accurate data. Manual fixes may be necessary to address inaccuracies or omissions in the scraped data.
Advanced Anti-Scraping Measures: Property websites use technologies like JavaScript, AJAX, and CAPTCHA to deter scraping. These measures can hinder data collection and lead to IP blocks, necessitating specific bypassing techniques.
Questionable Data Quality: The dynamic nature of property prices introduces the risk of obtaining outdated information that aligns differently from the current real estate market conditions.
Copyrighted Data: Web scraping's legality, especially for real estate websites, remains a debated topic. The general guideline is to scrape publicly available data while respecting copyright rules. Legal advice can ensure compliance with relevant regulations and avoid potential breaches.
While various programming languages can handle HTML files, Python is a widely favored choice for scraper development. Noteworthy points include:
Python offers many idiomatic tools for parsing, searching, navigating, and modifying web data.
Additionally, the Python ecosystem encompasses numerous advanced web scraping libraries for diverse needs and preferences.
To perform Python-based scraping on Zillow, ensure you have Python 3 and Pip installed. Additionally, you'll need the following packages for downloading and parsing HTML code:
PIP - You can install packages using PIP. Install PIP
Python Requests: This package is essential for downloading HTML content. Install Python Requests
Python LXML: To effectively parse the HTML tree structure, you'll need Python LXML. Install Python LXML
We will focus on steps to scrape Zillow real estate listings with Python and LXML within the confines of a particular postal code: 02128.
The entire scraping procedure comprises the following sequential steps:

Here is a detailed breakdown of the scraping process:
Conduct a Search on Zillow: Initiate a search on Zillow by entering the specific postal code, in this case, 02128.
Retrieve the Search Results URL: The resulting URL where search results are displayed will typically follow a structure like this: "https://www.zillow.com/homes/02128_rb/."
Download HTML Code with Python Requests: Utilize Python Requests to fetch the HTML code of the webpage at the specified URL. This step involves making an HTTP request to obtain the page's content.
Parse the Page through LXML: Parse the downloaded HTML code using the Python LXML library, allowing for the structured extraction of relevant data from the webpage.
Export Extracted Data to a CSV File: The extracted data is organized and then exported to a CSV (Comma-Separated Values) file, which provides an accessible format for further analysis and use.
To set up BeautifulSoup, you can streamline the installation of necessary libraries by creating a "requirements.txt" file. This file contains a comprehensive list of the required libraries. You can then execute the installation process using the command "pip install -r requirements.txt.

Similar to numerous websites, Zillow employs CAPTCHAs as a security measure. Therefore, when utilizing the request.get(URL) function; it's essential to include headers in the request for proper functionality. Here's an example:

When creating variables for looping through URLs, the most straightforward approach is practical. For instance, if you intend to extract data from five pages, you can create five distinct soup variables and assign them unique titles, as demonstrated in the following example:

Zillow data scraper can perform some formatting tasks to enhance the readability of the extracted data, such as:
Converting columns.
Rearranging columns.
Eliminating null rows.


Please don't hesitate to contact iWeb Data Scraping for in-depth information! Whether you seek web scraping service or mobile app data scraping, we are here to help you. Contact us today to discuss your needs and see how our data scraping solutions can offer you efficiency and dependability.