855K
AMAZON REVIEWS
See how iWeb Data Scraping used Amazon data scraping to decode BOKA’s oral care strategy — pricing, 855K reviews, and seller distribution insights.
If you make decisions about pricing, assortment, distribution, or competitive positioning on Amazon, this case study is written for you. It is built specifically for:
If your role touches any of the above, the rest of this page shows exactly how iWeb Data Scraping delivers the numbers behind those decisions — and how you can request a working sample to evaluate the output yourself.
When an oral care brand like BOKA competes on Amazon, success is never the result of a single product going viral. It is the outcome of an entire catalog working as a coordinated system — priced, positioned, reviewed, and distributed with intent. The challenge for competing brands, buyers, and category managers is simple: that system is almost invisible from the outside. Prices, reviews, seller information, and ad placements are scattered across dozens of pages and change by the minute.
This Amazon data scraping case study shows how iWeb Data Scraping converted thousands of fragmented Amazon listings into one clean, structured dataset — and how that dataset revealed exactly how BOKA built a category-defining position in oral care. The analysis surfaced the brand’s pricing ladder, its review-volume moat, its seller distribution model, and its sponsored ad strategy. More importantly, it produced a repeatable model: any brand can use the same web scraping approach to benchmark competitors, refine pricing, and protect market share with evidence instead of guesswork.
Most brands already suspect what they need to know about a competitor. They rarely have the evidence to act on it. Amazon product pages publicly display price, reviews, ratings, sellers, and ad indicators, but that information is fragmented across thousands of URLs, refreshes by the minute, and is actively defended against automated collection.
Anyone who has tried to build a competitor dataset by hand knows the friction. Prices shift across regions and thousands of zip codes. Listings appear, sell out, and disappear without notice. Raw HTML is messy and inconsistent from one page template to the next. A scraper that worked perfectly yesterday can break overnight after a quiet layout change, and nobody notices until the numbers are already wrong.
The cost of this is not only wasted time. Decisions built on stale or incomplete numbers — a price change, a distribution audit, a new product launch, an investor pitch — carry real financial risk. Reliable Amazon data scraping exists precisely to remove that risk. It replaces best guesses with a verified ground truth that refreshes on a schedule the business controls, so the picture is never out of date when a decision has to be made.
Most teams attempt some version of retail data collection in-house before partnering with a specialist. The comparison below sets out where the practical differences land:
| Capability | Building it In-House | iWeb Data Scraping |
|---|---|---|
| Setup time | 4–12 weeks of engineering | 48–72 hours to first dataset |
| Anti-bot handling | Frequent blocks, IP bans, CAPTCHAs | Managed proxy & rotation infrastructure |
| Layout-change breakage | Silent failures, stale data | Monitored pipelines with auto-alerts |
| Data validation | Manual spot-checks, inconsistent | Automated dedup & validation rules |
| Refresh cadence | Whatever the team can keep up with | Hourly, daily, or custom — client-defined |
| Output format | Raw HTML or messy exports | Analysis-ready CSV, JSON, API, or DB |
| Total ownership cost | Engineering salaries + infrastructure | Predictable per-project pricing |
The cost calculation is almost never about scraper code. It is about the months of engineering time, the silent failures nobody catches, and the decisions made on stale data because the in-house pipeline broke last Thursday.
BOKA built its reputation by modernising preventive oral care — a clean-ingredient positioning that competes directly with both legacy toothpaste giants and emerging wellness challengers. On Amazon, that positioning shows up not as a sprawling catalog but as a focused, deeply-reviewed presence: a moderate range of products that each carry exceptional review weight and consistent customer trust.
For this case study, iWeb Data Scraping treated BOKA as a live example of a category-defining DTC brand operating at scale on Amazon and asked one straightforward question: if a competitor wanted to understand exactly how BOKA dominates oral care, what would the data have to show them? Answering that required far more than a product list. It required structured eCommerce data covering pricing, review depth across the full range, category mix, seller distribution, and the use of sponsored placements — the same signals a strategy team studies before entering or defending a category.
iWeb Data Scraping approached the project the way it approaches every retail intelligence engagement — define the questions first, then build the dataset to answer them. The team began by identifying every active BOKA listing on Amazon, then extracted a consistent set of fields from each one.
For every product, the Amazon data scraping pipeline captured the product title, ASIN, category, current price, star rating, total review count, seller name, fulfilment indicator, and whether the placement was organic or sponsored. Because Amazon prices, sellers, and ad placements move continuously, collection was scheduled to refresh on a fixed cadence rather than captured once — a single snapshot would have been outdated within hours.
Every record then passed through validation rules that flagged missing fields, impossible values, and duplicate listings before anything reached the final dataset. This is the step that separates dependable retail data from a noisy export. The output was not raw HTML or a pile of screenshots. It was a clean, analysis-ready table — the kind of product data extraction result a pricing analyst or category manager can open and use the same day it lands.
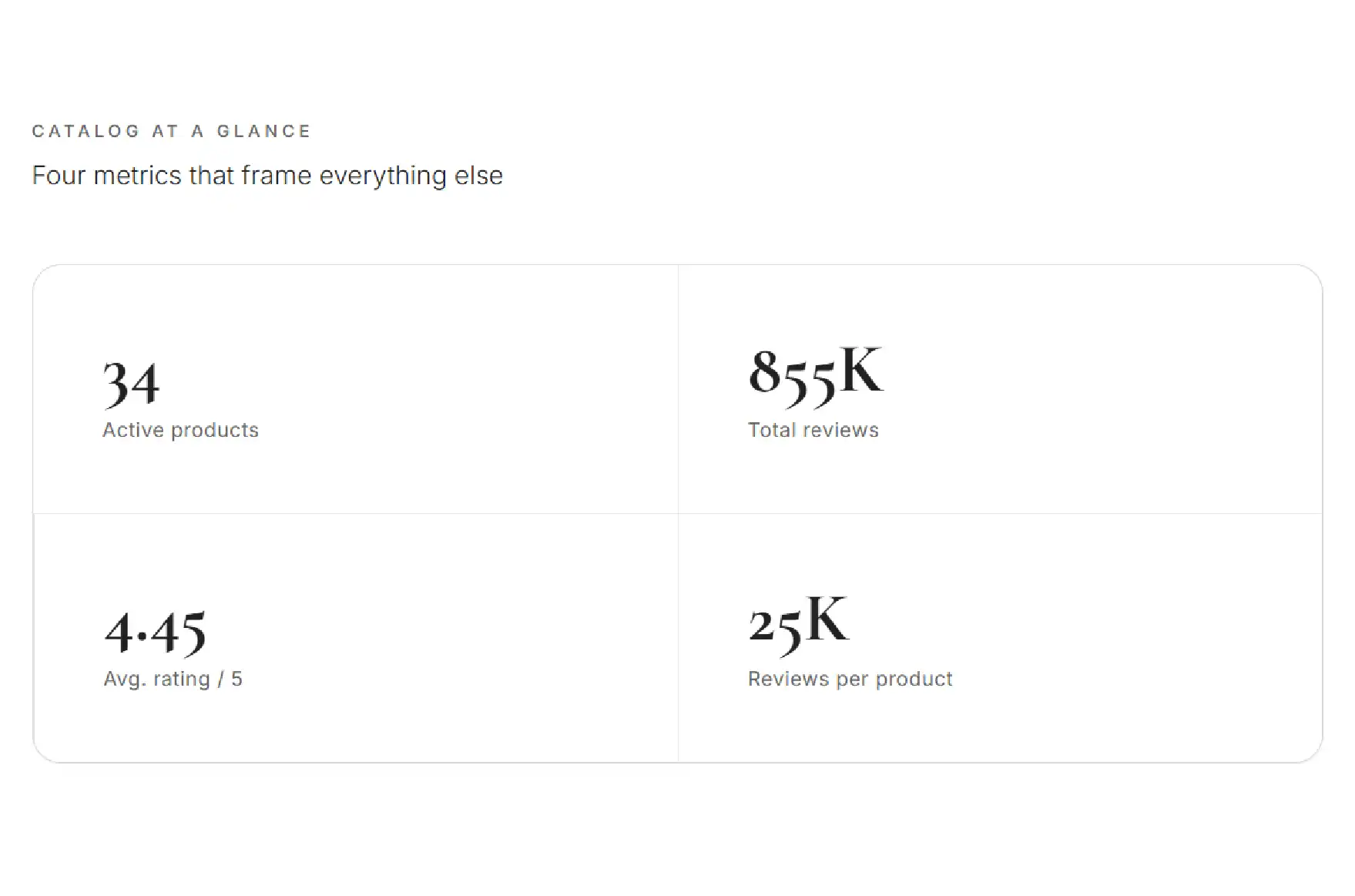
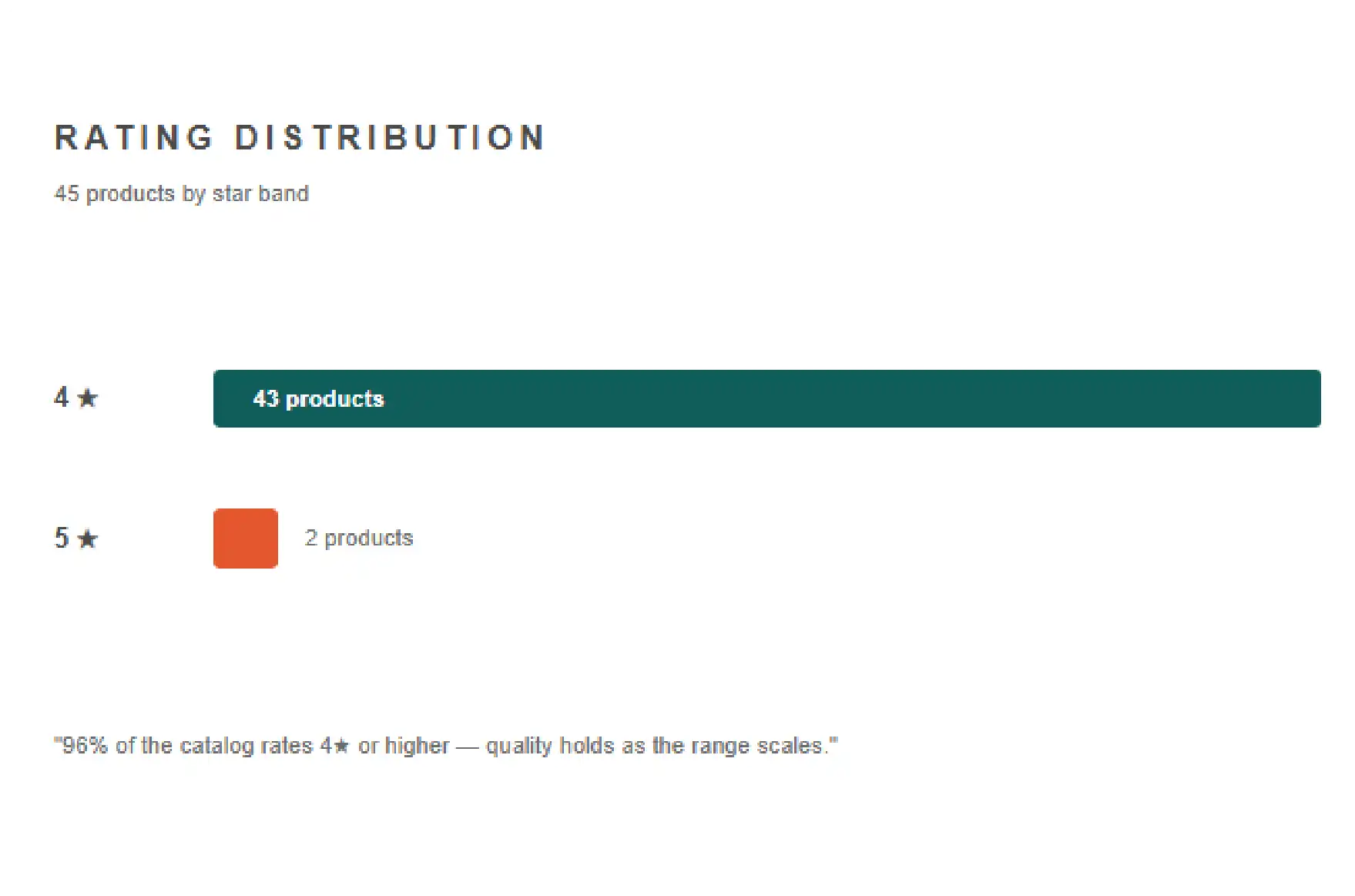
The first thing the data made clear is that BOKA does not just sell oral care products — it has built a review moat almost impossible for new competitors to scale. Across 34 active products on Amazon, the brand has accumulated approximately 855,000 customer reviews at an average rating of 4.45 out of 5.
That combination is the headline insight. Most brands chase either reach or reputation. BOKA holds both simultaneously, across a focused range, with a rating high enough to convert browsers and a review depth high enough to silence doubt. This is the kind of social-proof position that takes years of consistent product quality to build — and exactly the kind of signal Amazon data scraping makes measurable in a single pass.
| Core Metric | Value |
|---|---|
| Active products tracked | 34 |
| Total customer reviews | 855,000 |
| Average star rating | 4.45 / 5 |
| Catalog-wide review density | ~25,000 reviews per product |
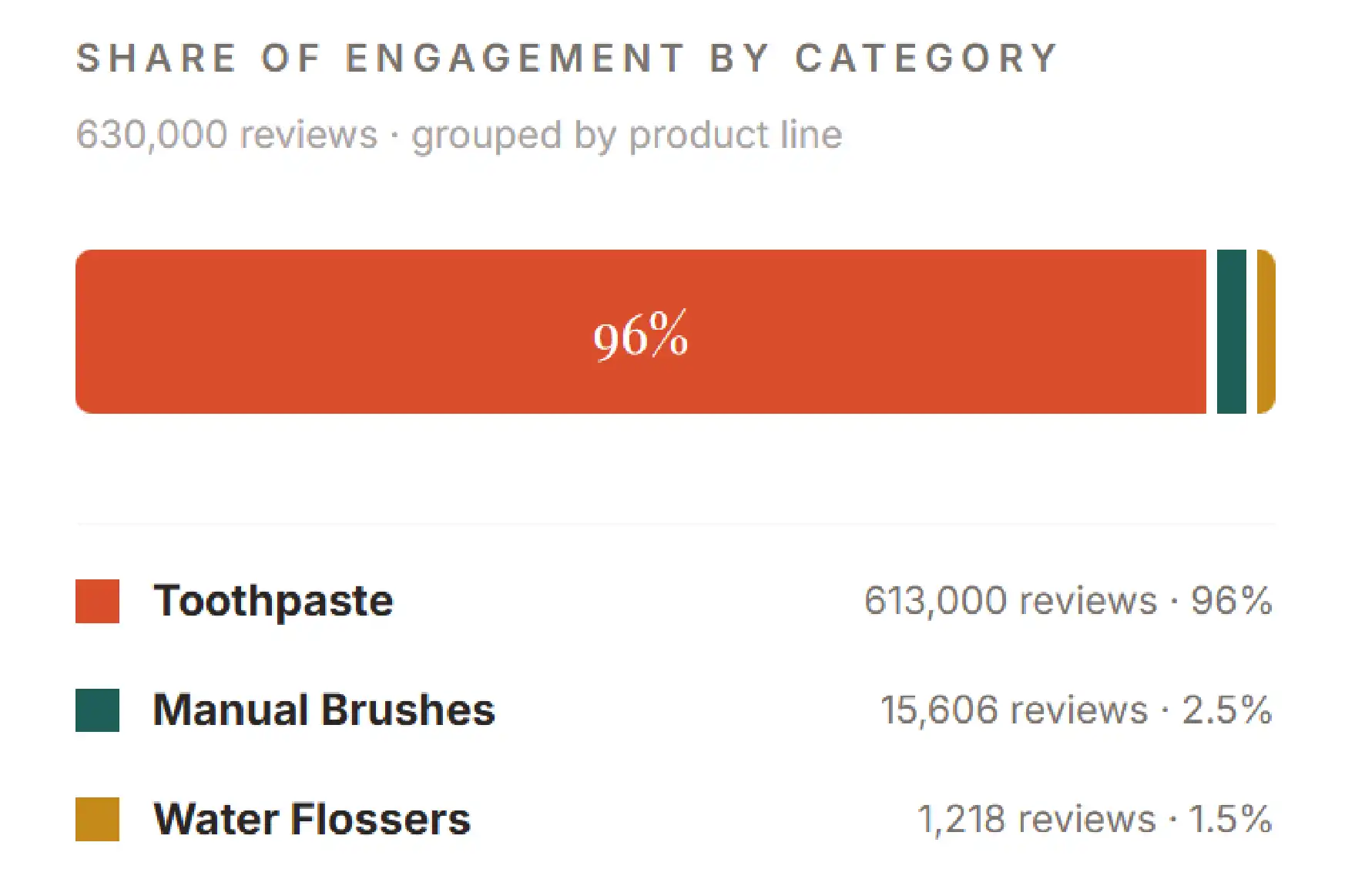
Within the catalog, one product carries the bulk of that social proof. A single BOKA toothpaste SKU has accumulated more than 613,000 reviews — a single listing carrying more social proof than most competing brands collect across their entire catalog. Manual brushes follow at roughly 15,606 reviews, and water flossers at around 1,218. The distribution is heavily top-loaded, with one hero anchoring the brand’s credibility on Amazon.
Review scraping at the individual SKU level surfaces exactly this kind of pattern — the listing a competitor would need to study, target, or out-position first. Without product-level data extraction, an anchor SKU like this stays hidden inside a category average.
WANT TO SEE WHAT THIS LOOKS LIKE FOR YOUR CATEGORY?
Tell iWeb Data Scraping which brand or category you want benchmarked. We will scope it and send a short sample within 48 hours — visit iwebdatascraping.com or email info@iwebdatascraping.com.
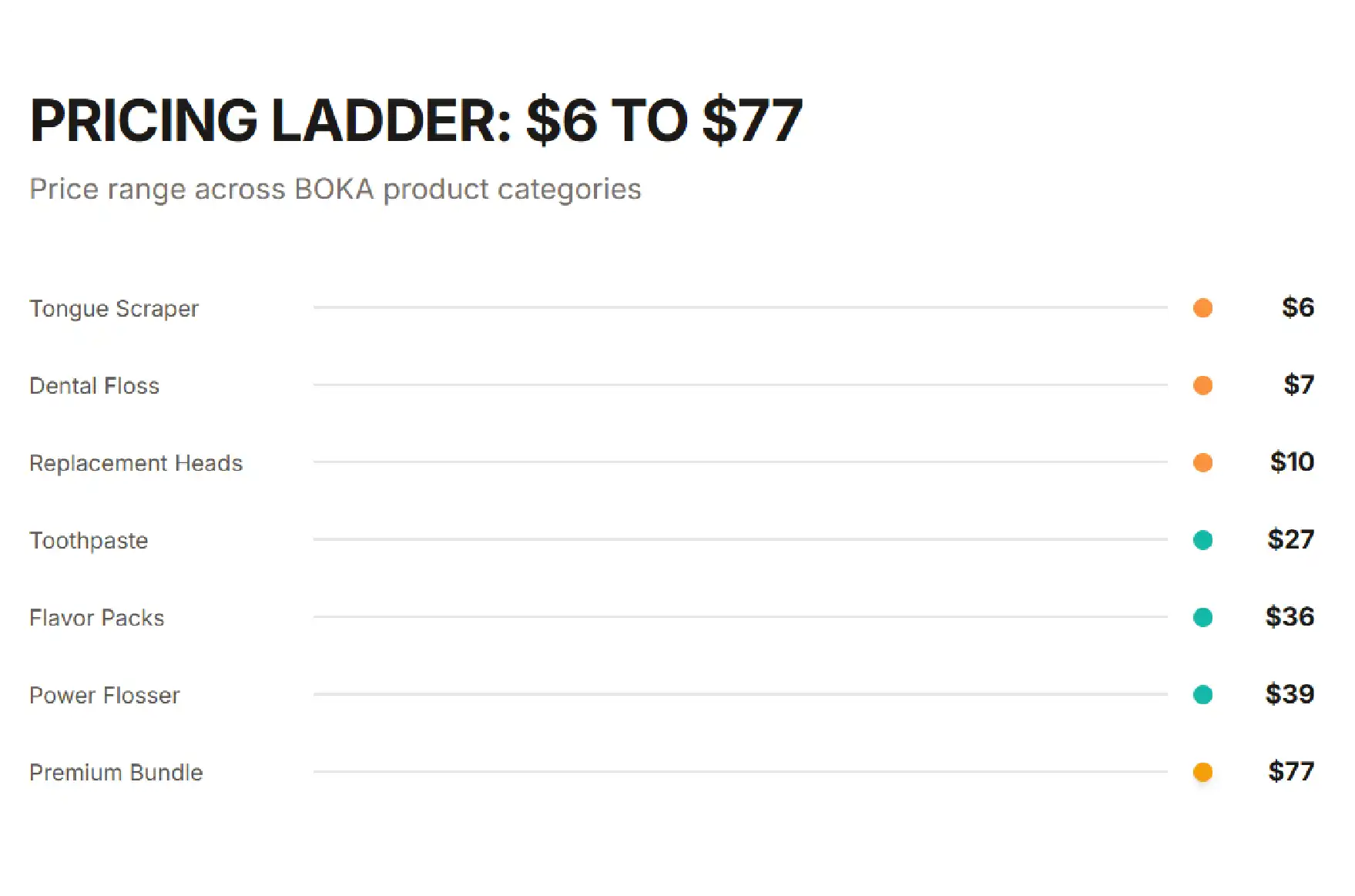
The third finding explained how BOKA turns a small first purchase into a much larger one. The catalog spans a deliberate three-tier price ladder, each tier playing a distinct strategic role.
| Tier | Price | Role |
|---|---|---|
| Acquisition | $6 – $10 | Tongue scrapers ($6), dental floss ($7), replacement heads ($10) — low-friction items that drive the first purchase and pull shoppers into the BOKA ecosystem. |
| Core | $24 – $39 | Toothpaste (~$27 average) and power flossers (~$39 average) — the everyday revenue engine and the brand’s biggest margin contributors. |
| Premium | $36 – $77 | Specialised flavour packs ($36) and premium toothpaste bundles ($77) — maximise Average Order Value among loyal buyers. |
Read alongside the product mix, that spread reveals a deliberate funnel. A $6 tongue scraper or $7 floss costs almost nothing to try, builds trust, and routes the shopper into the wider BOKA range. Mid-tier toothpaste and power flossers then carry the day-to-day revenue and margin. Premium bundles at $77 — more than ten times the entry price — pull average order value sharply upward among repeat buyers. Competitor price monitoring through Amazon data scraping is what makes a pattern like this visible — and, crucially, repeatable for any brand willing to study it.
STRATEGIC TAKEAWAY
$6 entry products acquire the customer. $77 bundles monetise them later. The same shopper, captured at the door, monetised at the back of the funnel.
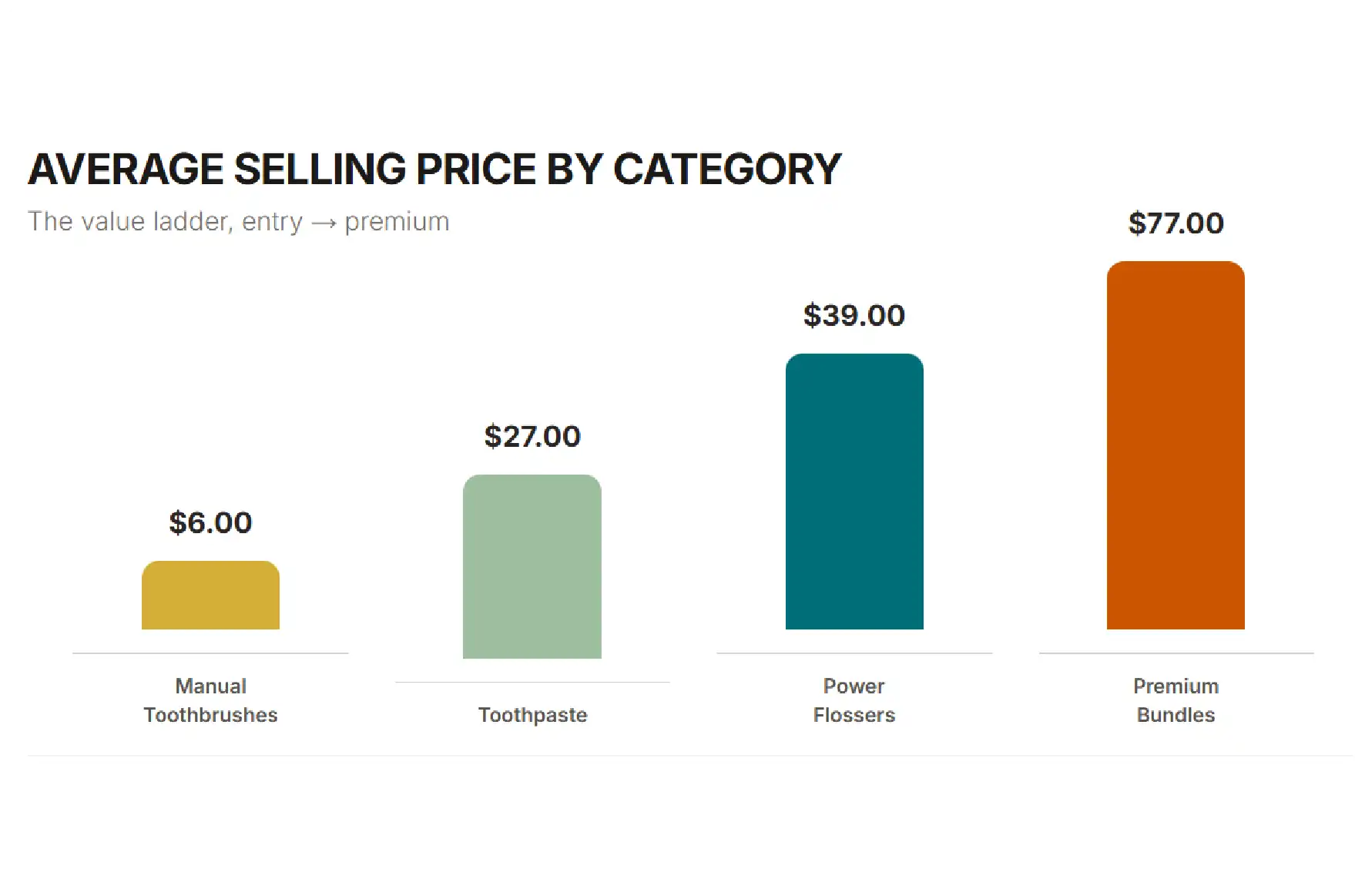
Looking beyond individual SKUs, average prices vary meaningfully across BOKA’s product categories — a clear signal of where the brand prices for volume and where it prices for margin.
| Category | Average Price | Role |
|---|---|---|
| Manual toothbrushes | $6 | Volume floor |
| Toothpaste | $27 | Core revenue |
| Power flossers | $39 | Margin driver |
| Premium bundles | $77 | AOV ceiling |
Power flossers at an average of $39 are doing significant strategic work — they are category leaders in BOKA’s range, command higher margins than basics, and anchor the mid-premium tier. A competitor reading this data would immediately understand which categories BOKA defends most aggressively and which serve as low-friction entry products.
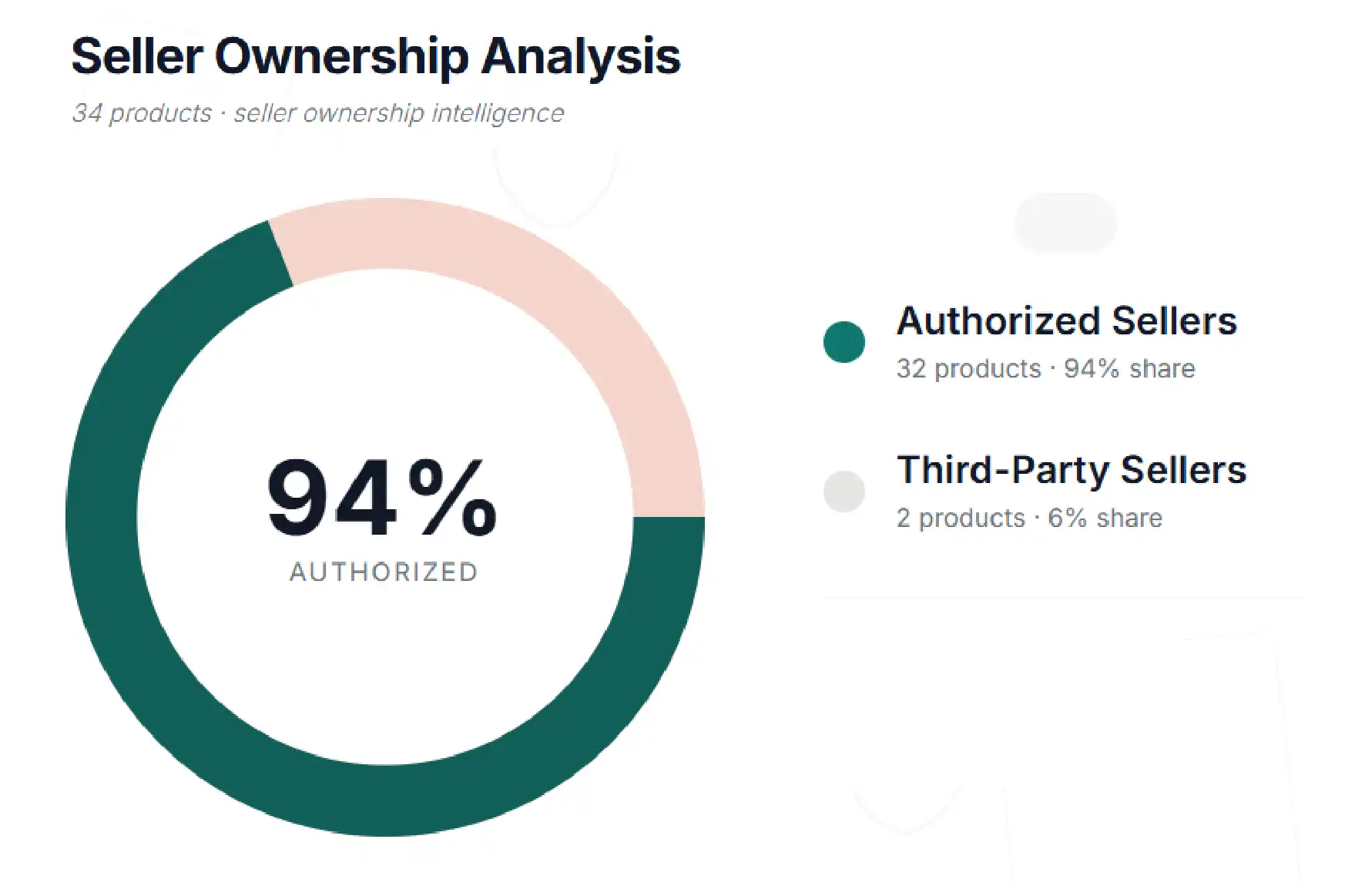
The fifth finding looked at who is actually selling BOKA on Amazon — and the answer is unusually disciplined. Of the 34 analysed products, BOKA LLC directly manages 32 listings as the primary authorised seller. That is one of the strongest brand-protection setups visible in the marketplace.
The strategic value of this is enormous. By centralising distribution, BOKA prevents the price erosion, counterfeit listings, and inconsistent customer experience that often plague brands when third-party sellers flood the Buy Box. Most products sit around a $24 average per seller, while a few authorised sellers push the average up to $77 on premium bundles — consistent pricing across the catalog, no race to the bottom. Without seller-level data extraction, a moat like this is completely invisible from outside the Amazon ecosystem.
THE COMPETITIVE REALITY
Your competitors are very likely already pulling these signals weekly. Every week you wait is another week they price, stock, and launch with better information than you do.
The sixth finding tested how BOKA uses paid placement on top of its organic strength. Nine products in the tracked catalog were currently running Amazon Sponsored Ads. The pattern was deliberate, not opportunistic.
Sponsored flossers — priced at the $39 margin sweet spot — dominated the ad spend, and almost every promoted product carried a 4-star-or-higher rating. BOKA is not using ads to prop up weak products. It is amplifying products that already convert, channelling paid spend toward listings where the conversion math already works in its favour. That is the exact opposite of brands that spend ad dollars trying to rescue underperforming SKUs — and a pattern only structured Amazon data scraping can reveal at a glance.
To make the deliverable concrete, the extract below illustrates the kind of structured dataset an Amazon data scraping engagement produces. Each row is one product record, and every field is analysis-ready the moment it is exported.
| ASIN | Product Name | Category | Price | Rating | Reviews | Seller / Placement |
|---|---|---|---|---|---|---|
| B0XXBOKA01 | Whitening Toothpaste | Toothpaste | $13.99 | 4.6 | 613,712 | BOKA LLC · Organic |
| B0XXBOKA02 | Manual Toothbrush 2pk | Brushes | $5.99 | 4.4 | 15,606 | BOKA LLC · Organic |
| B0XXBOKA03 | Tongue Scraper | Accessories | $5.99 | 4.5 | 9,840 | BOKA LLC · Organic |
| B0XXBOKA04 | Power Flosser | Flossers | $39.00 | 4.3 | 3,210 | BOKA LLC · Sponsored |
| B0XXBOKA05 | Water Flosser | Flossers | $59.00 | 4.2 | 1,218 | BOKA LLC · Organic |
| B0XXBOKA06 | Toothpaste Flavor Pack (4) | Bundles | $36.00 | 4.5 | 2,140 | BOKA LLC · Sponsored |
| B0XXBOKA07 | Premium Toothpaste Bundle | Bundles | $77.00 | 4.6 | 820 | BOKA LLC · Organic |
In a live engagement, this table refreshes on a defined schedule, includes historical price and seller columns for trend analysis, and feeds directly into dashboards, pricing models, or automated alerts when a new seller enters the listing or price drops below a threshold. The point is simple: the deliverable is never a screenshot or a messy export — it is clean, validated eCommerce data a team can act on immediately. (Values shown here are illustrative samples; a live project reflects current marketplace data.)
A dataset only matters if it changes a decision, and the BOKA analysis shows precisely how. A competing oral care brand could use the same Amazon data scraping output to benchmark its own pricing against BOKA’s $6-to-$77 ladder and reposition with confidence. A category manager could see that just one toothpaste SKU carries roughly 70% of the brand’s social proof and concentrate product development where review velocity is genuinely achievable.
A pricing team could track the catalog-wide $24 average over time and detect the exact moment BOKA launches a new SKU or runs a promotion. A brand-protection team could replicate BOKA’s centralised-seller approach to defend their own Buy Box. An investor running due diligence could verify — with evidence rather than assumption — that BOKA’s growth rests on a defensible review moat plus disciplined distribution rather than discounting. In every case the value is identical: replacing opinion with a defensible number.
iWeb Data Scraping specializes in turning fragmented retail pages into reliable, structured datasets. The company’s Amazon data scraping services cover product data extraction, competitor price monitoring, review and sentiment analysis, seller and Buy-Box tracking, and sponsored-ad monitoring across thousands of listings and multiple marketplaces.
Every dataset is validated, deduplicated, and delivered in the format a client’s systems already use — CSV, JSON, a database load, or a direct API feed. Collection runs on a schedule the client controls, so the data never goes stale, and every pipeline is monitored so that a layout change on the retailer’s side does not quietly corrupt the feed. The brands that win on Amazon are not guessing. They are reading the shelf with better data than their competitors — and that is exactly what iWeb Data Scraping delivers.
See exactly what an iWeb Data Scraping deliverable looks like before you commit. CSV format. Live fields. No call required.
Email info@iwebdatascraping.com with the subject line “Sample Dataset” and tell us the brand or category to analyze.
Start a projectAmazon data scraping is the automated collection of public product information from Amazon — including prices, reviews, ratings, sellers, availability, and ad placements — and its conversion into a clean, structured dataset that businesses can analyze. iWeb Data Scraping delivers this data validated and ready to use.
Yes. As this case study demonstrates, structured Amazon data reveals a competitor’s pricing ladder, category concentration, hero products, seller distribution, and sponsored ad strategy — the exact signals a brand needs to benchmark and respond effectively.
Most engagements deliver an initial dataset within 48 to 72 hours of scope confirmation, followed by scheduled refreshes at a cadence the client controls.
Yes. Seller name, fulfilment, and Buy-Box winner are standard fields in iWeb Data Scraping’s Amazon feed, which is what makes brand-protection use cases like BOKA’s centralised-seller model possible to monitor in the first place.
Yes. Sponsored versus organic placement is captured for every listing, so competitor ad strategy is visible in the same dataset as pricing and reviews.
Share the brands, categories, or marketplaces you want to track. iWeb Data Scraping scopes the required fields and refresh cadence, then delivers a validated dataset you can act on immediately. The fastest path to evaluate the output is to request the free sample dataset linked above.